







 在分类问题中,交叉熵损失函数比MSE更优,因为它能更好地反映模型预测的准确性。通过示例比较,展示了交叉熵如何更好地评估模型性能,尤其是在Softmax后的非凸优化问题上,它提供了更好的收敛特性。文章还介绍了softmax函数的作用,用于将预测值转换为概率分布。
在分类问题中,交叉熵损失函数比MSE更优,因为它能更好地反映模型预测的准确性。通过示例比较,展示了交叉熵如何更好地评估模型性能,尤其是在Softmax后的非凸优化问题上,它提供了更好的收敛特性。文章还介绍了softmax函数的作用,用于将预测值转换为概率分布。
我们一般在回归问题中,损失函数经常会用到MSE(mean squared error),而在分类问题中,我们经常会用到CrossEntropy。我们经常把它与softmax一起用,因为我们用交叉熵计算出来的值不一定是在[0,1]之间,我们通常用softmax归一到0-1之间,这样我们可以进行物体的分类。
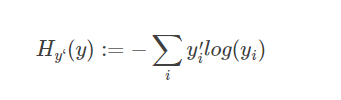
这里,yi是预测值,y’i是label
我们为什么要使用交叉熵呢?
比如我们给你两组数据
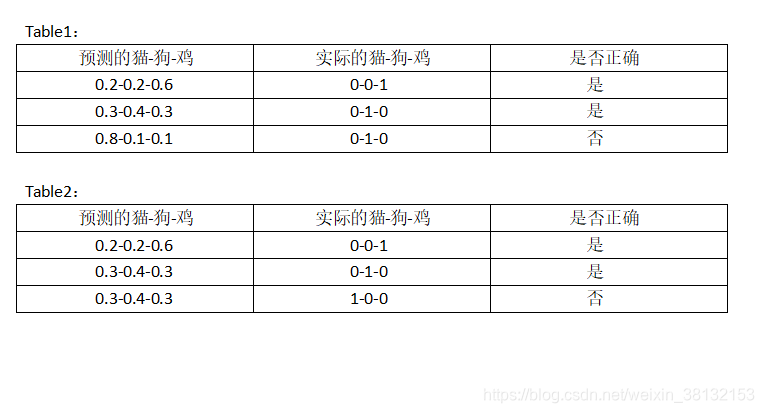
那么我们正常计算table1,2的准确率都是33.3%,但是我们仔细观察,table2的明显要比table1要好,因为0.8-0.1-0.1估计错的概率明显要比
0.3-0.4-0.3估计错误的概率要大,那么我们怎么才能看出哪一个模型效果更好呢?
我们用crossentropy来计算loss:
table1:第一项:- ((ln0.2)*0+(ln0.2)*0+(ln0.6)*1) = -ln0.6
同理,table1:loss = -(ln0.6+ln0.4+ln0.1)/3 = 1.243
table2:loss = -(ln0.6+0.4+0.3) = 0.877
那么我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1411
1411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









