







摘要:本文介绍了用seleminue + requests 实现爬取若依框架数据,重点是用seleminue驱动浏览器登录远程站点,然后用request实现快速爬取数据。
第1部分:seleminue简介
1.1 什么是selenium
selenium其官网的介绍是:
Selenium 使浏览器自动化。
你用这种力量做什么完全取决于你。
主要是为了测试目的而自动化 Web 应用程序,但当然不仅限于此。
无聊的基于 Web 的管理任务也可以(并且应该)实现自动化。
selenium最初是一个自动化测试工具,提供了一套测试函数,用于支持Web自动化测试,函数非常灵活,能够完成页面元素定位、窗口跳转、鼠标点击事件、滚动窗口、前进倒退等等操作。
而爬虫中使用它主要是为了解决requests无法执行javaScript代码的问题,比如无法跨越需要用户登录的障碍,
1.2 selenium的用途
a. selenium可以驱动浏览器自动执行自定义好的逻辑代码,也就是可以通过代码完全模拟成人类使用浏览器自动访问目标站点并操作,那我们也可以拿它来做爬虫
b. selenium本质上是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等...进而拿到网页渲染之后的结果,可支持多种浏览器
selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驱动程序最受 Python 和 C#用户迎。 selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 Web 浏览器中运行。在爬虫领域 selenium 同样是一把很常用的利器!
1.3 selenium驱动浏览器原理
对于用户代码而言本质上是通过selenium的WebDriver来驱动真正的浏览器,selenium提供了目前市面上常见的浏览器匹配的WebDriver,比如有Chrome不同版本的WebDriver,也有FireFox不同版本的WebDriver.
在我们创建一个WebDrive实例的过程中,selenium首先会确认浏览器的native component是否存在可用而且版本匹配。接着就在目标浏览器里启动一整套Web Service,这套Web Service使用了Selenium自己设计定义的协议,名字叫做The WebDriver Wire Protocol。这套协议非常之强大,几乎可以操作浏览器做任何事情,包括打开、关闭、最大化、最小化、元素定位、元素点击、上传文件等等等等。
WebDriver Wire协议是通用的,也就是说不管是FirefoxDriver还是ChromeDriver,启动之后都会在某一个端口启动基于这套协议的Web Service。例如FirefoxDriver初始化成功之后,默认会从http://localhost:7055开始,而ChromeDriver则大概是http://localhost:46350之类的。接下来,我们调用WebDriver的任何API,都需要借助一个ComandExecutor发送一个命令,实际上是一个HTTP request给监听端口上的Web Service。在我们的HTTP request的body中,会以WebDriver Wire协议规定的JSON格式的字符串来告诉Selenium我们希望浏览器接下来做社么事情。
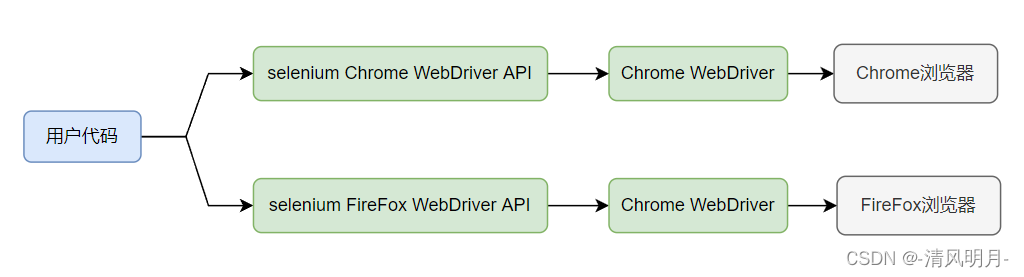
上面的这张图可以解释用户代码、WebDriver API、WebDriver以及浏览器的关系,总结下来就一句话:用户通过代码访问WebDriver API然后WebDriver API 操作WebDriver,WebDriver操控浏览器。最终实现用户代码访问浏览器。
1.4 selenium优缺点
(1)优点
可以帮我们避开一系列复杂的通信流程,例如requests模块,那么requests模块在模拟请求的时候是不是需要把素有的通信流程都分析完成后才能通过请求,然后返回响应。假如目标站点有一系列复杂的通信流程,例如的登录时的滑动验证等...那么你使用requests模块的时候是不是就特别麻烦了。不过你也不需要担心,因为网站的反爬策略越高,那么用户的体验效果就越差,所以网站都需要在用户的淫威之下降低安全策略。
再看一点requests请求库能不能执行js?答案是不能!那么如果你的网站需要发送ajax请求,异步获取数据渲染到页面上,是不是就需要使用js发送请求了。那浏览器的特点是什么?是不是可以直接访问目标站点,然后获取对方的数据,从而渲染到页面上。那这些就是使用selenium的好处!
(2)缺点
使用selenium本质上是驱动浏览器对目标站点发送请求,那浏览器在访问目标站点的时候,是需要把静态资源比如html、css、js这些文件都要等待它加载完成渲染完成。因此速度比较慢。因此速度慢就是最大的缺点,它的坏处就是效率极低!所以我们一般用它来做登录验证。
1.5 selenium的安装
我的开发环境是:
pyCharm 2021.3.3 (Community Edition)
Anaconda 4.12.0 + Python 3.9.7
Chrome 99.0.4844(正式版本) (64 位)
用户代码以python为例,因此在实际应用中需要在python开发环境中安装selenium和浏览器版本匹配的WebDriver
1.5.1在Anaconda中创建虚拟环境
关于Anaconda的使用可以参考我的另一个文章Anaconda------环境管理,在Conda的世界里可以体验到多维世界的乐趣。根据需要可以为你创建不同的虚拟环境,可以在不同的虚拟环境中安装不同的python版本及其依赖包,而且还很方便在各个虚拟环境中切换,并且Pycham还可以使用这些虚拟环境,因此值得学习和应用。
conda create -n your_env_name python=x.x其实创建虚拟环境就是安装一个指定版本的python,下面是详细的过程
d:\>conda create -n python_neo4j python=3.9.7
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: D:\02_installed\Anaconda\envs\python_spider
