









pivot_table() 主要字段
index = 行索引
columns = 列索引
values = 显示的值
aggfunc = 值的聚合方式(默认的是求平均)
fill_value = 当出现nan值时,用什么填充
margins = 总计
margins_name = 总计的名称
首先导入测试数据
sale = pd.read_csv("sales_by_employee.csv", parse_dates=['Date']).head()
sale.nunique()
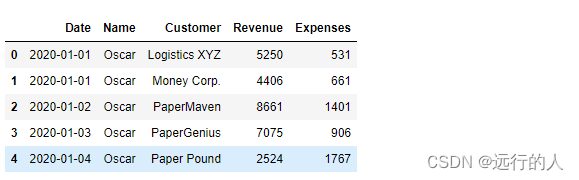

index字段
# index字段 作为行索引
sale.pivot_table(index='Date')
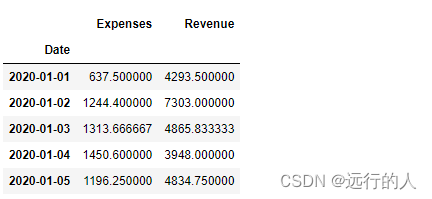
# index字段 多个字段作为多重索引
sale.pivot_table(index=['Date','Name'])
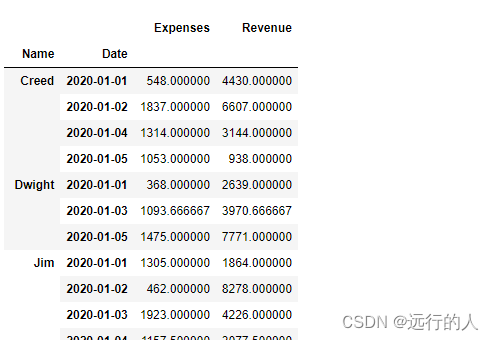
sale.pivot_table(index=['Name','Date'])
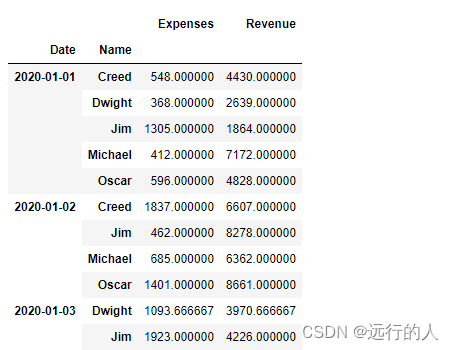
# index字段 多个字段作为多重索引,对调效果不同
sale.pivot_table(index=['Name','Date'])
columns字段
# columns字段 作为列索引
sale.pivot_table(index='Date', aggfunc="sum", columns='Name')
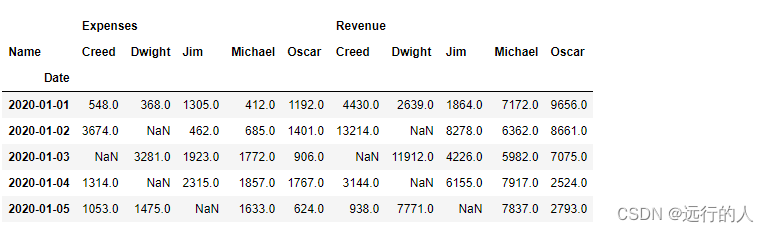
aggfunc字段
# aggfunc字段 聚合函数 默认是mean 平均值
# count 计数 sum 求和
sale.pivot_table(index='Date', aggfunc=["count","sum"])
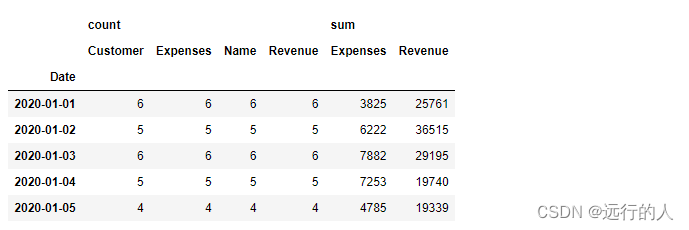
# aggfunc 可以传入一个字典,对显示的值采取不同的聚合函数
sale.pivot_table(index='Date',
values=['Revenue','Expenses'],
columns='Name',
aggfunc={'Revenue':"sum", 'Expenses':"count"}
)
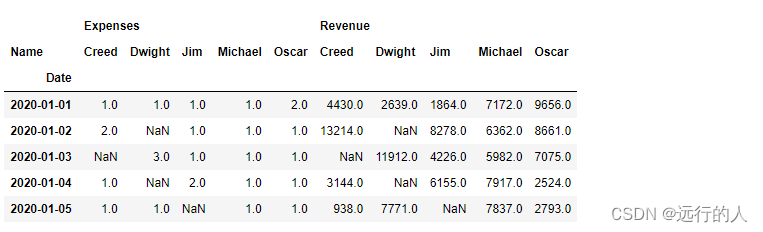
values 字段、fill_value 字段
# values 字段 显示的栏目,多个栏目时也是使用列表形式,下面只显示Revenue
# fill_value 字段 当值为Nan时填充的值
sale.pivot_table(index='Date',
aggfunc="sum",
columns='Name',
values='Revenue',
fill_value=0
)
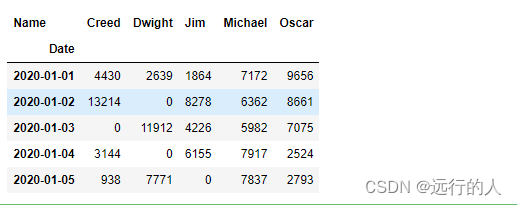
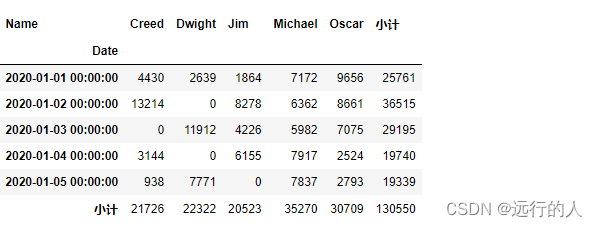
margins 字段、margins_name 字段
# margins 字段 显示小计 默认=False
# margins_name 字段 显示小计的名称
sale.pivot_table(index='Date',
aggfunc="sum",
columns='Name',
values='Revenue',
fill_value=0.0,
margins=True,
margins_name='小计'
)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









