









pandas连接
1.concat()
字段 objs = [t1,t2,…],连接的数据
字段 ignore_index, 索引重置,默认=False
字段 keys = [k1,k2,…],对应objs,生成(k1,表1索引)的多重索引作为连接后数据表的索引
字段 axis ,连接方向 默认=0,行方向;=1,列方向
import pandas as pd
groups1 = pd.read_csv("meetup\\groups1.csv")
groups2 = pd.read_csv("meetup\\groups2.csv")
groups1.head()
groups2.head()
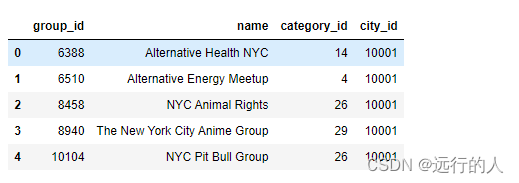
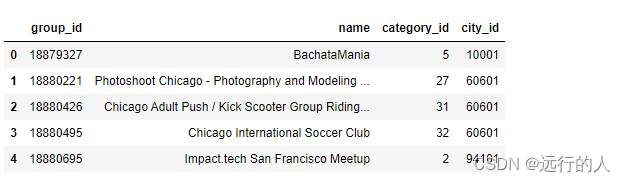
# ignore_index 默认= False,使用原来的索引,索引有重复值
pd.concat(objs=[groups1, groups2])
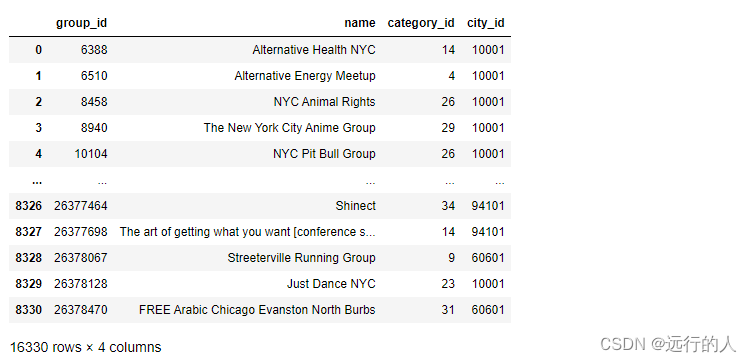
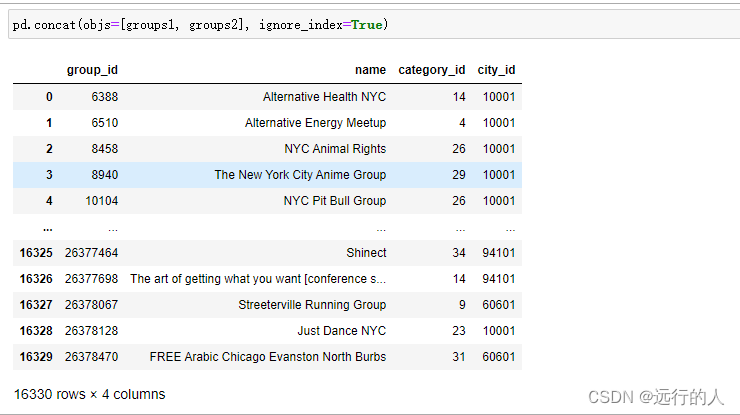
# ignore_index = True
pd.concat(objs=[groups1, groups2], ignore_index=True)
# 生成多重索引作为新表索引
pd.concat(objs=[groups1, groups2], keys=['Group1', 'Group2'])
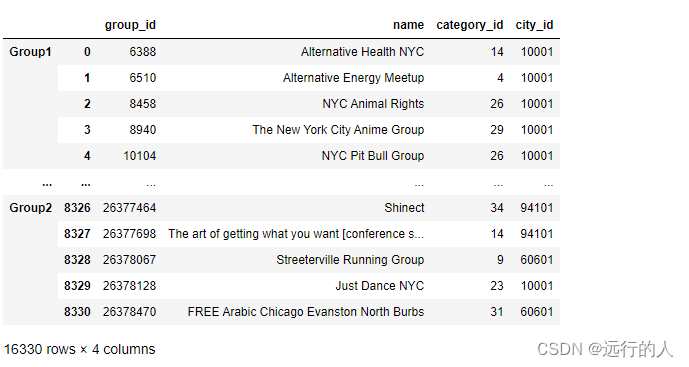
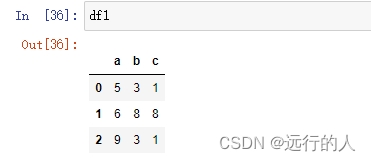
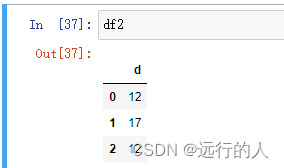
arr1 = np.random.randint(0, 10,size=(3, 3))
arr2 = np.random.randint(10, 20,size=(3, 1))
df1 = pd.DataFrame(arr1, columns=['a', 'b', 'c'])
df2 = pd.DataFrame(arr2, columns=['d'])
# axis = 0,行方向连接
# 连接后缺失部分会自动填充NaN
pd.concat(objs=[df1, df2])

# axis = 1 或 "columns",列方向连接
pd.concat(objs=[df1, df2],axis=1)
pd.concat(objs=[df1, df2],axis="columns")
















 3115
3115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