added / updated specs:
- python=3.9.7
The following NEW packages will be INSTALLED:
ca-certificates pkgs/main/win-64::ca-certificates-2022.3.29-haa95532_0
certifi pkgs/main/win-64::certifi-2021.10.8-py39haa95532_2
openssl pkgs/main/win-64::openssl-1.1.1n-h2bbff1b_0
pip pkgs/main/win-64::pip-21.2.4-py39haa95532_0
python pkgs/main/win-64::python-3.9.7-h6244533_1
setuptools pkgs/main/win-64::setuptools-58.0.4-py39haa95532_0
sqlite pkgs/main/win-64::sqlite-3.38.2-h2bbff1b_0
tzdata pkgs/main/noarch::tzdata-2022a-hda174b7_0
vc pkgs/main/win-64::vc-14.2-h21ff451_1
vs2015_runtime pkgs/main/win-64::vs2015_runtime-14.27.29016-h5e58377_2
wheel pkgs/main/noarch::wheel-0.37.1-pyhd3eb1b0_0
wincertstore pkgs/main/win-64::wincertstore-0.2-py39haa95532_2
Proceed ([y]/n)?输入y,表示继续,结束之后是这样:
done
#
# To activate this environment, use
#
# $ conda activate python_selenium
#
# To deactivate an active environment, use
#
# $ conda deactivate查看当前的虚拟环境
d:\>conda env list
# conda environments:
#
base * D:\02_installed\Anaconda
python_neo4j D:\02_installed\Anaconda\envs\python_neo4j可以看到虽然安装了新的虚拟环境,但是默认还是base环境,因此还需要切换到新装的虚拟环境中
d:\>activate python_neo4j然后查看当前的虚拟环境中已有的依赖包
(python_neo4j) d:\>conda list
# packages in environment at D:\02_installed\Anaconda\envs\python_neo4j:
#
# Name Version Build Channel
ca-certificates 2022.3.29 haa95532_0
certifi 2021.10.8 py39haa95532_2
openssl 1.1.1n h2bbff1b_0
pip 21.2.4 py39haa95532_0
python 3.9.7 h6244533_1
setuptools 58.0.4 py39haa95532_0
sqlite 3.38.2 h2bbff1b_0
tzdata 2022a hda174b7_0
vc 14.2 h21ff451_1
vs2015_runtime 14.27.29016 h5e58377_2
wheel 0.37.1 pyhd3eb1b0_0
wincertstore 0.2 py39haa95532_2
(python_neo4j) d:\>注意到第二行的提示:
# packages in environment at D:\02_installed\Anaconda\envs\python_neo4j
其实创建一个虚拟环境本质上在Anaconda的envs目录下创建一个新的目录然后在这个目录中安装了指定的python版本,后续安装的相关依赖包实质上也是安装在这个目录下
1.5.2.在虚拟环境中安装selenium
pip install selenium
(python_neo4j) d:\>pip show selenium
Name: selenium
Version: 4.1.3
Summary:
Home-page: https://www.selenium.dev
Author:
Author-email:
License: Apache 2.0
Location: d:\02_installed\anaconda\envs\python_neo4j\lib\site-packages
Requires: trio, urllib3, trio-websocket
Required-by:
(python_neo4j) d:\>在虚拟环境的python中导入selenium试试看
(python_neo4j) d:\>python
Python 3.9.7 (default, Sep 16 2021, 16:59:28) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import selenium
>>>可以看到导入正常,说明selenium已经安装成功
1.6 WebDriver的安装
找到自己的chrome浏览器的版本号之后,打开这个镜像站点镜像站点比如我的浏览器版本是99.0.4844,然后就找到99.0.4844的目录
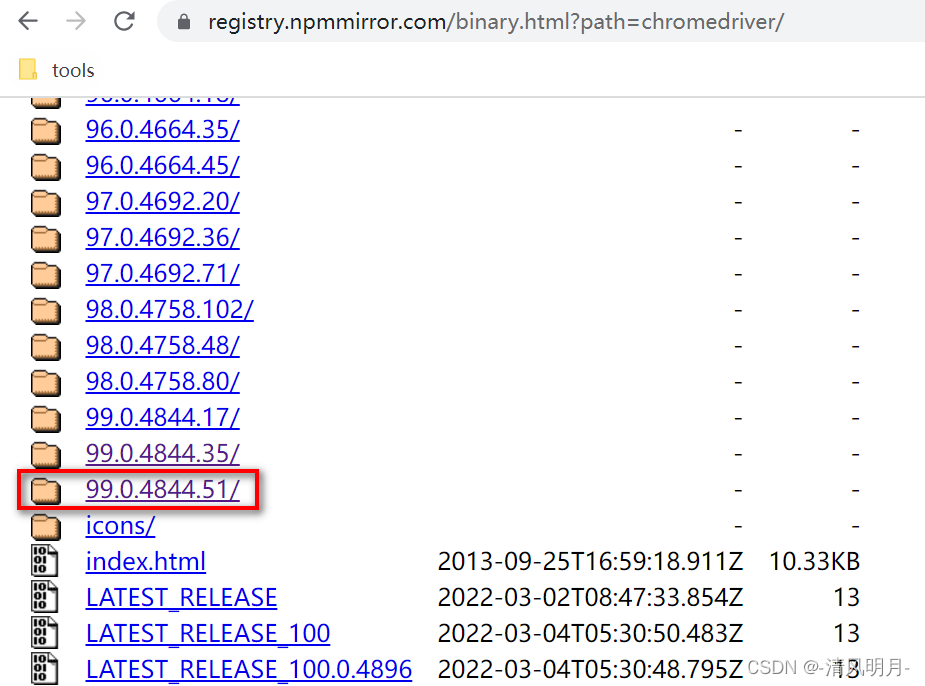
打开这个目录
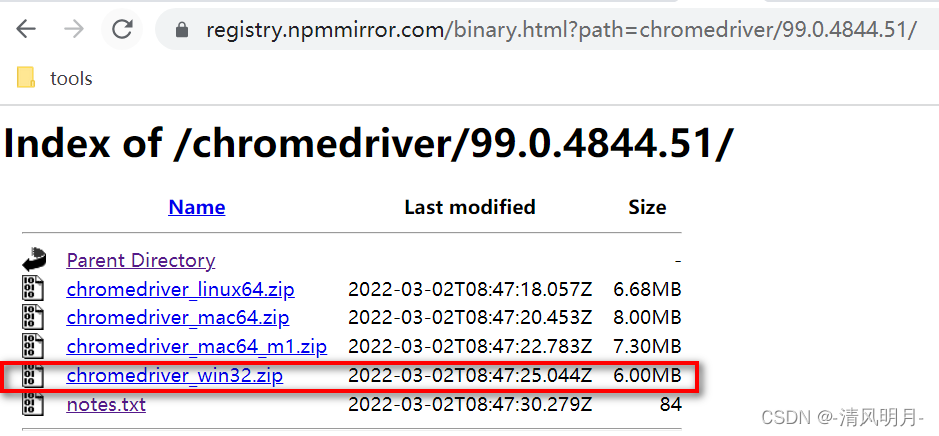
发现这里只有win32的版本,也能用于win64,因此就可以下载这个, 下载后解压得到chromedriver.exe,然后把这个文件放在anaconda python_neo4j这个虚拟环境的里面,只要和python.exe在同一目录即可,这样在使用时不用指定chromedriver.exe的路径,比较方便些。
