







百天计划之23天,关于“AI量化投资,财富自由与个人成长”。
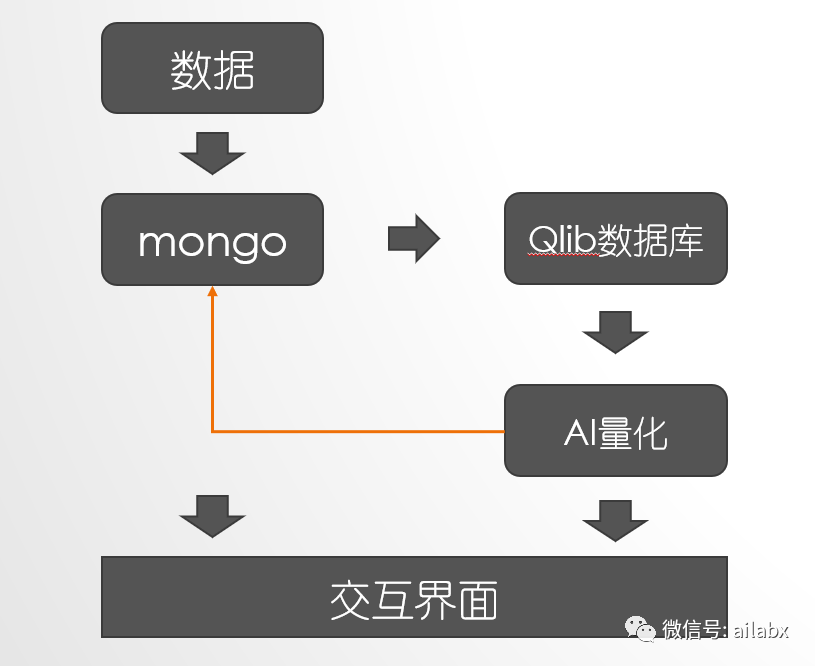
今天重点关注基于qlib的量化数据库,引入自有的数据源。
这是一个常见的需求。
qlib内置的数据源是来自网上,数据质量不高且不稳定,网络不好的时候下载不下来。
目前我选用的数据库是tushare,持久化的数据库是mongo。
这里有定时任务持续更新数据,同时更新的数据要同步更新qlib。
qlib的数据库是专门为AI量化定制的,可以多进程并行计算,在海量因子计算的时候有优势。
01 数据准备
qlib.tests.data.py GetData
DATASET_VERSION = "v2"
REMOTE_URL = "https://qlibpublic.blob.core.windows.net/data/default/stock_data"
QLIB_DATA_NAME = "{dataset_name}_{region}_{interval}_{qlib_version}.zip"
从微软的服务器上下载一个zip,然后解压。
支付A股,美股,按天和按分钟两种。
如果下载慢,可以直接自己拼一个url,在下载软件里把zip包下载自行解压也可以。
02 自动更新日频数据
手动执行yahoo脚本(一次)
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
定时任务执行(linux下的cron定时器):
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
这里核心代码是调用了yahoo query。
_resp = Ticker(symbol, asynchronous=False).history(interval=interval, start=start, end=end)
增量数据下载,正则化,而后使用增量dump:
# dump bin
_dump = DumpDataUpdate(
csv_path=self.normalize_dir,
qlib_dir=qlib_data_1d_dir,
exclude_fields="symbol,date",
max_workers=self.max_workers,
)
_dump.dump()
dump_bin一共有三种模式:
fire.Fire({"dump_all": DumpDataAll, "dump_fix": DumpDataFix, "dump_update": DumpDataUpdate})
创建模式:DumpDataAll,
修复模式:DumpDataFix,
更新模式:DumpDataUpdate。
03 从dump模式看数据准备
其实问题反而简单,我们可以不必看那些collector的代码,只知道我们需要把序列写到一个文件目录下的csv即可。
正则化只是把初始价格置为1,有点类似计算equity的模式。
python scripts/dump_bin.py dump_all ... --symbol_field_name symbol
python scripts/dump_bin.py dump_update ... --symbol_field_name symbol
python scripts/dump_bin.py dump_all --csv_path ~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor
财务数据PIT,也是读取“正则后”的csv文件夹:
python dump_pit.py dump --csv_path ~/.qlib/stock_data/source/pit_normalized --qlib_dir ~/.qlib/qlib_data/cn_data --interval quarterly
PIT原始csv:报告日期,报告期,字段值,字段名和symbol
date,period,value,field,symbol 2008-03-01,2007-12-31,0.3479,roeWa,sh600519 2012-03-23,2011-12-31,0.4039,roeWa,sh600519 2019-07-13,2019-06-30,0.0,roeWa,sh600519
PIT的正则化后,把报告期变成“年第X季度”,比如2011-12-31变成201104
date,period,value,field,symbol 2008-03-01,200704,0.3479,roeWa,sh600519 2012-03-23,201104,0.4039,roeWa,sh600519 2019-07-13,201902,0.0,roeWa,sh600519 2007-04-28,200701,0.090219,roeWa,sh600519
最终以“规范化处理“后的csv为准。
以上就是我们需要准备的csv格式。
04 从tushare下载数据到mongo
mongo用来存储金融序列非常方便,它不需要Schema,可以存储json。
下面是把茅台(600519.SH)的数据入库了,后续加上自动更新。
05 从mongo到csv并自动dump
从mongo下载并保存成csv,这个代码就不贴了:
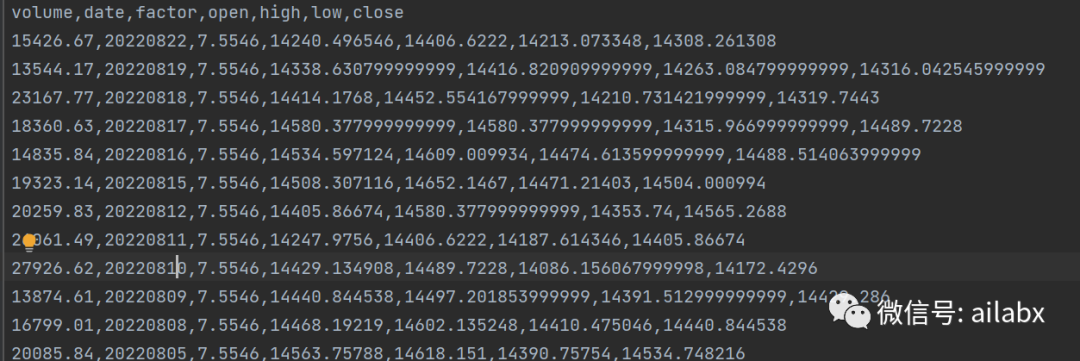
茅台最新的”复权价“超过1万4了!
dump_bin的代码:

