









1.GroupBy对象创建
# 测试数据
import pandas as pd
fortune = pd.read_csv("fortune1000.csv")
fortune.head()
创建单列GroupBy对象,使用get_group()提取数据
# 创建单列GroupBy对象,使用get_group()提取数据
sector = fortune.groupby("Sector")
sector.get_group("Apparel")
创建多列的GroupBy对象,使用元组提取数据
# 创建多列的GroupBy对象,使用元组提取数据
sector2 = fortune.groupby(["Sector","Industry"])
sector2.get_group(("Energy","Petroleum Refining"))
2.GroupBy对象属性
len()
sector = fortune.groupby("Sector")
# len属性 表示 fortune 里 Sector的类型数量
len(sector), fortune["Sector"].nunique() == len(sector)
(21, True)
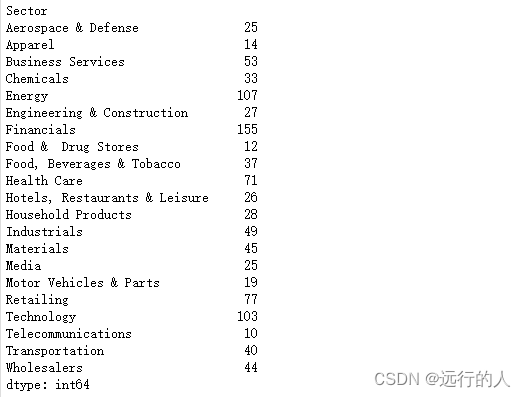
.size()
# size() 每种类型的数量
sector.size()
3.GroupBy对象方法
提取数据方法(注意:提取前一般先排序)
# first() 提取类型第一条数据
sector.first()
# last() 提取类型最后一条数据
sector.last()
# nth(n) 提取类型第n条数据,第一条n为0
sector.nth(5)
# head(n) 提取类型前n条数据,默认n=5
sector.head(3)
# tail(n) 提取类型最后n条数据,默认n=5
sector.tail(3)
聚合方法
max:求最大
min:求最小
mean:求平均值
sum:求和 等等
注意:结果是每列上的最大值,他们之间没有联系
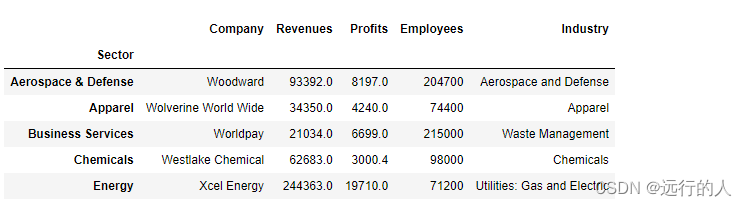
# 注意:结果是每列上的最大值 他们之间没有联系
sector.max().head()
选取指定列
# 单列
sector["Employees"].max()
# 多列
sector[["Employees", "Profits", "Revenues"]].max()
# 所有列
sector.max()
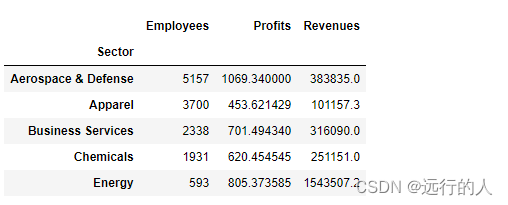
agg() 传入一个字典参数,为指定列提供指定的聚合方法
agg_dict = {
"Employees":"min",
"Profits":"mean",
"Revenues":"sum"
}
sector.agg(agg_dict).head()
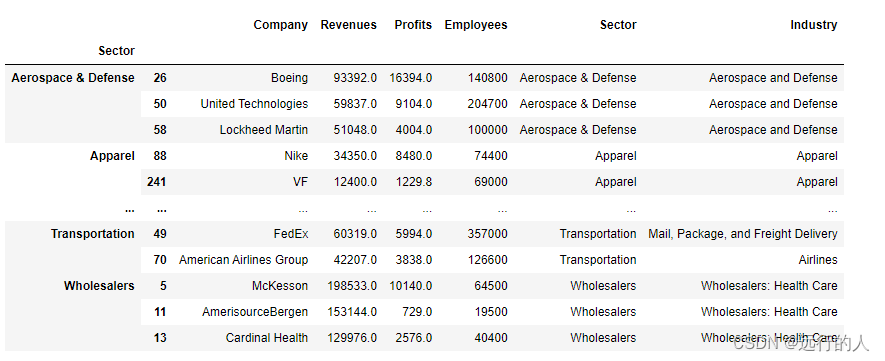
apply() 传入一个自定义函数,对GroupBy对象每个分组进行操作
注意:自定义函数只接受一个DataFrame参数
## 分组前三Profits翻倍
def double_Profits(df):
df_3 = df.head(3)
df_3['Profits'] = df_3['Profits']*2
return df_3
sector.apply(double_Profits)















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









