







backward:自动求梯度。计算小批量随机梯度。
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解 叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数 深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:1.先选取一组模型参数的初始值,如随机选取;2.接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。
在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch)B,然后求小批量中数据样本的平均损失有关模型参数的导 数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
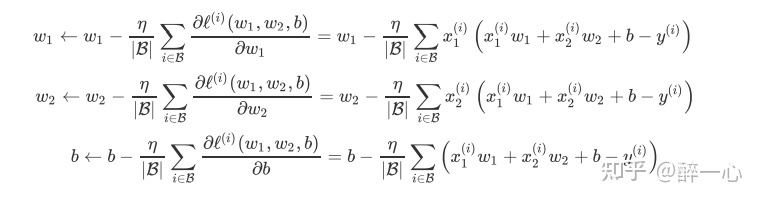
在上式中,|B| 代表每个小批量中的样本个数(批量大小,batch size),η 称作学习率(learning rate)并取正数。需要强调的是,这里的批量大小和学习率的值是人为设定的,并不是通过模型训练学 出的,因此叫作超参数(hyperparameter)。我们通常所说的“调参”指的正是调节超参数,例如通过反复试错来找到超参数合适的值。在少数情况下,超参数也可以通过模型训练学出。
梯度累积
所谓梯度累积,其实很简单,我们梯度下降所用的梯度,实际上是多个样本算出来的梯度的平均值,以 batch_size=128 为例,你可以一次性算出 128 个样本的梯度然后平均,我也可以每次算 16 个样本的平均梯度,然后缓存累加起来,算够了 8 次之后,然后把总梯度除以 8,然后才执行参数更新。当然,必须累积到了 8 次之后,用 8 次的平均梯度才去更新参数,不能每算 16 个就去更新一次,不然就是 batch_size=16 了。
定义优化函数
以下的 sgd 函数实现了上一节中介绍的小批量随机梯度下降算法。它通过不断迭代模型参数来优化 损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和。我们将它除以批量大小来得到平均值。
def sgd(params, lr, batch_size):
'''
小批量随机梯度下降
params: 权重
lr: 学习率
batch_size: 批大小
'''
for param in params:
param.data -= lr * param.grad / batch_size在训练中,我们将多次迭代模型参数。在每次迭代中,我们根据当前读取的小批量数据样本(特征 X 和标签 y ),通过调用反向函数 backward 计算小批量随机梯度,并调用优化算法 sgd 迭代模型参数。由于我们之前设批量大小 batch_size 为10,每个小批量的损失 l 的形状为(10, 1)。回忆一下自动 求梯度一节。由于变量 l 并不是一个标量,所以我们可以调用 .sum() 将其求和得到一个标量,再运行 l.backward() 得到该变量有关模型参数的梯度。注意在每次更新完参数后不要忘了将参数的梯度清零。(如果不清零,PyTorch默认会对梯度进行累加)
对于这种我们自己定义的变量,我们称之为叶子节点(leaf nodes),而基于叶子节点得到的中间或最终变量则可称之为结果节点
x = torch.tensor(1.0, requires_grad=True)
y = torch.tensor(2.0, requires_grad=True)
z = x**2+y
z.backward()
print(z, x.grad, y.grad)
>>> tensor(3., grad_fn=<AddBackward0>) tensor(2.) tensor(1.)z对x求导为:2,z对y求导为:1
可以z是一个标量,当调用它的backward方法后会根据链式法则自动计算出叶子节点的梯度值。
求一个矩阵对另一矩阵的导数束手无策。
对矩阵求和不就是等价于z点乘一个一样维度的全为1的矩阵吗?即 ,而这个I也就是我们需要传入的grad_tensors参数。(点乘只是相对于一维向量而言的,对于矩阵或更高为的张量,可以看做是对每一个维度做点乘)
【点乘:对两个向量执行点乘运算,就是对这两个向量对应位一一相乘之后求和的操作】
如:
x = torch.tensor([2., 1.], requires_grad=True)
y = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
z = torch.mm(x.view(1, 2), y)
print(f"z:{z}")
z.backward(torch.Tensor([[1., 0]]), retain_graph=True)
print(f"x.grad: {x.grad}")
print(f"y.grad: {y.grad}")
>>> z:tensor([[5., 8.]], grad_fn=<MmBackward>)
x.grad: tensor([[1., 3.]])