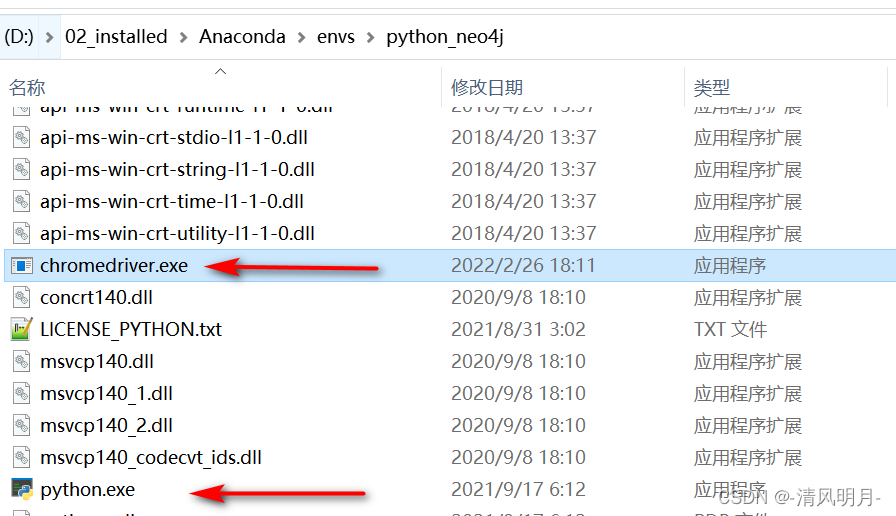
1.6.1 第一个案例
我们在这个案例中实现下面的操作:
a.打开Chrome浏览器
b.访问百度
c.在搜索框输入selenium
d.点击搜索按钮
e.10秒后关闭浏览器
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def demo1():
# 实例化一个Chrome的WebDriver实例
driver = webdriver.Chrome()
url = 'http://www.baidu.com'
# 用get方式打开百度
driver.get(url)
# 通过xpath来查找文本框DOM元素
input_box = driver.find_element(By.XPATH,'//*[@id="kw"]')
# 向文本框dom元素中输入需要查找的内容
input_box.send_keys('selenium')
# 通过ID的方式查找 【百度一下】 按钮
seartch_button = driver.find_element_by_id('su')
# 点击按钮
seartch_button.click()
time.sleep(10)
# driver.close()#浏览器可以同时打开多个界面,close只关闭当前界面,不退出浏览器
driver.quit()#退出整个浏览器
demo1()执行结果如下
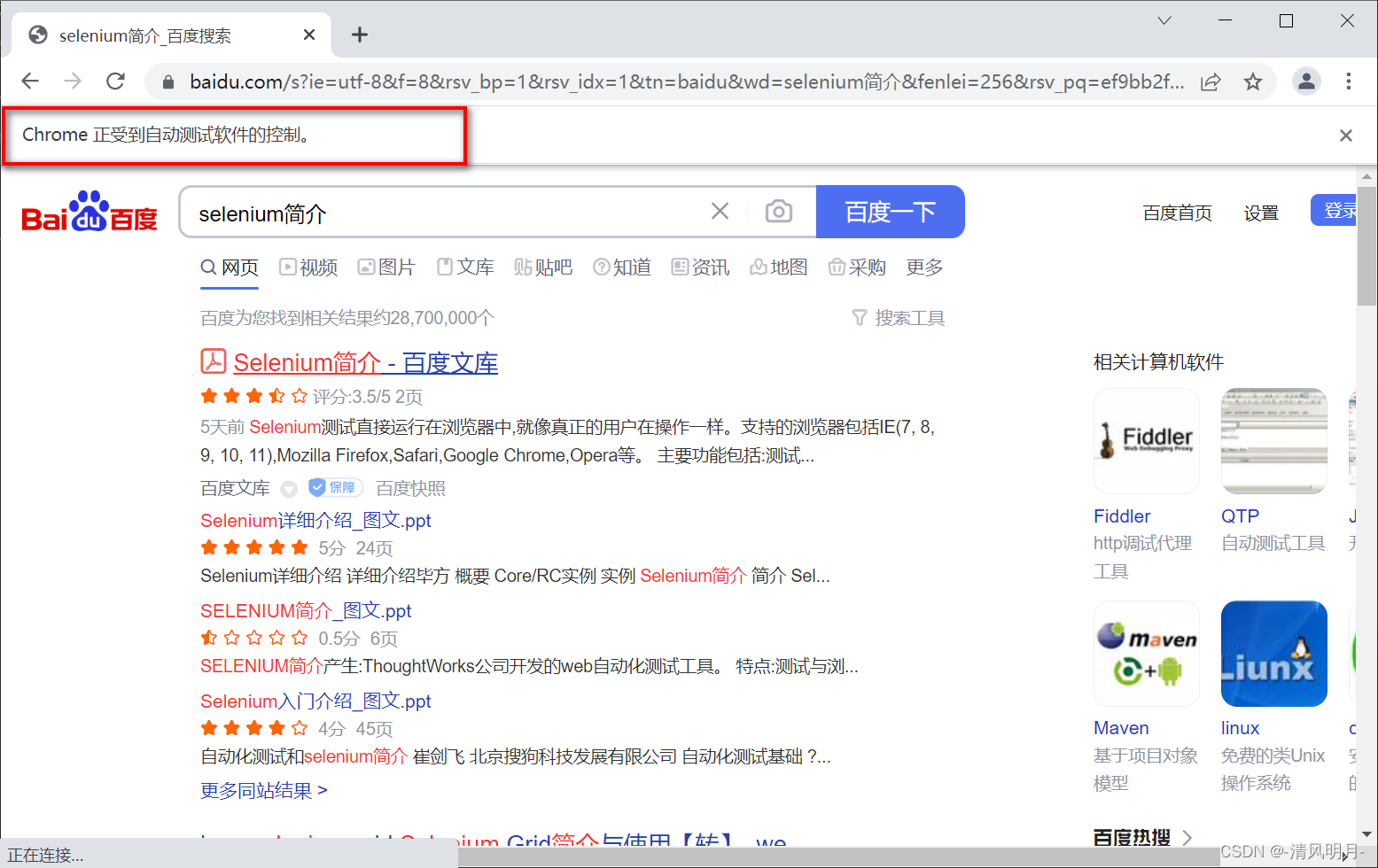
10秒后关闭浏览器退出
第2部分:分析爬取目标、制定爬虫方案
2.1 爬虫的作用
爬虫的本质是分析访问远程站点或者本地的站点源码文件(例如静态html)得到其中需要的数据。其实有两个方面可以获得数据。
1. 分析Web页面的dom元素,从dom元素中找到需要的数据
<li>
<a href="#"></span></a>
<ul class="nav nav-second-level collapse">
<li><a class="menuItem" href="#">查询条件</a></li>
<li><a class="menuItem" href="#">数据汇总</a></li>
<li><a class="menuItem" href="#">组合表头</a></li>
<li><a class="menuItem" href="#">表格导出</a></li>
<li><a class="menuItem" href="#">导出选择列</a></li>
<li><a class="menuItem" href="#">翻页记住选择</a></li>
<li><a class="menuItem" href="#">跳转至指定页</a></li>
<li><a class="menuItem" href="#">自定义查询参数</a></li>
<li><a class="menuItem" href="#">初始多表格</a></li>
<li><a class="menuItem" href="#">点击按钮加载表格</a></li>
<li><a class="menuItem" href="#">直接加载表格数据</a></li>
<li><a class="menuItem" href="#">表格冻结列</a></li>
<li><a class="menuItem" href="#">自定义触发事件</a></li>
<li><a class="menuItem" href="#">表格标题格式化</a></li>
<li><a class="menuItem" href="#">表格细节视图</a></li>
<li><a class="menuItem" href="#">表格父子视图</a></li>
<li><a class="menuItem" href="#">表格图片预览</a></li>
<li><a class="menuItem" href="#">动态增删改查</a></li>
<li><a class="menuItem" href="#">表格行拖拽操作</a></li>
<li><a class="menuItem" href="#">表格列拖拽操作</a></li>
<li><a class="menuItem" href="#">表格列宽拖动</a></li>
<li><a class="menuItem" href="#">表格行内编辑</a></li>
<li><a class="menuItem" href="#">主子表提交</a></li>
<li><a class="menuItem" href="#">表格自动刷新</a></li>
<li><a class="menuItem" href="#">表格打印配置</a></li>
<li><a class="menuItem" href="#">表格动态列</a></li>
<li><a class="menuItem" href="#">自定义视图分页</a></li>
<li><a class="menuItem" href="#">异步加载表格树</a></li>
<li><a class="menuItem" href="#">表格其他操作</a></li>
</ul>
</li>例如从上面的HTML片段中得到每个链接的文字部分
2. 访问某个Url模拟浏览器向远程服务器发送请求到到请求的纯数据
例如
https://redisdatarecall.csdn.net/recommend/get_head_word?bid=blog-110929187
返回
{
"status": 200,
"msg": "查询成功",
"content": [
"webdriver",
"selenium",
"api"
],
"ext": {
"selenium": "",
"webdriver": "",
"api": ""
},
"error": false
}理想情况下如果可以模拟浏览器直接向服务器发送请求获得这种干净的数据,节省从HTML中分析DOM元素的麻烦.
