







 ResNeXt作为ResNet的改进版,主要通过引入Group卷积更新了block结构,提高了模型性能。本文深入解析了ResNeXt的block设计原理、网络结构及参数配置,展示了其在ImageNet数据集上的优秀表现。
ResNeXt作为ResNet的改进版,主要通过引入Group卷积更新了block结构,提高了模型性能。本文深入解析了ResNeXt的block设计原理、网络结构及参数配置,展示了其在ImageNet数据集上的优秀表现。
论文:Aggregated Residual Transformations for Deep Netral Networks

0 序言
ResNeXt网络可以理解是ResNet网络的小幅升级,个人感觉这篇论文改进的点比较少,主要是更新了block。

- 对于
ResNet50/101/152甚至更高层数的网络,我们都是使用左边这个残差结构。这个结构也非常简单,假设对于我们输入channel为256的特征矩阵,首先采用64个1x1卷积核对它进行降维使得channel变为64,然后通过64个3x3的卷积核对它进行卷积处理,紧接着通过256个1x1的卷积核对它进行升维输出。输出与我们的输入进行相加,就得到我们最终的输出。 - 在ResNeXt网络中,使用右边的残差结构来替代ResNet的残差结构,关于残差结构详细内容,后文会进行详细讲解。
性能对比

- 对于ResNeXt101网络,在输入
224x224的图像尺寸下,比我们原始的ResNet-101以及ResNet-200的效果更好。在输入图像分辨率为320x320/299x299,它的效果比inception-v3,inception-v4,ResNet-200等网络的效果更好。
接下来看如下的两幅图

- 左边这幅图它统计的是ResNet50以及ResNeXt-50在ImageNet上的Top1错误率,我们看下验证集上的错误率,其中蓝色、橙色实线对应的是ResNet50和ResNeXt-50的Top1错误率,
明显ResNeXt50比ResNet50效果更好(ResNet50和ResNeXt50在相同计算量下的对比)。 - 左边这幅图它统计的是
ResNet101以及ResNeXt-101在ImageNet上的Top1错误率,同样在相同计算量情况下ResNeXt的效果会更好些。
Group卷积介绍

- 图片上半部分是
普通卷积的流程,假设输入特征矩阵的channel为4,此时对于每一个卷积核它的channel需要与输入特征矩阵的channel保持一致,所以卷积核的channel=4.假设输出的特征矩阵channel=n,也就意味我们需要n个卷积核进行卷积处理。我们计算普通卷积所需要的参数量,假设卷积核的高宽为k,假设输入特征矩阵channel为 C i n C_{in} Cin, 输出的channel 为n,总的卷积参数量为:
k × k × C i n × n k \times k \times C_{in} \times n k×k×Cin×n - 下半部分对应的就是组卷积(
Group Convolution),我们同样假设我们输入特征矩阵的channel为4,并将输入特征矩阵划分为2个组,对每个组分别进行卷积操作。第一个组而言他的每个卷积核的channel需要与输入卷积channel保存一致,因此它的channel个数为2,假设使用 n / 2 n/2 n/2个卷积核,通过第一个Group卷积可以得到channel=n/2的特征矩阵。同理下边这个组它同样采用n/2个卷积核,那么它的输出特征矩阵的channel也是等于 n / 2 n/2 n/2的。然后对两个组的输出矩阵进行concate拼接,那么它最终得到的特征矩阵等于n。 - 接下来我们来计算采用
Group Convolution时所需要的参数个数,假设每个卷积核的高和宽为k,并且输入特征矩阵的channel= C i n C_{in} Cin,将输入特征矩阵分为g组,对于每个group它的输入特征矩阵channel就为 C i n g \frac{C_{in}}{g} gCin。通过Group Convolution输出的特征矩阵的channel假设为n的话,对于每个group而言,则它的输出channel应该为n/g,它所采用卷积核的参数为:
k × k × C i n g × n g k \times k \times \frac{C_{in}}{g} \times \frac{n}{g} k×k×gCin×gn
由于我们划分为g个组,所以卷积的参数量为:
( k × k × C i n g × n g ) × g = k × k × C i n × n × 1 g (k \times k \times \frac{C_{in}}{g} \times \frac{n}{g}) \times g=k \times k \times C_{in} \times n \times \frac{1}{g} (k×k×gCin×gn)×g=k×k×Cin×n×g1
所以采用group卷积之后,它的参数个数是普通卷积的
1
g
\frac{1}{g}
g1,这里的g表示我们采用的Groups数。
当我们分组的个数g与输入特征矩阵的channel
C
i
n
C_{in}
Cin是保持一致的话,并且输出特征矩阵的channel与输出特征矩阵的channel保持一致的话,这就相当于对我们输入特征矩阵的每一个channel分配一个channel为1的卷积核进行卷积。满足
g
=
C
i
n
,
n
=
C
i
n
g=C_{in} ,n = C_{in}
g=Cin,n=Cin,此时就是DW Conv
ResNeXt网络结构
ResNeXt Block

