







论文地址:https://arxiv.org/abs/1612.03144
一、图像金字塔
顾名思义,就是对源图像的尺寸进行放大或者缩小变换,通过向下采样,金字塔的底部是高分辨率,而顶部是低分辨率,层级越高,则图像越小,分辨率越低。
主要解决图像分析尺度问题的,构造特征时:可以适应尺度变化,增加特征维度,构造高维特征。
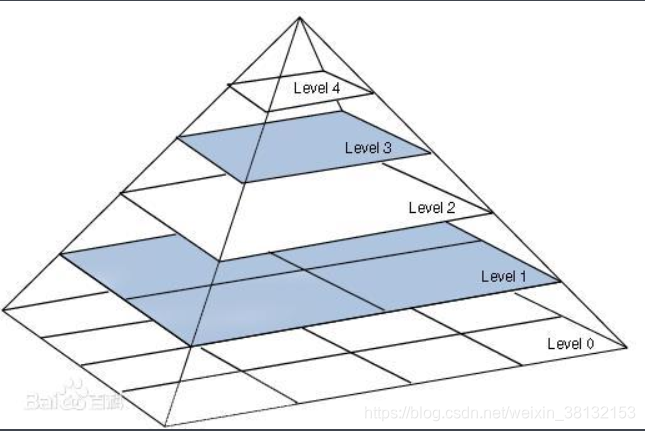
第k层通过平滑,下采样获得第k+1层。一张图片通过下采样上采样可以获得很多张图片,对于人眼而言,一张二维图片好像从近到远,增加了一个维度,可以提供更多的信息。
二、浅层特征和深层特征
复杂图形,往往由一些基本结构组成,一个图可以通过用若干种正交的edges来线性表示。最基本的组成单位是:边缘线。即浅层特征就是一些由edge构成的细节,或者一些小物体。
深层特征就是找到make sense的小patch再将其进行combine,就得到了上一层的feature

