









FLink-16-Flink程序分布式部署运行
Flink程序分布式部署运行
1.Job执行流程
- 1.client 的流程
- client --> 根据算子transformation代码,生成StreamGraph,
- 然后判断是否能chain的条件,将可以chain起来的“点”,chain成OperatorChain,得到JobGraph.
- 提交JobGraph给集群中的jobmanager
- 2.jobmanager的流程
- jobmanager收到JobGraph后,将其在转为ExecutionGraph(完美体现各个点的并行度)
- 然后再根据图,来申请所需的slot操作,并发送对应的task。

整个的执行流程如下图:


2.flink standalone集群
- session集群,flink中的一个独有的概念。一个session集群,就是可以帮助用户同时运行多个job的集群,我们可以向session集群,反复提交job。
- Flink 程序中如果要访问到 hdfs,则需要添加 2 个 jar 包到 flink 的 lib 目录中
- flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
- commons-cli-1.4.jar
Standalone session 集群模式的缺点:
- 资源利用弹性不够(资源总量是定死的;job 退出后也不能立刻回收资源)
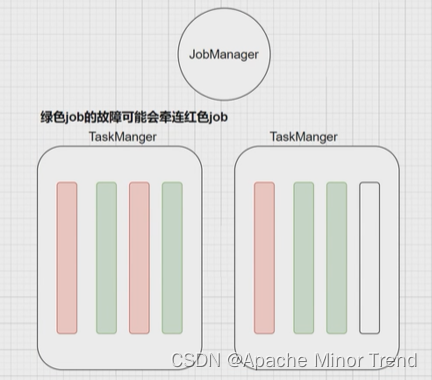
- 资源隔离度不够(session集群,所有 job 共享集群的资源,一个任务导致taskManager宕机了,其他的任务也会受到影响)
- 所有 job 共用一个 jobmanager,负载过大
通过命令 bin/flink run 提交 job
- 提交 standalone 模式的 job
- -c 主类名
- -p 并行度
- -s 从指定 savepoint 恢复
bin/flink run -t remote \ -c cn.doitedu.flink.java.demos._28_ToleranceSideToSideTest \ -p 5 \ -s hdfs://doit01:8020/eos_savepoint1/savepoint-5f1bc3-dde7a8627fff \ /root/flink_course-1.0.jar
- 触发 standalone 模式 job 做 savepoint
- -d : detach 模式,客户端提交完 job 即退出
- -t remote : 表示 job 是 standalone 运行模式
bin/flink savepoint -t remote 5f1bc357bfd1e686e34b6cfce6d0cda9 hdfs://doit01:8020/eos_savepoint1
3.flink on yarn
- yarn、k8s(docker)、vmware三者的比较
- yarn 提供的是yarn container,最轻量级的,它里面只能运行进程。
- k8s(docker)提供的是虚拟机,轻量级虚拟机,它里面能运行操作系统(简化版操作系统)
- vmware 提供的是虚拟机,重量级虚拟机,它里面能安装运行完整功能的操作系统,提供完整的硬件模拟。
1.yarn 模式运行时示意图
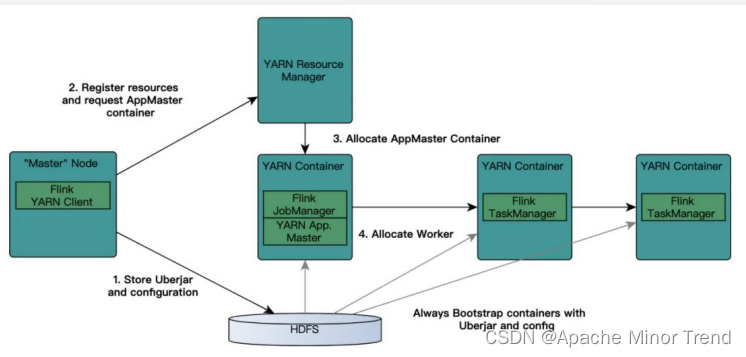
- 基础逻辑
- flink on yarn,本质上就是去 yarn 集群上申请容器,来运行 flink 的 jobmanager+taskmanager 集群
- flink 的 job,是 flink 集群内部的概念,它对 yarn 是不可见的
2.Flink on yarn 的三种模式
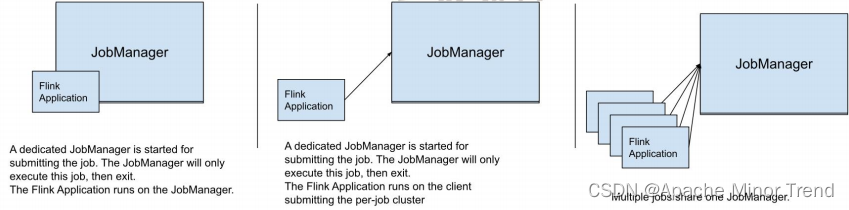
- Flink 程序可以运行为以下 3 中模式:
- Application Mode【生产中建议使用的模式】
每个 job 独享一个集群,job 退出集群则退出,用户类的 main 方法在集群上运行 - Per-Job Mode
每个 job 独享一个集群,job 退出集群则退出,用户类的 main 方法在 client 端运行; (大 job,运行时长很长,比较合适;因为每起一个 job,都要去向 yarn 申请容器启动 jm,tm,比较耗 时) - Session Mode
多个 job 共享同一个集群<jobmanager/taskmanager>、job 退出集群也不会退出,用户类的 main 方法在 client 端运行;
(需要频繁提交大量小 job 的场景比较适用;因为每次提交一个新 job 的时候,不需要去向 yarn 注册 应用)
- Application Mode【生产中建议使用的模式】
- 上述 3 种模式的区别点在:
- 集群的生命周期和资源的隔离保证
- 用户类的 main 方法是运行在 client 端,还是在集群端。
- yarn中的资源调度策略:
- capacity scheduler
- 同一个队列中,各个application是使用fifo策略
- fair scheduler
- capacity scheduler
3.yarn session模式提交任务
-
1.12之后的flink版本,on yarn的session模式,启动一个session cluster时,不需要指定taskmanager的个数了,资源利用更有弹性了,完全实现了资源动态弹性利用:
- 1.集群运行的job,需要多少资源,就动态申请多少资源(taskmanager)
- 2.集群运行的job被cancel,那么占用的yarn资源也会随之而释放。
- 3.集群的jobmanager会一直存在的,这个资源不会被释放。
-
Yarn-Session 模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。 适合执行时间短,频繁执行的短任务,集群中的所有作业 只有一个 JobManager,另外,Job 被随 机分配给 TaskManager