原论文作者给出了上面a-c三种block结构,这些block在数学计算上是完全等价的。
- 首先看下最简的形式( c ),首先通过一个
1x1的卷积层对他进行降维处理,将它的channel从256降低到128,然后在通过group卷积进行处理,这里group 卷积的卷积核为3x3它的groups数为32,它所输出的channel也是等于128,然后通过1x1卷积对它进行升维,然后将它的输出与我们的输入进行相加得到我们的输出。 - 接着我们简单分析下,为什么这3个block模块在数学上是等价的,首先我们看下从(b)到( c )这个过程,对于(b)中第一层通过包括32个分支,每个分支(path)卷积核个数为4的
1x1卷积,对于每个path而言它的卷积核大小都是1x1channel为256,又由于我们path的个数为32,就可以简单将他们合并在一起,变为( c)图中第一层 卷积核大小为1x1channel为256,个数为128的卷积层了。 - 对于图(b)的第二层,和group卷积其实是一样的,对于每个path可以理解为一个group,每个组的输入输出channel为原来的
1/g,对于每个组采用3x3的卷积核,卷积之后将特征矩阵进行concate拼接,所以图(b)第二层也是与图(c )第二层 group为32的组卷积也是等价的。 - 接下来看下(a) 和(b)是如何等价的,通过我们的观察可以发现它是将下图框标识出来部分进行等价。图a 框中表示先对每个path利用
1x1卷积,然后再进行Add相加。与 图( c)先进行concatenate拼接,然后再直接通过1x1卷积输出其实是等价的。
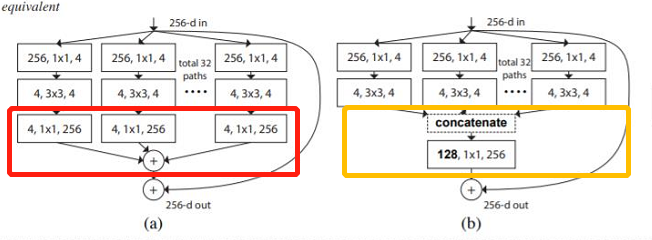
这个其实不是那么好理解,这里通过一个例子说明这种等价关系。