但是遗憾的是多数情况下不是这种理想的情况。
2.2 分析站点页面结构
今天要爬取的是若依的数据,访问若依之后会弹出一个登录页面
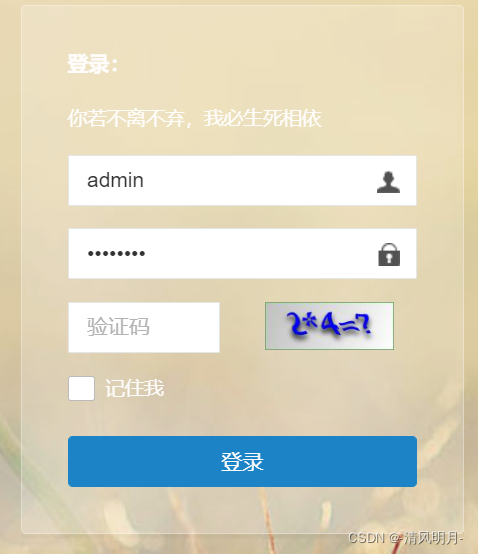
这里其实已经降低了很大难度,这只是个演示站点,并且已经提供了用户名和密码,只是需要验证码,但是验证码个表达式需要人工计算结果后填写结果然后才能登录,对于这种需要人工登录并且验证比较复杂的情况,普通的Request包解决不了,因此就需要用到selenium,selenium可以操控chrome人工登录,登录之后拿到cookie就方便了后续工作。
登录之后这样的界面
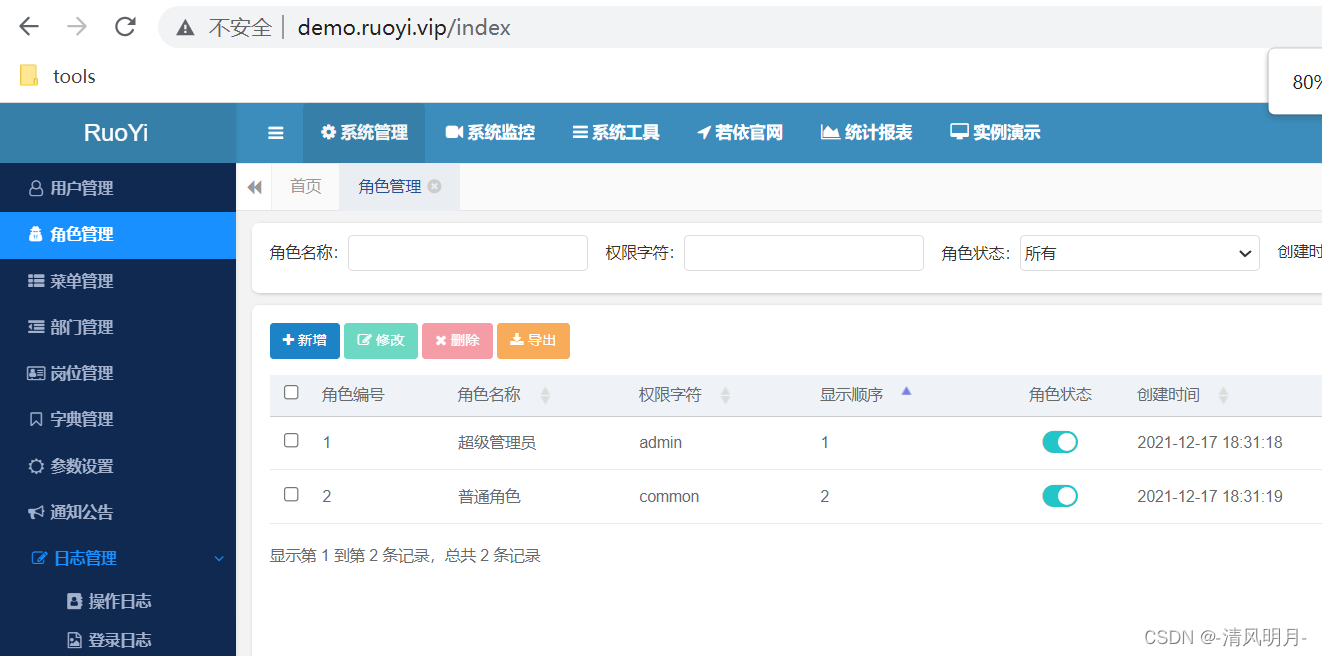
左侧是各个导航菜单,右侧是具体的内容,各个菜单的Url如下:
http://demo.ruoyi.vip/system/role 角色管理
http://demo.ruoyi.vip/system/menu 菜单管理
http://demo.ruoyi.vip/system/dept 部门管理
http://demo.ruoyi.vip/system/post 岗位管理
http://demo.ruoyi.vip/system/dict 字典管理
http://demo.ruoyi.vip/system/config 配置管理
http://demo.ruoyi.vip/system/notice 公告管理
http://demo.ruoyi.vip/monitor/operlog 操作日志
http://demo.ruoyi.vip/monitor/logininfor 登录日志
比如访问配置管理之前,按F12调出浏览器的开发者工具,然后再点击上图中的菜单管理按钮,此时查看浏览器的开发者工具中的网络找到config

单击响应页签可以看到这个请求的响应数据

发现这个请求的响应数据是html源码,但是仔细看源码后发现这里根本没有配置管理的真正数据,配置管理的页面渲染后的结果是: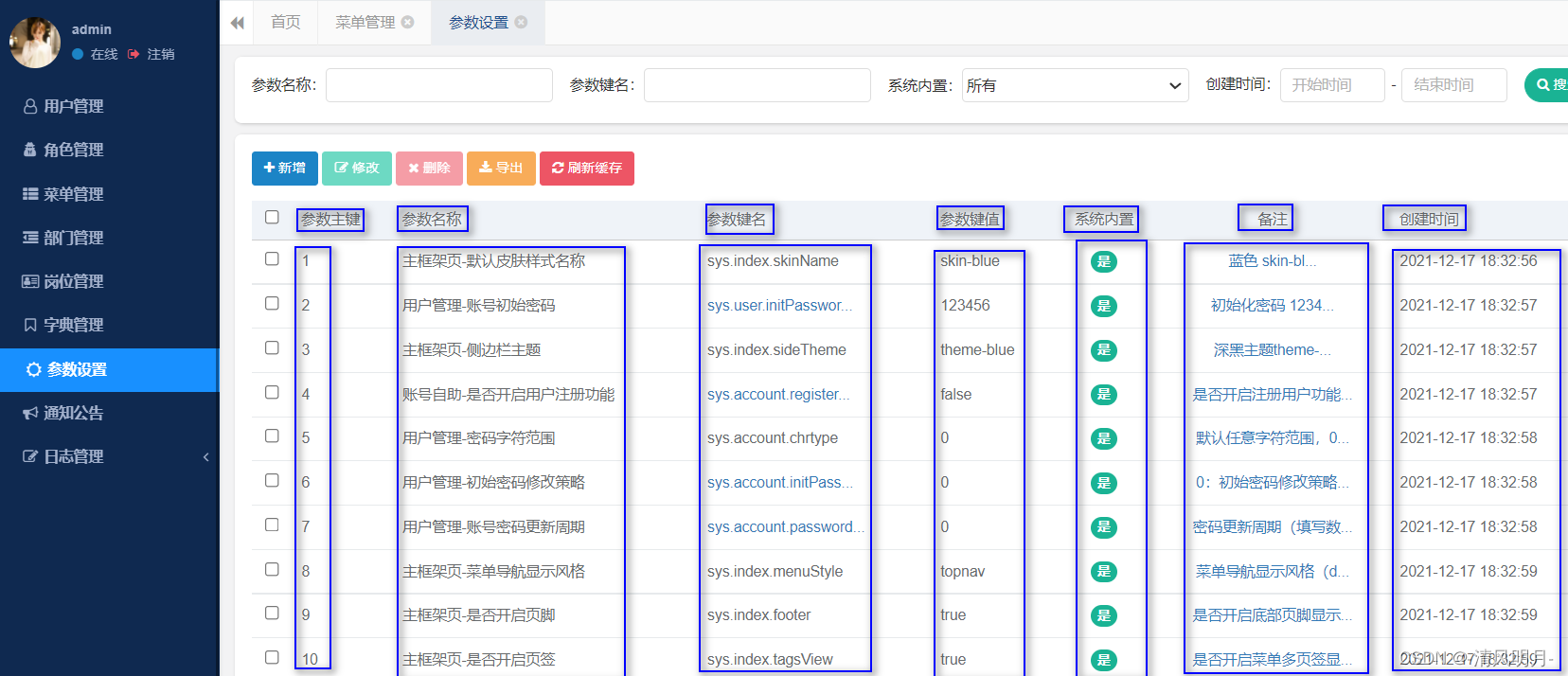
其中蓝色的框表示需要爬取的数据,下面看如何获得某个元素在DOM树中的位置

在浏览器开发者工具中点击最左侧的小箭头,然后把这个箭头移动到页面中需要查看的元素上,然后单击鼠标左键,此时浏览器开发者工具就自动切换到元素页签,并且显示这个元素的详细信息
