







持续行动1期 47/100,“AI技术应用于量化投资研究”。
关于量化交易鼻祖西蒙斯的各种正史、野史来看,他出道时做基本面分析,亏了十年,后来改做高频量化,后又引入机器学习专家,进而成为王者。
如此反而简单,就是技术面的逻辑,都在价格里了,大家把价格里的“隐藏”信息挖出来,还不用处理各种财务面数据。另外这个模式就具备通用性了。移植到期货,期权,电子货币都相对容易。
找策略的角度,就是找到因子集合,然后加权也好,还是机器建模也罢形成策略;进一步寻找找更好的因子,配套更好的模型。
01 从因子到策略
所有策略,本质都是多因子策略。
因子分析是一种相关系数分析,因子分析与回测结果有没有正相关关系呢?因子如何优化,遗传算法自动发现因子——先有形式,再看逻辑的大数据挖掘。
这里可以用qlib框架来实战一样,就使用沪深300股票池,与市场benchmark正好可以对比。就使用价量因子,这样数据都是准备好的。
先从gdbt-alpha158这个基准开始,然后可以选出最有效的因子。去除无关的因子之后看效果,更换其他模型之后看效果等。
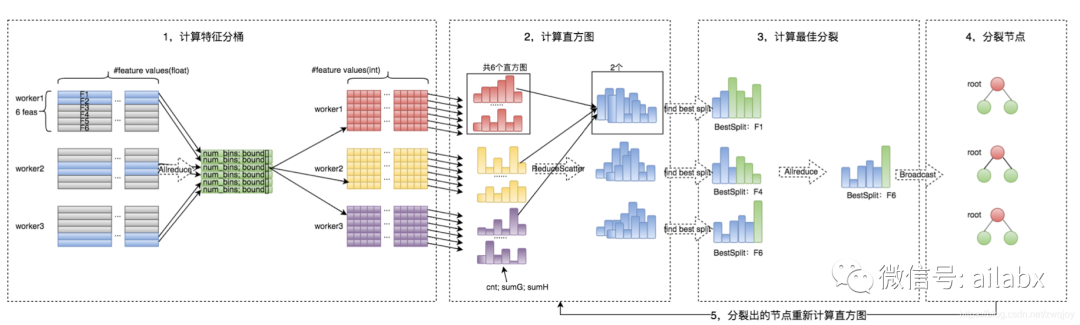
02 qlib的量化流程
初始化qlib:
加载数据集,包含内置的158个因子的预计算,总共需要2分多钟,所以搁到jupyte notebook是更合适的。
def load_dataset(config=None):
data_handler_config = {
"start_time": "2010-01-01",
"end_time": "2020-08-01",
"fit_start_time": "2008-01-01",
"fit_end_time": "2014-12-31",
"instruments": 'csi300',
}
config = {
"class": "DatasetH",
"module_path": "qlib.data.dataset",
"kwargs": {
"handler": {
"class": "Alpha158",
"module_path": "qlib.contrib.data.handler",
"kwargs": data_handler_config,
},
"segments": {
"train": ("2010-01-01", "2014-12-31"),
"valid": ("2015-01-01", "2016-12-31"),
"test": ("2017-01-01", "2020-08-01"),
},
},
}
ds = init_instance_by_config(config)
return ds

到此,300支股票的数据以及158个因子都准备好了。
加载模型:
def load_lightGBM():
from qlib.contrib.model.gbdt import LGBModel
config = {
"loss": "mse",
"colsample_bytree": 0.8879,
"learning_rate": 0.2,
"subsample": 0.8789,
"lambda_l1": 205.6999,
"lambda_l2": 580.9768,
"max_depth": 8,
"num_leaves": 210,
"num_threads": 20,
}
model = LGBModel(**config)
return model
因子集的IC值为0.039,还可以,一般0.05就认为是显著,0.1就是比较好的。

