






xgboost是华盛顿大学博士陈天奇创造的一个梯度提升(Gradient Boosting)的开源框架。至今可以算是各种数据比赛中的大杀器,被大家广泛地运用。接下来,就详细介绍一下xgboost的原理和公式推导。
XGBoost其实是一个树集成模型,他将K(树的个数)个树的结果进行求和,作为最终的预测值。好比接下来有两颗决策树:tree1和tree2
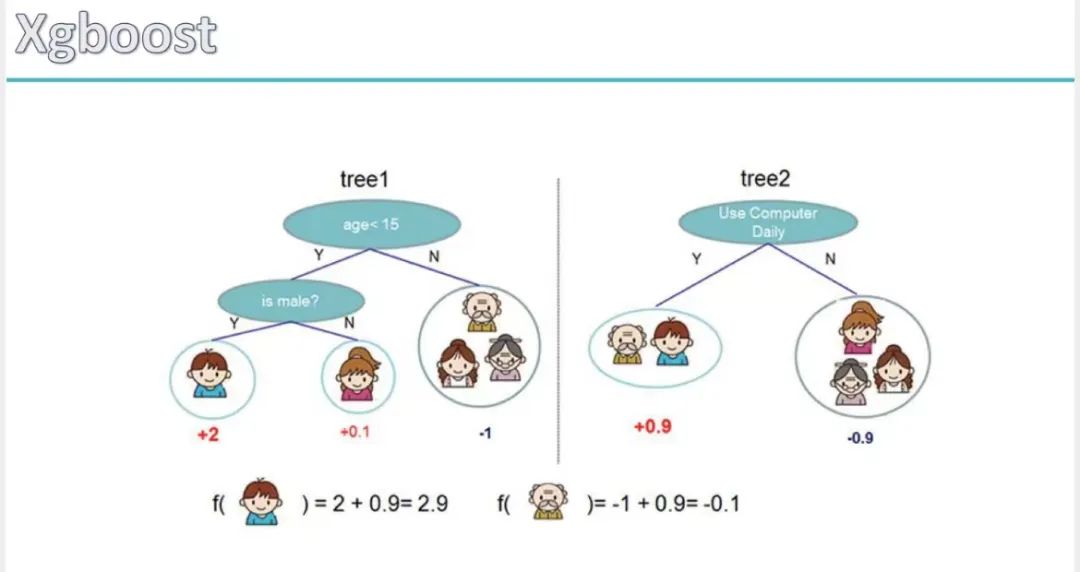
小男孩的回归预测分数是tree1叶子结点的权重和tree2叶子结点的权重相加:2 + 0.9 = 2.9。爷爷的预测分数同理:-1 + (-0.9)= -1.9。
所以我们可以得出Xgboost的预测函数
![]()
由此得出我们的目标函数(实际值-预测值):
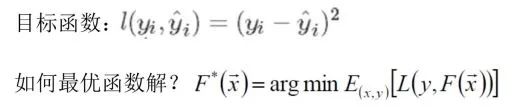
而接下来的优化就是使得我们的目标函数最小,即预测值无限接近真实值。
那么Xgboost就可以抽象成如下方程式,即第t轮的模型预测等于前面t-1轮的模型预测再加上一个新的函数,这个新的函数就是当前的决策树。每加一个函数预测效果都要比之前更好一些。