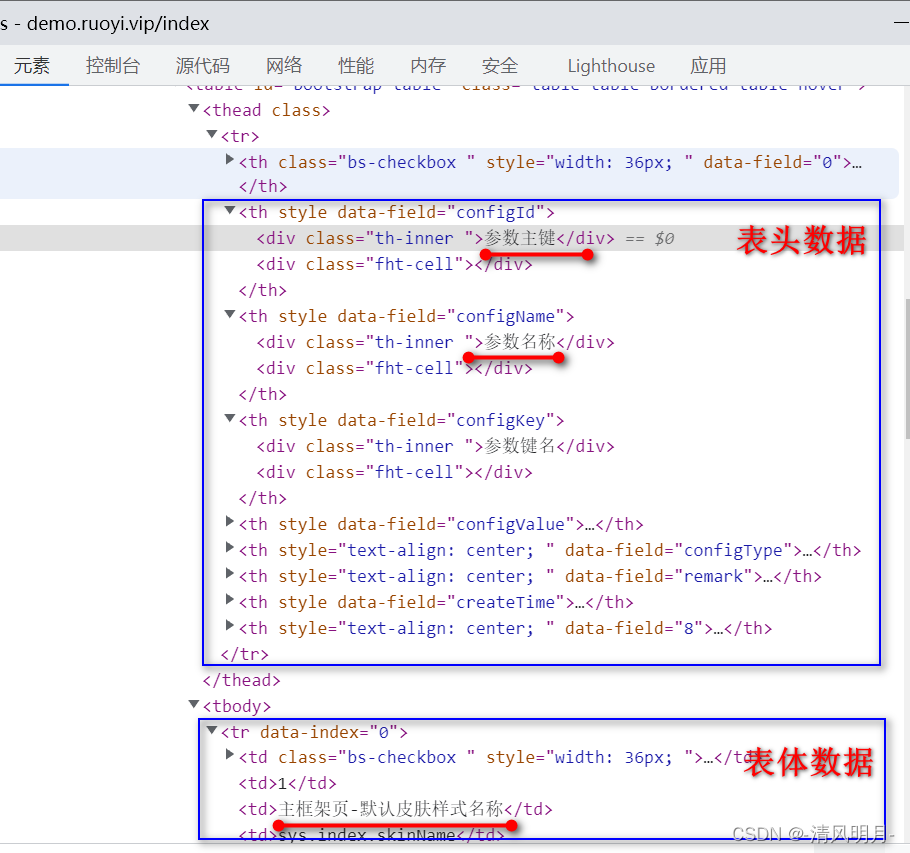
通过上图可以看到表头数据都在tbody>thead>tr>th里面从第2个td开始的
表体数据都在table>tbody>tr>td里面从第1个td开始的
下面是定位这个原始的方法在参数主键这一行上单击鼠标右键,在弹出菜单中选择【复制】-->【复制XPath】

会得到这个元素的定位://*[@id="bootstrap-table"]/thead/tr/th[2]
关于XPath详细语法网上有有很多的资料,这里不再赘述,上面的字符串表示从id=bootstrap-table这个元素开始查找thead元素下的th第2个元素,即可定位到"主键参数"这个字符串,用下面的方式即可获取这个元素中的文本
configId = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[2]').text那么同理可以得到表头的其他字符串:
configId = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[2]').text
configName = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[3]').text
configKey = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[4]').text
configValue = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[5]').text
configType = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[6]').text
remark = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[7]').text
createTime = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[8]').text那如何得到表格里面的真正的各行数据呢?