y.grad: tensor([[2., 0.],
[1., 0.]])结果解释如下:
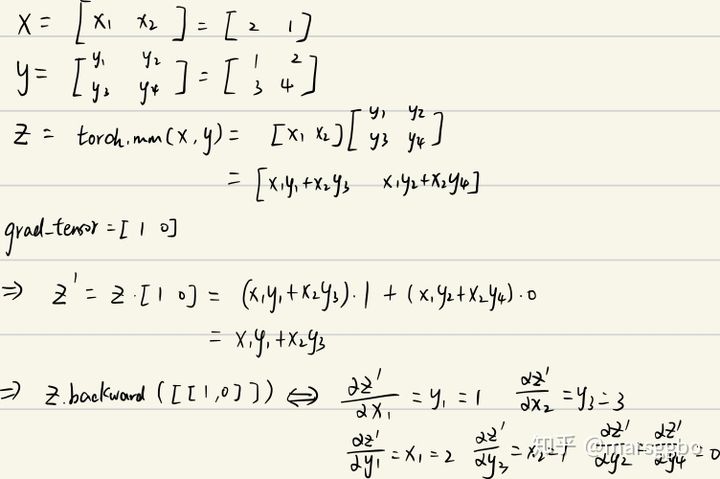
查看梯度以及参数更新的问题
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torchsummary import summary
import os
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
# 设置一下数据集 数据集的构成是随机两个整数,形成一个加法的效果 input1 + input2 = label
class TrainDataset(Dataset):
def __init__(self):
super(TrainDataset, self).__init__()
self.data = []
for i in range(1,1000):
for j in range(1,1000):
self.data.append([i,j])
def __getitem__(self, index):
input_data = self.data[index]
label = input_data[0] + input_data[1]
return torch.Tensor(input_data),torch.Tensor([label])
def __len__(self):
return len(self.data)
class TestNet(nn.Module):
def __init__(self):
super(TestNet, self).__init__()
self.net1 = nn.Linear(2,1)
def forward(self, x):
x = self.net1(x)
return x
def train():
traindataset = TrainDataset()
traindataloader = DataLoader(dataset = traindataset,batch_size=1,shuffle=False)
testnet = TestNet().cuda()
myloss = nn.MSELoss().cuda()
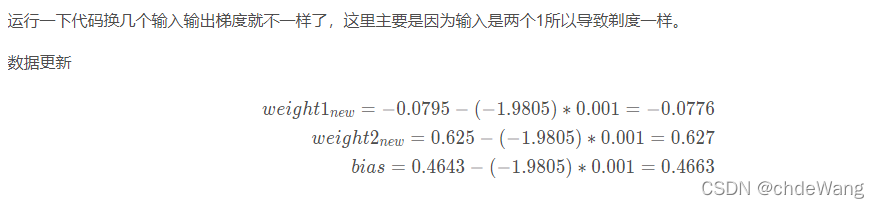
optimizer = optim.SGD(testnet.parameters(), lr=0.001 )