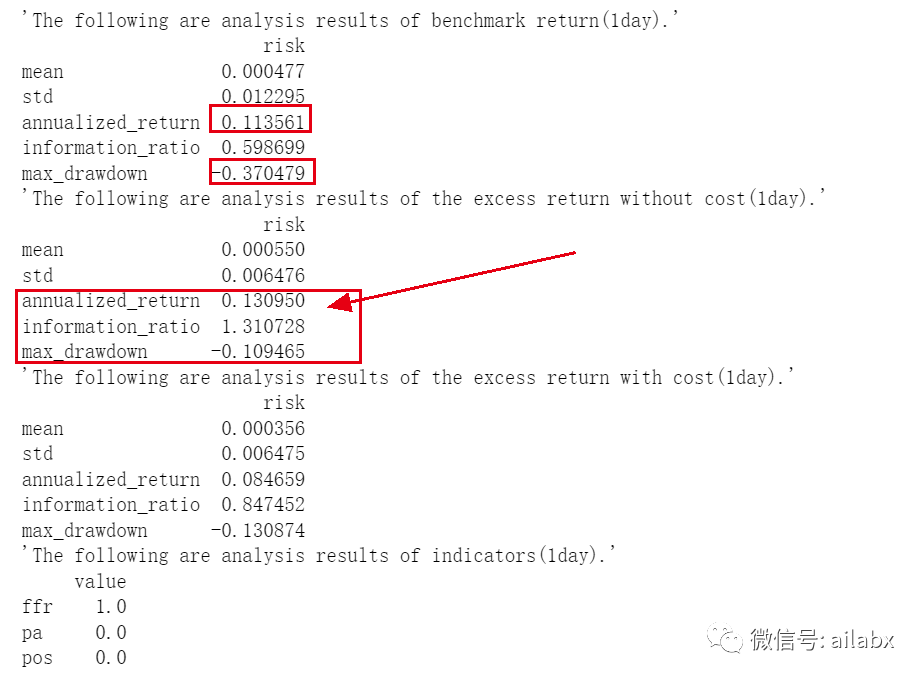
回测了一下,效果还不错:
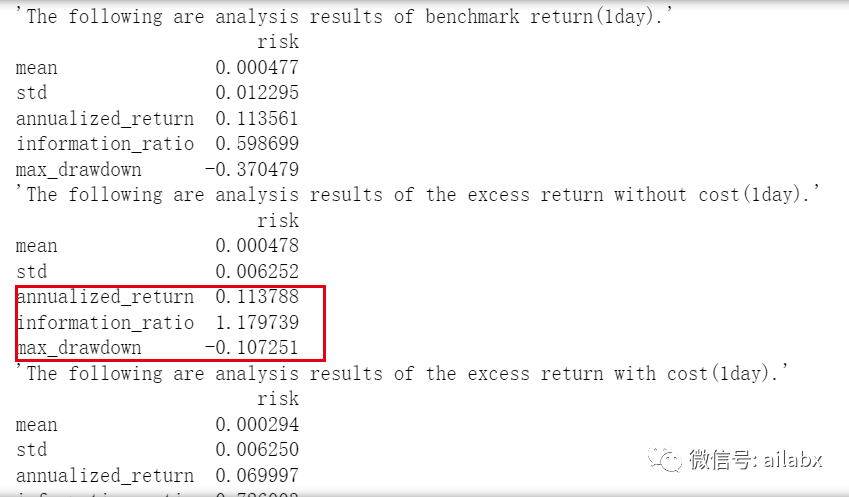
沪深300指数在这段时间的年化是11.3%,但最大回撤在37%。我们的策略是超额收益13%(年化就是24.3%),回撤在10.9%。
03 因子集不变,更换模型
xgboost需要单独安装:pip install xgboost
def load_xgboost():
from qlib.contrib.model.xgboost import XGBModel
config = {
'eval_metric': 'rmse',
'colsample_bytree': 0.8879,
'eta': 0.0421,
'max_depth': 8,
'n_estimators': 647,
'subsample': 0.8789,
'nthread': 20
}
model = XGBModel(**config)
return model
其余代码不变,但xgboost与lightGBM相比,对cpu,内存消耗高得不是一个数量级,本地笔记本就点带不动了。——机器学习玩大数据,装备很重要。

IC和Rank IC都有提升,到达0.041和0.048,但回测结果没有更好,反而变差了一些。
更多深度学习模型,需要pytorch,选择安装1.8.2,这个版本小一点。
pip install torch==1.8.2 torchvision==0.9.2 torchaudio===0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu102
加载GRU的时间序列模型:
def load_gru():
from qlib.contrib.model.pytorch_gru_ts import GRU
config = {
'd_feat': 20,
'hidden_size': 64,
'num_layers': 2,
'dropout': 0.0,
'n_epochs': 200,
'lr': 2e-4,
'early_stop': 10,
'batch_size': 800,
'metric': 'loss',
'loss': 'mse',
'n_jobs': 20,
'GPU': 0,
}
model = GRU(**config)
return model
04 加载时间序列数据集:
与把序列当成普通数据集相对,交易序列更适合时间序列分析。因为后一天实际与前一天是有关联的。
多了一些数据的规整的预处理,时序分析的数据集要求更高一些,处理不了空值,树模型对空值无所谓的,它们对异常值也不敏感。
def load_dataset_ts(confgi=None):
data_handler_config = {
"start_time": "2010-01-01",
"end_time": "2020-08-01",
"fit_start_time": "2010-01-01",
"fit_end_time": "2014-12-31",
"instruments": 'csi300',
"label": ["Ref($close, -2) / Ref($close, -1) - 1"],
"infer_processors": [
{
"class": "FilterCol",
"kwargs": {"fields_group": "feature",
"col_list": ["RESI5", "WVMA5", "RSQR5", "KLEN", "RSQR10", "CORR5", "CORD5", "CORR10",
"ROC60", "RESI10", "VSTD5", "RSQR60", "CORR60", "WVMA60", "STD5",
"RSQR20", "CORD60", "CORD10", "CORR20", "KLOW"
]
}
},
{
"class": "RobustZScoreNorm",
"kwargs": {"fields_group": "feature",
"clip_outlier": True
}
},
{
"class": "Fillna",
"kwargs": {"fields_group": "feature",
}
}
],
"learn_processors": [
{
"class": "DropnaLabel",
# "module_path": "qlib.contrib.data.handler",
},
{
"class": "CSRankNorm",
# "module_path": "qlib.contrib.data.handler",
"kwargs": {"fields_group": "label"}
},
]
}
config = {
"class": "TSDatasetH",
"module_path": "qlib.data.dataset",
"kwargs": {
"handler": {
"class": "Alpha158",
"module_path": "qlib.contrib.data.handler",
"kwargs": data_handler_config,
},
"segments": {
"train": ("2010-01-01", "2014-12-31"),
"valid": ("2015-01-01", "2016-12-31"),
"test": ("2017-01-01", "2020-08-01"),
},
"step_len": 20
},
}
ds = init_instance_by_config(config)
return ds
今天只试验了两个模型,都是基于集成树模型的。
alpha158的设计里,实际上是包含了时间序列信息的,比如60日均线,N天的动量之类的。序列的结果会不会更好,这个改天可以试。
目前直观的感受是,重点还在因子,先做因子功课,然后再看调优模型。
下一步的任务,把gbdt_158做为一个benchmark,看能不能更少但更好的因子,可以超越它。















 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