这里假设path=2,对于每个path采用1x1的卷积核进行卷积,对两个path卷积后的结果进行相加得到输出的特征矩阵。这就是图(a)红框部分对于每个path通过1x1卷积核进行卷积然后再进行相加处理;
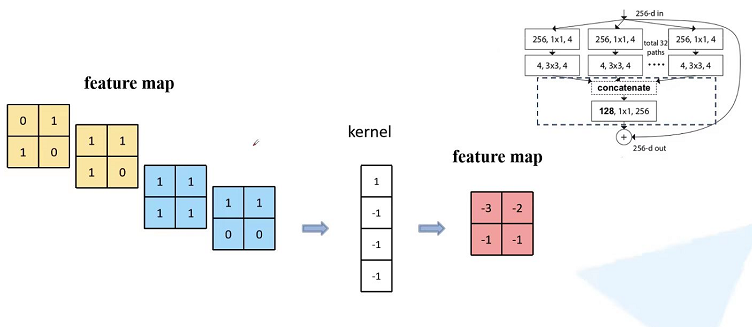
上图是图(b)框出来的部分讲解:这里讲我们刚刚讲的两个path的特征矩阵进行拼接,就得到了channel=4的feature map, 我们这里使用的kernel也是为1x1大小的,kernel的参数与上面例子是一样的,也是1,-1,-1,1.然后通过1x1卷积得到的feature map 和我们刚刚讲的是一样的。所以说图(a)和图(b)在数学计算上也是等价的
ResNeXt 网络结构

- 上图是论文给出的ResNeXt50的参数列表,通过这个表格就能搭建出ResNeXt50,下面对表格参数进行说明
ResNeXt-50(32x4d),这里的32表示groups数,可以看到对于conv2~conv5所对应的一系列block的Grops也就是C的个数都是32.这里的4d表示conv2所对应的这一系列block的组卷机中每个组所采用的卷积核个数。- 通过这个表我们可以看到它的大致框架都是一样的,都是讲我们的block进行重复堆叠,堆叠的个数与ResNet50也是一模一样的(3,4,6,3)。后面同样是接一个全局池化,以及全连接层和softmax激活输出。同时可以看出ResNet50和ResNeXt50的餐数量和计算量也是差不多的
- 所以搭建ResNeXt只需要将ResNet的block替换为ResNeXt的block就可以了
原论文为啥将groups设置为32?

作者研究了C和d的不同搭配(上图所示),在保持相同计算量的前提下,并且对比了不同C和d搭建的网络的效果。可以看出随着Groups数 C的增加,我们发现它的top1 错误率是越来越低的,同样在101层的网络中也是随着C的个数不断增加,我们发现它的top1 错误率是越来越低的,所以原论文中作者ResNeXt50它所采用的配置就是32 x 4d

浅层网络的Block

- 在ResNet网络中,对于浅层比如18,34层的网络而言,其实是通过上图左边的block结构进行堆叠的,即2层
3x3的卷积层进行搭建block的。 - 在原论文中,作者有说只有当block的层数≥3的时候,我们才能构建出一个比较有意义的block。对于ResNet 中浅层网络只有2层的block而言,如果我们还是利用ResNeXt的block(如上图右边),先对层进行拆分,再进行卷积,再进行相加,那么计算上是等价的,等价之后可以发现还是普通的卷积,只是卷积核个数变多了而言(64变为128)
- 所以
对于block层数小于3而言,ResNeXt block是没有多大作用的
总结
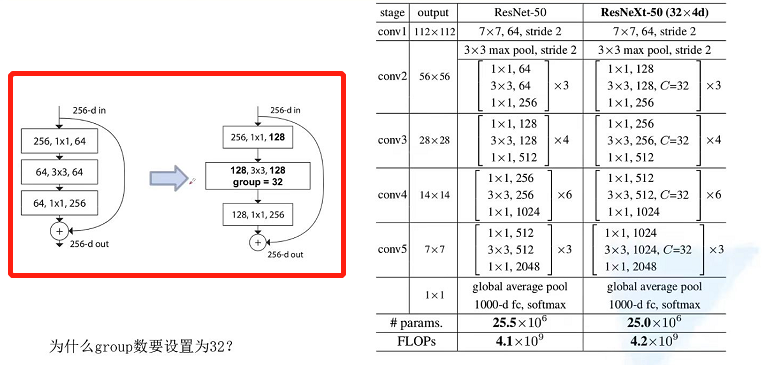
ResNeXt相比于ResNet只是将红框中原来的Res Block替换为右边ResNeXt的block,并且作者尝试了不同的groups数


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