由edge构成了一些细节或者一些小物体,这些细节再向上形成了更高的语义信息,比如物体、人脸等
三、特征金字塔FPN

图像的目标检测中,具有不同大小的目标,简单的目标可以利用浅层特征区分(比如鸟),复杂的目标需要利用深层特征进行区分(比如牛)
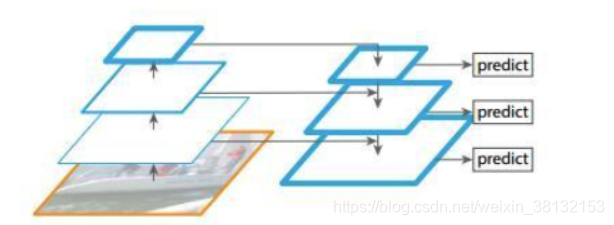
我们可以利用up-bottom最下层来预测鸟,用up-bottom最上层来预测牛。
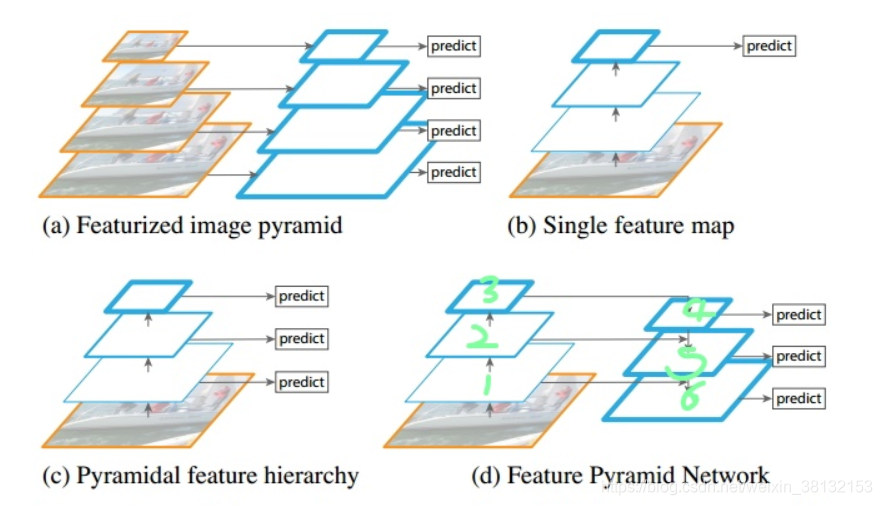
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征,再对每一层进行预测。这种方法的缺点在于增加了时间成本。
(b)浅层的网络关注于细节特征,高层的网络更关注于深层语义信息,而高层的语义信息能够帮助我们准确的检测出目标,比如VGG、ResNet、Inception,利用深度网络的最后一层特征来进行分类。但是对于小物体也就是细节的检测并不是很好
(c)SSD尝试使用CNN金字塔形的层级特征。即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。但是SSDSSD放弃了重利用更高分辨率的feature map
(d)特征金字塔FPN,我们对输入图片下采样,对Layer4上面的特征就行上采样,使得它们具有相应的尺寸,浅层layer通过1*1的卷积进行降维,融合具有高分辨率的浅层layer和具有丰富语义信息的深层layer,对应元素相加。将获得的结果输入到Layer5中去。低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,这样我们就构建了一个更深的特征金字塔,融合了更多特征信息,并在不同的特征进行输出。
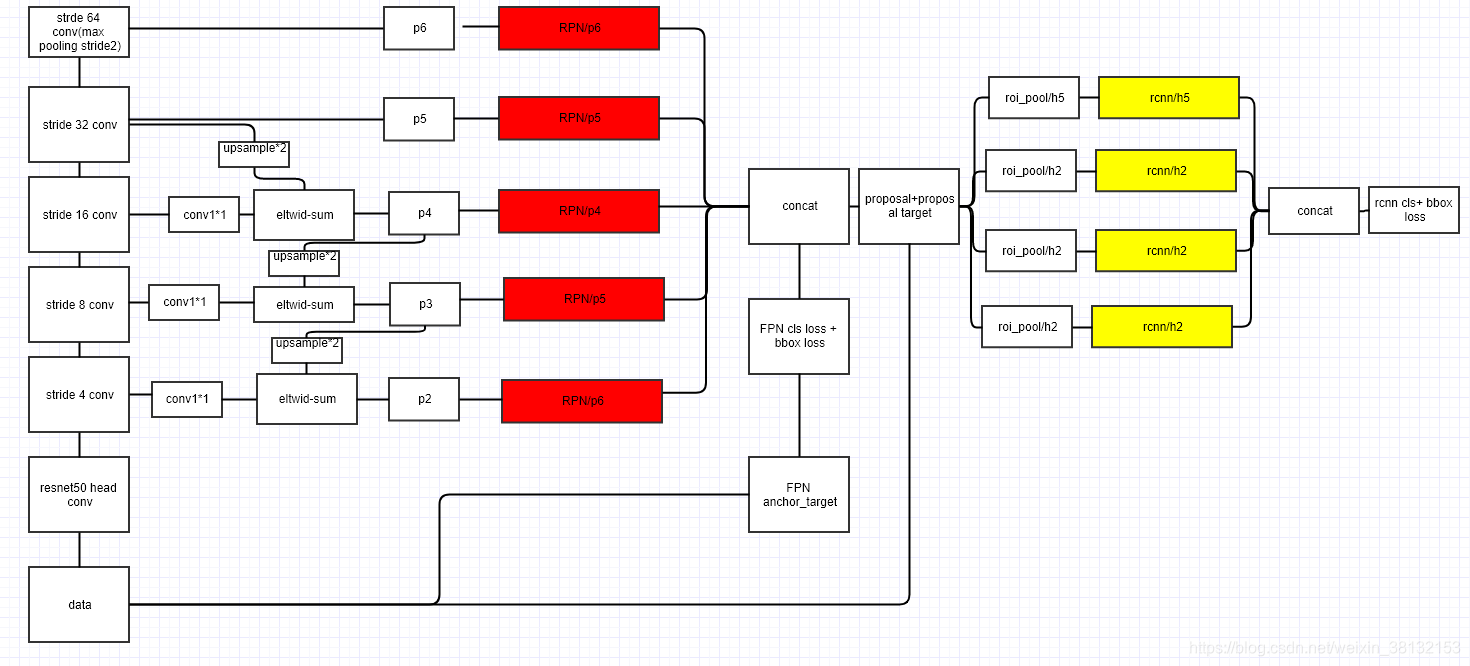
Q1:不同深度的feature map为什么可以经过upsample后直接相加?
答:作者解释说这个原因在于我们做了end-to-end的training,因为不同层的参数不是固定的,不同层同时给监督做end-to-end training,所以相加训练出来的东西能够更有效地融合浅层和深层的信息。














 8272
8272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