这里我们可以不使用命令行,直接调用函数。
直接调用DumpDataAll与前述脚本的效果一致:
from common.scripts.dump_bin import DumpDataAll, DumpDataUpdate
from common.config import CN_CSVS, CN_DATA_TEST
# csv的文件路径以及qlib的目录
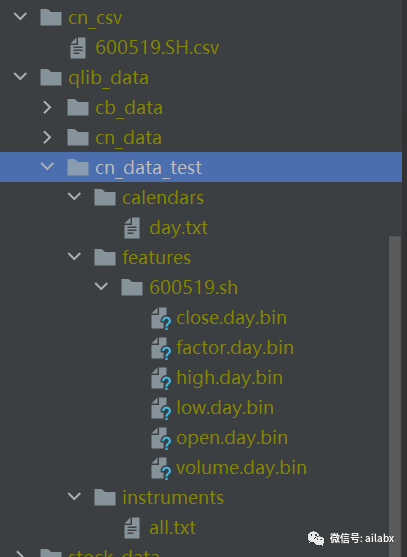
def dump_csv_to_bin():
dump = DumpDataAll(csv_path=CN_CSVS, qlib_dir=CN_DATA_TEST)
dump.dump()
小结:
1、qlib自带的crawler,直接基于网页的采集脚本,一是网络可能不稳定,数据质量无法保证;二是不易脚本不容易做成自动化部署。
2、基于mongo数据库与tushare数据源,我们设计了一个数据更新的逻辑
明天会继续完善pit财务数据的导入。
















 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