找到tbody>tr用上面的方法可以得到://*[@id="bootstrap-table"]/tbody/tr[1],表示tbody中第1个tr的元素,这里我们是要获取tbody内的所有tr,因此需要修改这个xpath表达式,变成
//*[@id="bootstrap-table"]/tbody/tr,用下面的方式可得到tbody内所有的tr
tbody = self.chrome.find_elements(By.XPATH,'//*[@id="bootstrap-table"]/tbody/tr')然后遍历这个tobdy集合,即可得到每一行的tr中的数据
for row in tbody:
r_configId = row.find_element(By.XPATH, 'td[2]').text
r_configName = row.find_element(By.XPATH, 'td[3]').text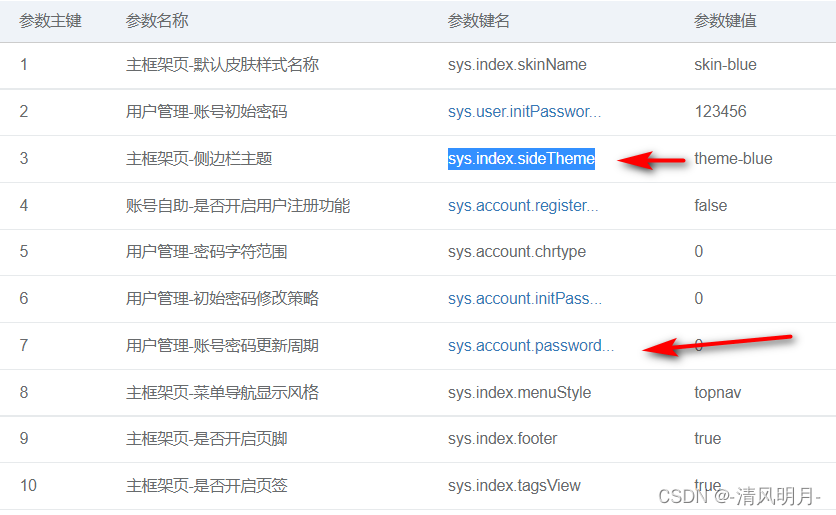
如上图所示,发现第7行的参数键名在页面上显示为:sys.account.password...,但是把鼠标放上去之后显示为完整的文本:sys.account.passwordValidateDays,使用浏览器开发者工具定位到这个元素之后发现其源码是这样:
<td>
<input style="opacity: 0;position: absolute;width:5px;z-index:-1" type="text"
value="sys.account.passwordValidateDays">
<a href="###"
class="tooltip-show" data-toggle="tooltip"
data-target="copy" title=""
data-original-title="sys.account.passwordValidateDays">sys.account.password...</a>
</td>里面有个inpu标签和a标签,其中input元素的value属性和a 标签的data-original-title属性值都是完整的数据,因此选择那个都可以得到完整的数据,但是对比了其他行的这个字段的数据发现并非所有行都是这种情况,如果文本比较比较短就可以完整显示的,比如第三行的参数名称=sys.index.sideTheme。其源码是:
<td>sys.index.sideTheme</td>因此说明只有在文本比较长的情况下才会省略部分文本,然后就会出现上面的那种结构,如果文本比较短直接包裹在td标签中,因此代码中需要判断这种情况
# 判断是否能查到指定的节点,如果存在返回true,否则返回false
def ifHasNode(self, broswer, by, xpathStr):
try:
broswer.find_element(by, xpathStr)
return True
except:
pass
return False这里定义了一个方法用来判断查找dom元素时是否报错,无表示找到了元素返回True,反之返回False,因此在应用时可以这样写:
if self.ifHasNode(row, By.XPATH, 'td[4]/input'):
r_configKey = row.find_element(By.XPATH, 'td[4]/input').get_attribute("value")
else:
r_configKey = row.find_element(By.XPATH, 'td[4]').text其他字段是也可以用同样的方法处理。因此爬取配置管理这个模块的数据完整的的代码入下:
# 爬取参数设置数据
def get_config(self):
menu_url = 'http://demo.ruoyi.vip/system/config'
self.chrome.get(menu_url)
data_header = []
reccords = []
#获得表头数据
configId = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[2]').text
configName = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[3]').text
configKey = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[4]').text
configValue = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[5]').text
configType = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[6]').text
remark = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[7]').text
createTime = self.chrome.find_element(By.XPATH, '//*[@id="bootstrap-table"]/thead/tr/th[8]').text
data_header.append([configId, configName, configKey,configValue,configType, remark, createTime]) #
print(data_header)
# 保存表头数据
self.save('config.txt',data_header)
# 查询表格里面的数据
tbody = self.chrome.find_elements(By.XPATH,'//*[@id="bootstrap-table"]/tbody/tr')
for row in tbody:
r_configId = row.find_element(By.XPATH, 'td[2]').text
r_configName = row.find_element(By.XPATH, 'td[3]').text
#参数键名字段有省略的情况,因此需要判断是否有input元素
if self.ifHasNode(row, By.XPATH, 'td[4]/input'):
r_configKey = row.find_element(By.XPATH, 'td[4]/input').get_attribute("value")
else:
r_configKey = row.find_element(By.XPATH, 'td[4]').text
r_configValue = row.find_element(By.XPATH, 'td[5]').text
r_configType = row.find_element(By.XPATH, 'td[6]').text
# 备注字段有省略的情况,因此需要判断是否有input元素
if self.ifHasNode(row, By.XPATH,'td[7]/input'):
r_remark = row.find_element(By.XPATH, 'td[7]/input').get_attribute("value")
