






原创内容第647篇,专注量化投资、个人成长与财富自由。
昨天复盘星球工作,深刻感受一个词的重要性:专注。
一人企业,也是企业运作的逻辑。只是成本降到最低。要专注。
企业本身也要专注,有所不为,有所必为。一人企业,意味着资源更少。
专注才能把点打透才能创造价值,形成正循环。很多事都想做,分散就不容易做精(这与投资不一样。)。
好执行大于好点子,好产品是持续打磨出来的,战线太长就不容易打磨精致。
因此,量化实验室,专注ETF/LOF市场,把事情做扎实,创造真实的价值。
1、低代码策略回测平台。
2、因子生成。扩展:因子表达式,因子挖掘(含基础数据维度扩充)。信号规则筛选。
3、因子合成排序:等权,IC加权,树模型。
4、策略合成,实盘对接。
平台的扩展性在于因子扩展,包含因子挖掘,还有后续的实盘自动化对接。
场内基金今天的准确数字是1426支,含LOF,跨全球市场,跨股票、债券、商品,REITs等,足够了。
而且这里的方向论和工具,大家是可以自行扩展到更多市场的。
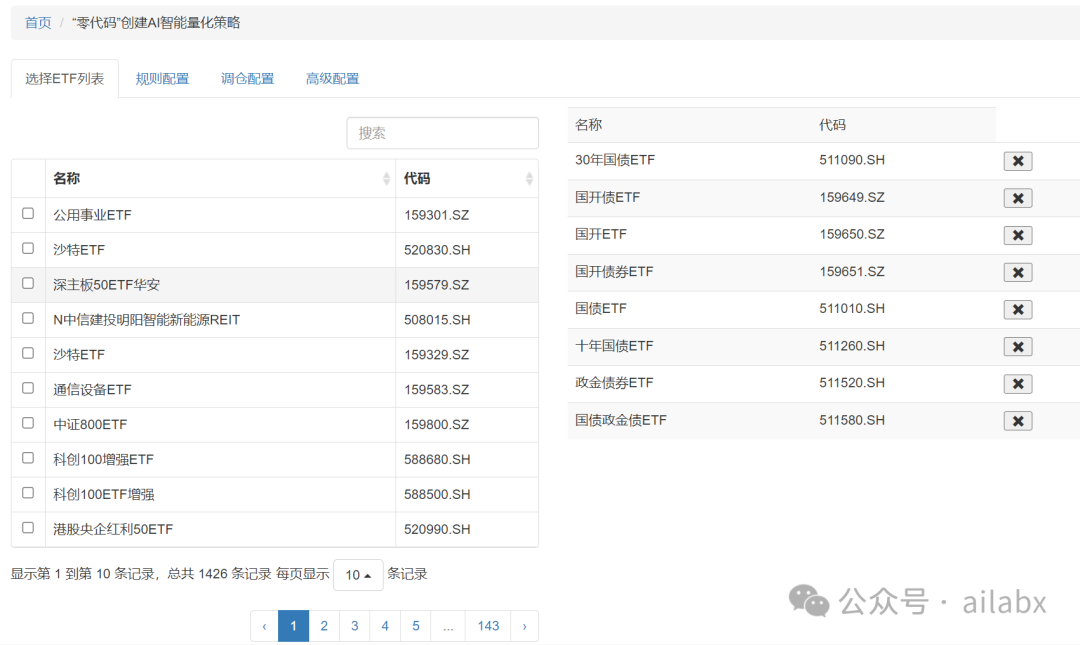
基础数据还可以补充热门,宽基之类的筛选项。
另外就是日线价量数据,基本就足够量化回测使用,而且我们直接同步后复权数据——与真实价格有差别,但不影响结果。
历史全量数据大约200万行,还好。
日线可以完全下载到本地CSV,以加速回测过程。
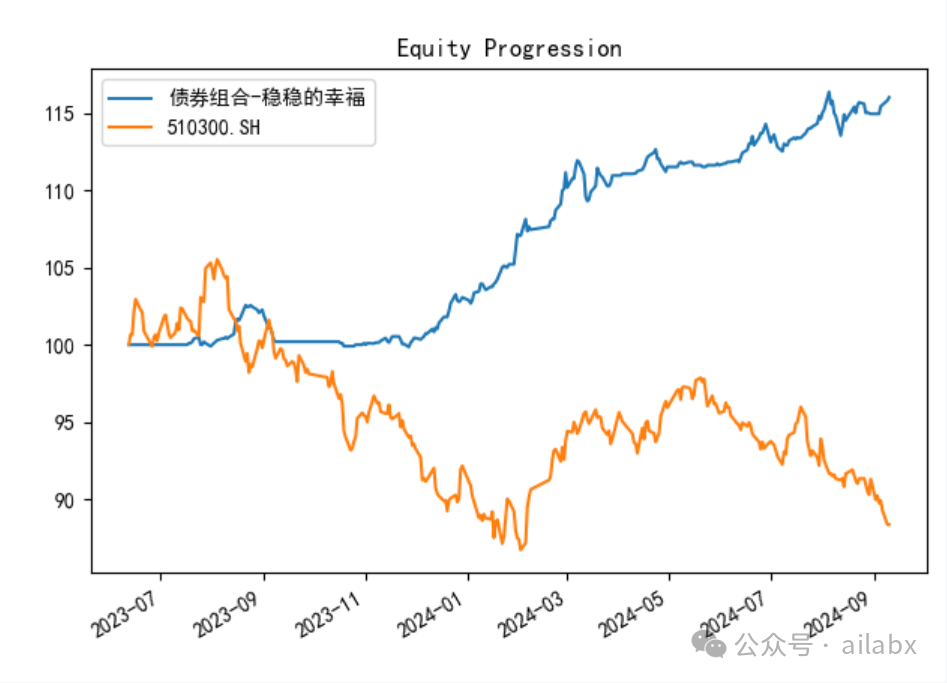
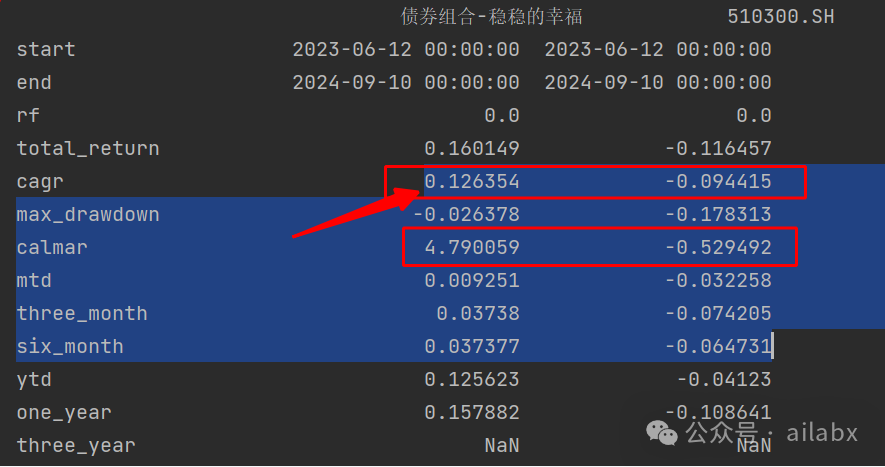
年化12.6%,最大回撤才2.6的债券轮动策略,卡玛比4.79。
重写了Engine:
import importlib
class Engine:
def _get_algos(self, task: Task, df):
bt_algos = importlib.import_module('bt.algos')
if task.period == 'RunEveryNPeriods':
algo_period = bt.algos.RunEveryNPeriods(n=task.period_N)
else:
algo_period = getattr(bt_algos, task.period)()
algo_weight = getattr(bt_algos, task.weight)()
algo_select_where = None
# 信号规则
if task.select_buy is not None:
roc_20 = CSVDataloader.get_col_df(df, 'roc_20')
signal_buy = roc_20 > 0
signal_sell = roc_20 < 0
select_signal = np.where(signal_buy, 1, np.nan)
select_signal = np.where(signal_sell, 0, select_signal)
select_signal = pd.DataFrame(select_signal, index=signal_buy.index, columns=signal_buy.columns)
select_signal.ffill(inplace=True)
select_signal.fillna(0, inplace=True)