-
特点: Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远 保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后, 释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适 合规模小执行时间短的作业。
-
flink提交任务以后,会向yarn申请内存,分配的内存是配置中设置的参数:yarn.scheduler.minimum-allocation-mb的倍数,比如:申请了1050mb内存,参数设置的为1024mb,最终yarn会给分配1024*2的内存。
-
yarn基础概念汇总:
- 所谓的flink集群,就是一个分布式程序,这个分布式程序,现在运行在了yarn上,那么这个程序对于yarn来说,就是一个application。
- 如果yarn上运行是一个mr程序,对于yarn来说,是一个application,这个application中具体的进程是:MrApplicationMaster,yarn child
- 如果yarn上运行是一个spark程序,对于yarn来说,也是一个application,这个application中具体的进程是:AppMaster,CoarseGrainYarnExecutor
- 如果yarn上运行是一个flink程序,对于yarn来说,也是一个application,这个application中具体的进程是:JobManager,TaskManager.
1.具体操作命令:
(1) 先开辟资源启动 session 模式集群
- 老版本:
bin/yarn-session.sh -n 3 -jm 1024 -tm 1024
# -n --> 指定需要启动多少个 Taskmanager
- 新版本:
bin/yarn-session.sh -jm 1024 -tm 1024 -s 2 -m yarn-cluster -ynm hello -qu default
# -jm --> jobmanager memory
# -tm --> taskmanager memory
# -m yarn-cluster --> 集群模式(yarn 集群模式)
# -s --> 规定每个 taskmanager 上的 taskSlot 数(槽位数)
# -nm --> 自定义 appliction 名称
# -qu --> 指定要提交到的 yarn 队列
- 启动的服务进程 YarnSessionClusterEntrypoint(AppMaster,即 JobManager)
注意:此刻并没有 taskmanager,也就是说,taskmanager 是在后续提交 job 时根据资源需求动态申请 容器启动的;
(2) 向已运行的 session 模式集群提交 job
- 通过命令提交 job 到已运行的 yarn-session 集群
bin/flink run -d -yid application_1550579025929_62420 -p 4 -c cn.doitedu.flink.java.demos._28_ToleranceSideToSideTest /root/flink_course-1.0.jar
- 通过已运行 yarn-session 集群的 webui 上提交 job
- session 集群模式下的进程角色名称
- jobmanager 叫做 YarnSessionClusterEntrypoint
- taskmanager 叫做 YarnTaskExecutorRunner
- 客户端叫做 FlinkYarnSessionCli
- session 集群模式:更适用于有大量小的 job 需要频繁提交运行
4.yarn perJob模式提交任务
- perJob模式,申请容器启动flink集群以及提交job,是合二为一的。
- Yarn-Per-Job 模式:每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在客户端执行。 在 per-job 模式下,每个 Job 都有一个 JobManager,每个 TaskManager 只有单个 Job。
- 特点: 一个任务会对应一个 Job,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源,直到作 业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;
- 适合规模大长时间运行的作业。
- 提交命令
bin/flink run -m yarn-cluster -yjm 1024 -ynm sea -yqu default -ys 2 -ytm 1024 -p 4 -c cn.doit._16_TaskChainDemo /root/doit29_flink-1.0.jar
5.yarn application模式提交任务
- 提交命令
bin/flink run-application -t yarn-application \ -yjm 1024 -ynm sea -yqu default -ys 2 \ -ytm 1024 -p 4 \ -c cn.doitedu.flink.java.demos._27_KafkaSinkYarn /root/flink_course-1.0.jar
- application模式和perjob模式几乎一样,唯一不同点:用户类和main方法在哪里运行。
- application模式下,进程是:YarnApplicationClusterEntryPoint ,这个进程就具备jobmanager的功能和帮助运行用户类的main方法的功能。














 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