for epoch in range(100):
for data,label in traindataloader :
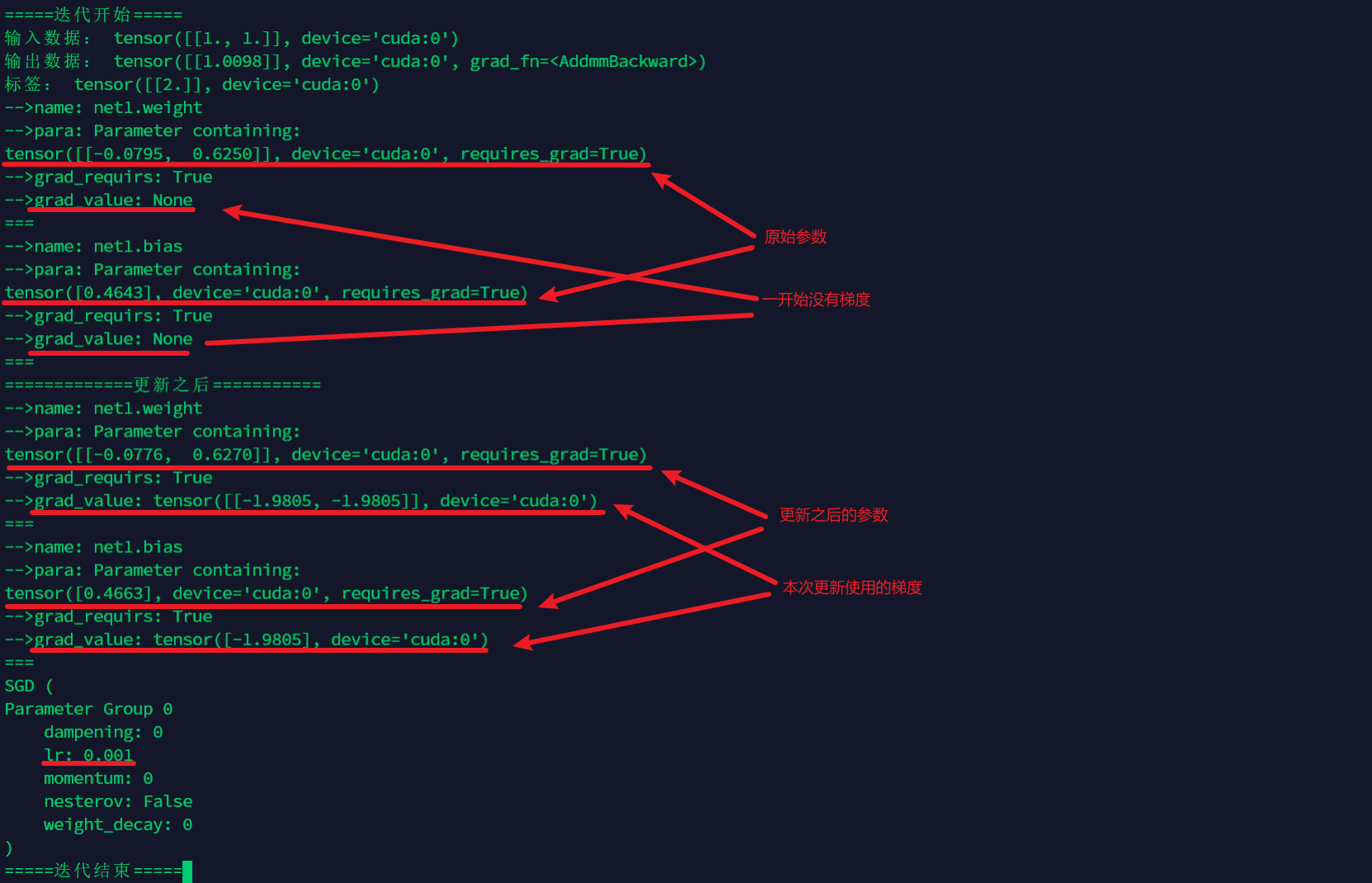
print("\n=====迭代开始=====")
data = data.cuda()
label = label.cuda()
output = testnet(data)
print("输入数据:",data)
print("输出数据:",output)
print("标签:",label)
loss = myloss(output,label)
optimizer.zero_grad()
for name, parms in testnet.named_parameters():
print('-->name:', name)
print('-->para:', parms)
print('-->grad_requirs:',parms.requires_grad)
print('-->grad_value:',parms.grad)
print("===")
loss.backward()
optimizer.step()
print("=============更新之后===========")
for name, parms in testnet.named_parameters():
print('-->name:', name)
print('-->para:', parms)
print('-->grad_requirs:',parms.requires_grad)
print('-->grad_value:',parms.grad)
print("===")
print(optimizer)
input("=====迭代结束=====")
if __name__ == '__main__':
os.environ["CUDA_VISIBLE_DEVICES"] = "{}".format(3)
train()

参考自:动手学深度学习(Pytorch)第2章深度学习基础-上 - 知乎
Pytorch autograd,backward详解 - 知乎
Pytorch 模型 查看网络参数的梯度以及参数更新是否正确,优化器学习率设置固定的学习率,分层设置学习率_呆呆象呆呆的博客-CSDN博客














 4111
4111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