我们之前讲决策树的时候,讲到决策树自身会有一些惩罚项,比如叶子结点过多,决策树过拟合的风险就会变大。所以说我们设置一个损失函数来表述惩罚项,比如叶子的个数,还有对权重的l2惩罚项。
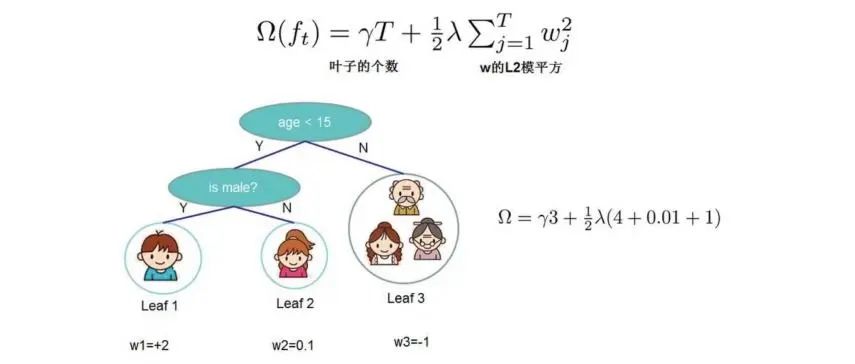
所以我们的目标函数就变成了如下的方程式所示:
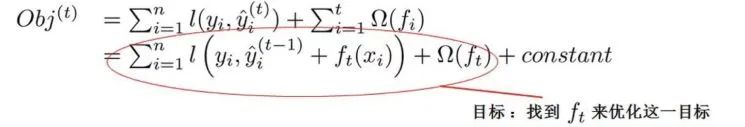
接下来我们使用泰勒来展开我们的目标函数:
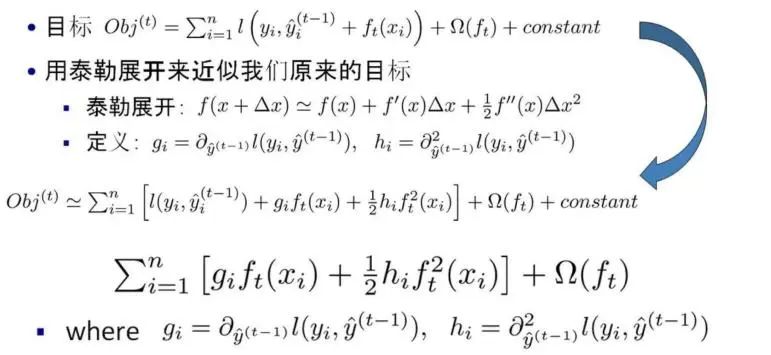
接下来我们进一步化简目标函数,把ft换成权重与叶子结点的函数,把样本遍历换成叶子结点上的遍历,减少遍历次数。
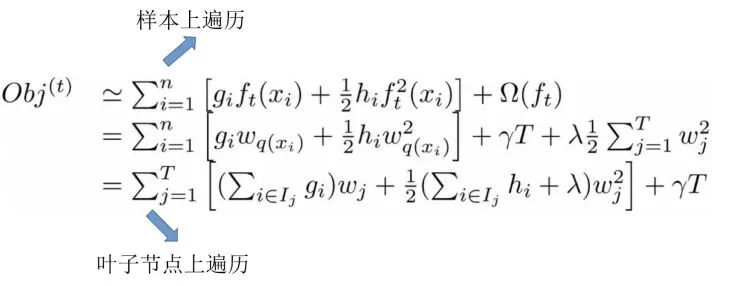
继续化简,展开惩罚项,一并进行化简,可化简如下所示公式:
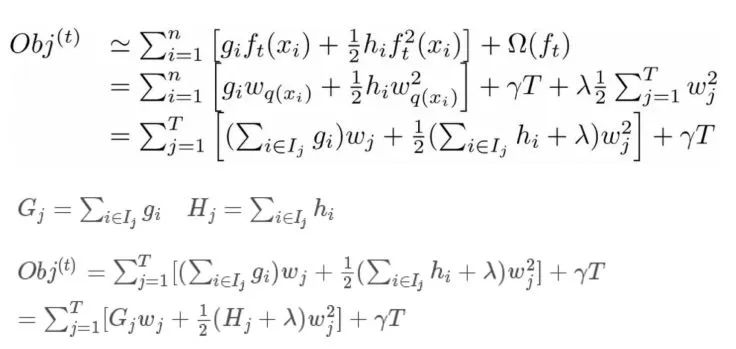
为了使得目标函数最小,我们需要对其对权重w进行求导后使其偏导数为0,然后再带入目标函数中,如下:

目标函数代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少,我们可以把它叫做结构分数,你可以认为这个就是类似基尼系数一样更加一般的对于树结构进行打分的函数,下面是一个具体的例子:
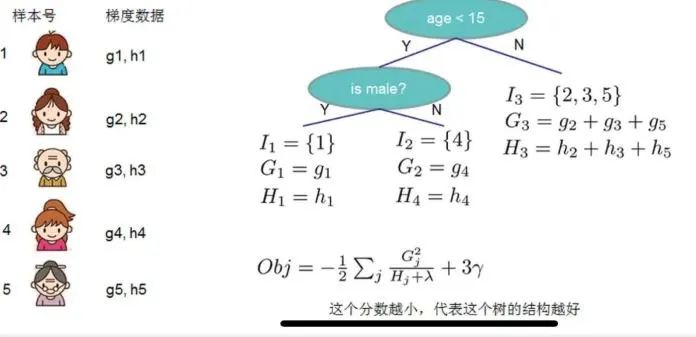
如上就是比赛战斗机Xgboost集成算法的原理和推导公式,他的优缺点如下所示:
XGBoost的主要优点:
1. 简单易用。相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果。
2. 高效可扩展。在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高。
3. 鲁棒性强。相对于深度学习模型不需要精细调参便能取得接近的效果。
4. XGBoost内部实现提升树模型,可以自动处理缺失值。
XGBoost主要缺点
1. 相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。
2. 在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先XGBoost。
怎么样,大家学会了嘛,快来点个赞吧~
喜欢的话点个关注哦~ 会每天分享人工智能机器学习内容,回复关键字可获取相关算法数据及代码~
















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