algo_select_where = bt.algos.SelectWhere(signal=select_signal)
# 排序因子
algo_order_by = None
if task.order_by_signal:
signal_order_by = CSVDataloader.get_col_df(df, col=task.order_by_signal)
algo_order_by = SelectTopK(signal=signal_order_by, K=task.order_by_topK, sort_descending=task.order_by_DESC)
algos = []
algos.append(algo_period)
if algo_select_where:
algos.append(algo_select_where)
else:
algos.append(bt.algos.SelectAll())
if algo_order_by:
algos.append(algo_order_by)
algos.append(algo_weight)
algos.append(bt.algos.Rebalance())
return algos
def run(self, task: Task):
# 加载数据
df = CSVDataloader.get_df(task.symbols, True, task.start_date, task.end_date)
# 计算因子
if len(task.symbols):
df = CSVDataloader.calc_expr(df, fields=task.fields, names=task.names)
s = bt.Strategy(task.name, self._get_algos(task, df))
df_close = CSVDataloader.get_col_df(df, 'close')
bkt = bt.Backtest(s, df_close, name=task.name)
bkts = [bkt]
for bench in [task.benchmark]:
data = CSVDataloader.get([bench])
s = bt.Strategy(bench, [bt.algos.RunOnce(),
bt.algos.SelectAll(),
bt.algos.WeighEqually(),
bt.algos.Rebalance()])
stra = bt.Backtest(s, data, name=bench)
bkts.append(stra)
res = bt.run(*bkts)
return res
代码下载:AI量化实验室 星球,已经运行三年多,1100+会员。quantlab代码交付至5.X版本,含几十个策略源代码,因子表达式引擎、遗传算法(Deap)因子挖掘引擎等,每周五迭代一次。

02 五年财务自由退休
财富自由实战方法论,构建两大系统:现金流系统和商业系统。

(限时免费,感兴趣可入)五年之约,一起出发吧!
















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