else:
r_remark = row.find_element(By.XPATH, 'td[7]').text
r_createTime = row.find_element(By.XPATH, 'td[8]').text
print(r_configKey,r_remark)
# 数据缓存到list
reccords.append([r_configId,r_configName,r_configKey,r_configValue,r_configType,r_remark,r_createTime])
self.save('config.txt',reccords) #数据保存到文件其他的模块都可以如此处理,其实分析了其他的页面都是这样的结构,明白了这个结构之后就可以到得抓取数据的方法,可以根据
2.3 分析站点登录信息
这个站点的特殊性在于手工登录之后会在浏览器留下一些cookie,如果用上面的方式(分析dom)其实不用考虑cookie问题,因为被WebDriver驱动的浏览器自己就能解决这些问题,如果想要获得渲染前的干净的数据,就需要用到Request模块,用这个模块发送请求然后获得纯json数据。
比如打开了操作日志界面后,如果单击了翻页数据,发现提交的请求是这样:
url: http://demo.ruoyi.vip/monitor/operlog/list
post方式提交的参数: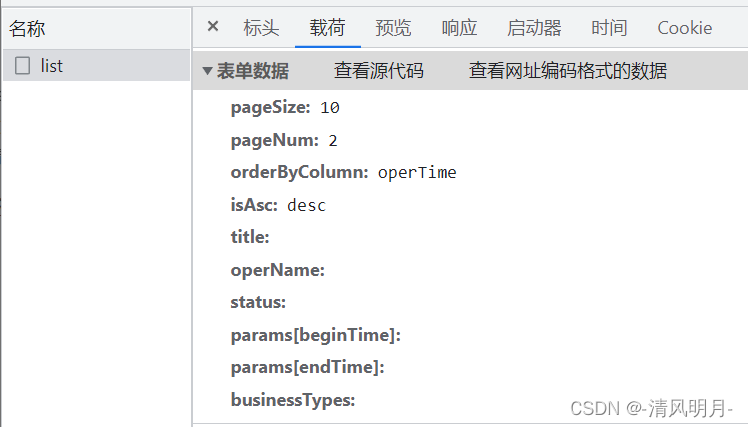
返回的数据: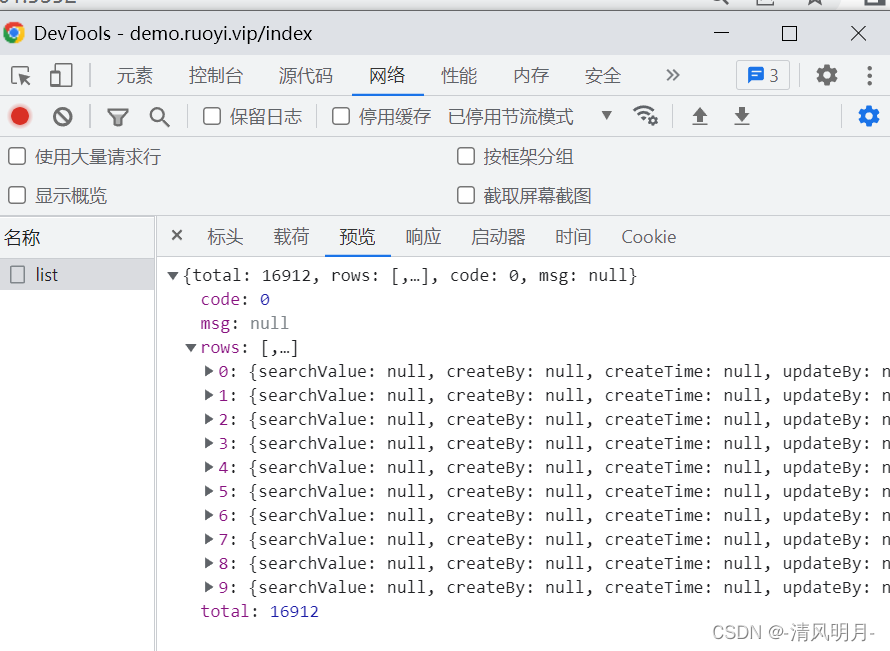
这就是干净的数据, 前面讲到如果想要得到这种干净的数据需要用Request模块,但是用Request模块就需要解决cookie问题。汇总一下思路
第一种爬取方式:方案1
完全用selenimu 分析dom元素,然后分页爬取数据
优点:简单,不用考虑登录问题、cookie问题
缺点:效率低
第二种爬取方式:方案2
首先用selenium解决登录问题获取cookie之后,用Request爬取数据
优点:效率高
缺点:稍微复杂些
其实本案例完全实现了以上两种方案,经过验证方案2确实效率优于方案1,并且两种方案可以共存,因此在实际的情况中可以根据需要灵活选择
第3部分:开发爬虫代码
3.1 初始化、登录操作
引入的包
import time
import re
import random
import requests
from requests.cookies import RequestsCookieJar
import json
from selenium.common.exceptions import StaleElementReferenceException
from selenium.webdriver.common.by import By
from selenium.webdriver import Chromeclass RuoYiSpider:
def __init__(self,root_url):
# 初试化类 传入被爬取网站的入口地址
self.root_url = root_url
# 登录网站
def login(self):
# 启动chromedriver
self.chrome = Chrome()
# 先打开入口地址 方便人工登录
self.chrome.get(self.root_url)
# 延时3秒
time.sleep(5)初始化时只是引入了被爬取站点的url,在登录方法中实例化一个Chrome(),然后用get方式打开root_url,打开时会提示登录,登录成功后会在浏览器中保留cookie数据
3.2 cookie操作
1.cookie持久化到本地文件
使用get_cookies()即可到cookie,然后使用json.dump把cookie保存到本地文件
# 把当前浏览器cookie数据持久化到文件
def save_cookie(self, brower):
cookies = brower.get_cookies()
with open("ruoyi_cookie.json", "w") as fp:
json.dump(cookies, fp)2.从本地文件加载cookie
# 从本地读取cooke数据
def load_cookie(self):
fake_cookie = RequestsCookieJar()
with open("ruoyi_cookie.json", "r") as fp:
cookies = json.load(fp)
for cookie in cookies:
fake_cookie.set(cookie['name'], cookie['value'])
return fake_cookie使用这种方法可以确保把持久化的cookie加载出来并且是可以正常使用的。其中用到了RequestsCookieJar,这个是requests.cookies里面的组件。
3.4 数据持久化
# 保存文件,设置编码格式为utf-8
def save(self,file, data_list):
file_handle = open(file, mode='a', encoding='utf-8')
for e in data_list:
# [] 里面的操作是为了把list中所有的元素变成字符串,方便进行join操作
s = ','.join([str(x) for x in e]) + '\n'
file_handle.write(s)
time_str = time.strftime('[%Y-%m-%d %H:%M:%S]', time.localtime(time.time()))
print(time_str + ' Append {0} lines of data to {1}'.format(file, len(data_list)))
file_handle.flush()
file_handle.close()调用这个方法需要传入目标文件的路径名称和一个保存了list的list,在本案例实际应用中,表格中的一行数据保存为一个list,多行的集合就是[[],[]] 这种格式。持久化时用join把每个list中的元素变成一个字符串,但是后面用到方案2爬取数据时,list里面的数据会有非字符串类型,因此用
[str(x) for x in e]把list中的每个元素都转成字符串方便join操作。
3.2 方案2的demo
思路是这样:
1.分析DOM元素得到表头的数据
2.分页发送HTTP请求得到返回的纯净json数据,直接解析json数据
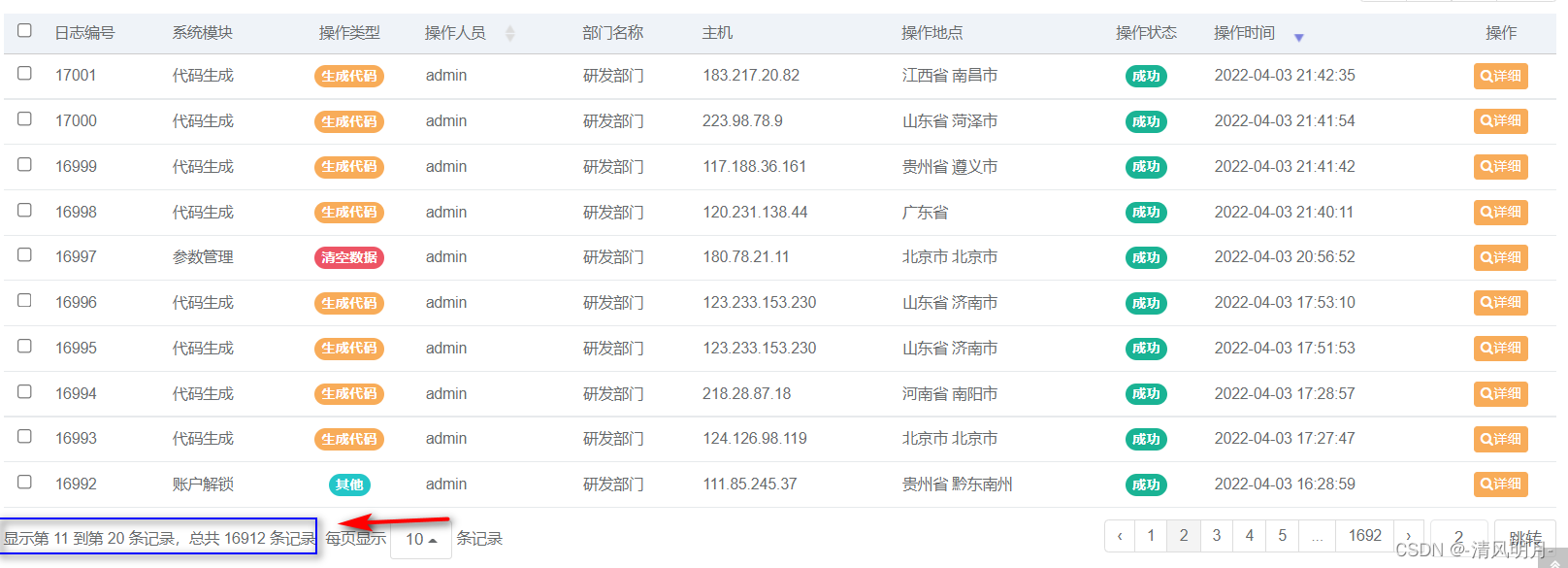
如上图所示,表格里有个元素显示 :显示第 11 到第 20 条记录,总共 16912 条记录
这里包含了记录总行数,可以用来在分页发起Request请求时计算页数,默认情况每页只显示10行数据,显然效率太低,因此可以得到分页数据,然后再构造新的请求参数数增加每页分页数量,比如可以增加到50, 页面上可以选择每页的数量最大就是50,其实自己构造请求参数应该可以设置每页显示更多,这样每次从服务器返回数据就更多,但是可能会引起不好的结果,因此还是保守采样50.
