







在讨论GBDT前,先来看看什么是GD,BGD和SGD
GD(Gradient Descent,梯度下降):
求损失函数最小值:梯度下降;求损失函数最大值:梯度上升。
假设线性模型:
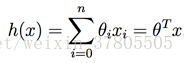
损失函数为:
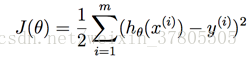
那么每次GD的更新算法为:
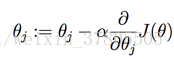
BGD(Batch Gradient Descent,批量梯度下降):
在更新参数时使用所有的样本来进行更新。
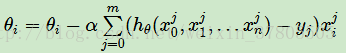
SGD(Stochastic Gradient Descent,随机梯度下降):
仅仅选取一个样本j来求梯度。
总结:
当训练数据过大时,用GD可能造成内存不够用,就可以用SGD。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