抓取分页数据,发现页面源码是这样:
<span class="pagination-info">
显示第 11 到第 20 条记录,总共 16912 条记录
</span>page_info_text = self.chrome.find_element(By.CLASS_NAME, 'pagination-info').text
page_info = re.findall(r'\d+', page_info_text)
time_str = time.strftime('[%Y-%m-%d %H:%M:%S]', time.localtime(time.time()))
print(time_str+'当前页 {0} ,获取到记录总数:{1} '.format(page_info[0], page_info[2]))
total = int(page_info[2])得到“显示第 11 到第 20 条记录,总共 16912 条记录” 这个文本之后使用正则表达式从其中分析出第3个数字就是记录总数,然后转换成int类型,作为计算分页的总数,
计算分页的公式:总页数=(记录总数+页大小-1)/页大小
得到总页数之后就可以构造一个循环机构,请求每一页的数据,代码中用到了range来构建循环的页码范围,但是有这种情况,例如
for i in range(1,5):
print(i)只会输出1到4,因此总的页数需要+1才能取完所有数据
pages = int((total + page_size - 1) / page_size) + 1根据前面的分析,查询分页数据时,会请求http://demo.ruoyi.vip/monitor/operlog/list这个url,因此可以构建下面的请求参数:
fake_parameters = {
'pageSize': page_size, # 每一页的行数
'pageNum': page_no, # 当前页码
'orderByColumn': 'operTime',
'isAsc': 'desc',
'title': '',
'operName': '',
'status': 0,
'businessTypes': ''
}在本案例中构建了一个spider_request()方法专门用来发起自定义了请求参数和Http header的post请求
# 封装一个请求,用requests发送请求
def spider_request(self,page_size, page_num, request_url, referer_url, fake_parameter):
'''
这里封装了一个独立的请求方法,实现以下功能:
1.从本地加载cookie
2.组装header参数
3.组装请求参数
4.提交请求
5.得到http response响应之后返回数据用utf-8解码
'''
# 从本地加载cookie
fake_cookies = self.load_cookie();
fake_header = {
'Referer': referer_url,
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
}
# 保持会话
session_ = requests.session()
# 组建新的请求参数、cookie
response_data = session_.post(request_url, params=fake_parameter, headers=fake_header, cookies=fake_cookies)
response_data.encoding = 'utf-8'
response_json = response_data.json()
return response_json在这个方法中先用self.load_cookie()从本地加载cookie,然后构建了一个header,里面需要指定Referer参数,该Referer会告诉服务器我是从哪个页面链接过来的。以免这个请求被服务器阻拦。然后是向服务器发送post请求,这个请求中参数、header都是组装的。发完请求后对响应的结果进行编码设置为utf-8格式,最后返回json数据,
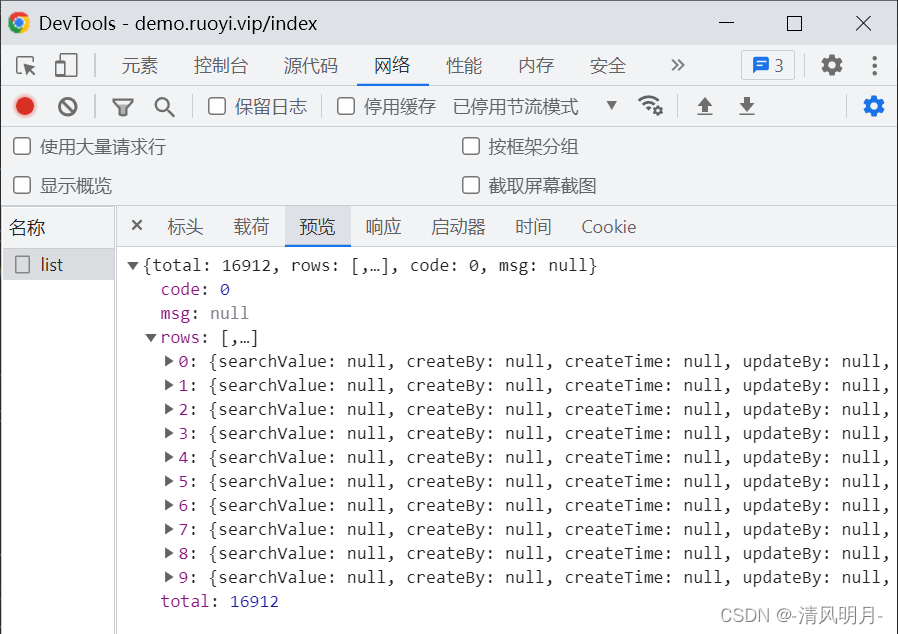
返回的json格式是这样,但是如果是最后一页时,返回的数据中rows=null,因此需要判断是否空,
# 最后一页里面rows=null ,因此需要判断是否为空,是空时返回
if not rows:
break
for row in rows:
record = [row['operId'], row['title'], row['businessType'],
row['operName'], row['deptName'], row['operIp'],
row['operLocation'], row['status'],row['operTime']]
reccords.append(record)然后就是遍历rows,根据key取数据了,因此可以得到比从分析dom得到更多的数据。
在本案例中日志操作、登录日志使用了方案2进行爬取,其中日志操作也有方案1的实现,其他的模块的爬取都是方案1的实现方式。
其实还有很大可以改进的地方,比如:
1. 使用多线程爬取各个模块
2. 使用多线程分段爬取分页数据
3. 动态变化header,以便模拟更贴近真实情况的请求。防止被服务端禁止IP
4. 使用动态IP代理,防止被禁止IP
这个案例的完整源码已经提交到码云:地址:https://gitee.com/gitlaowang/spider.git














 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









