







1.资源准备
(1)jdk 版本:1.8
(2).hadoop
版本:2.10.0
下载:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
(3).hadooponwindows-master
下载:https://codeload.github.com/sardetushar/hadooponwindows/zip/master
2.安装
(1)jdk:自行安装 ,并配置好环境变量
(2)hadoop:
解压,加入系统环境变量:HADOOP_HOME值:为路径例如"D:\software\hadoop\hadoop-2.10.0"到bin文件夹上一级即可。path后加入“;%HADOOP_HOME%\bin;”
装完后打开cmd执行 hadoop version 可以看到如下信息
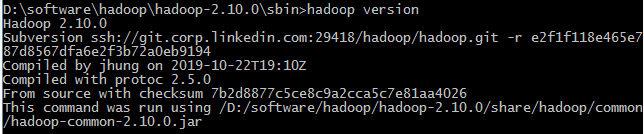
(2)hadooponwindows
解压后将bin目录 下的文件覆盖到hadoop/bin下面
3.配置
(1)core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/software/hadoop/hadoop-2.10.0/data</value>
<description>A base for other temporary directories设置默认的数据保存路径.</description>
</property>
</configuration>
(2)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
(3)hdfs-site.xml
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/software/hadoop/hadoop-2.10.0/data</value>
</property>
</configuration>
(4)yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
3.运行
(1)cmd执行hadoop namenode -format
(2)在hadoop/sbin目录下依次执行
start-dfs.cmd
start-yarn.cmd
启动后可以打开 http://localhost:50070/dfshealth.html#tab-overview

5.HDFS命令
(1)创建一个文件夹 : hdfs dfs -mkdir /myTask
(2)创建多个文件夹 : hdfs dfs -mkdir -p /myTask1/input1
(3)上传文件: hdfs dfs -put /opt/wordcount.txt /myTask/input
(4)查看总目录下的文件和文件夹: hdfs dfs -ls /
(5)查看myTask下的文件和文件夹: hdfs dfs -ls /myTask
(6)查看myTask下的wordcount.txt的内容: hdfs dfs -cat /myTask/wordcount.txt
(7)删除总目录下的myTask2文件夹以及里面的文件和文件夹: hdfs dfs -rmr /myTask2
(8)删除myTask下的wordcount.txt :hdfs dfs -rmr /myTask/wordcount.txt
(9)下载hdfs中myTask/input/wordcount.txt到本地opt文件夹中 :hdfs dfs -get /myTask/input/wordcount.txt E:\opt
6.测试
(1)创建目录:cmd中执行:
hadoop fs -mkdir hdfs://localhost:9000/user
hadoop fs -mkdir hdfs://localhost:9000/user/test
(2)上传文件
hadoop fs -put E:\test.txt hdfs://localhost:9000/user/test
(3)下载文件
下载文件到磁盘
hadoop fs -get hdfs://localhost:9000/user/test/test.txt F:\
下载文件到磁盘并重新命名
hadoop fs -get hdfs://localhost:9000/user/test/test.txt F:\test0001.txt

(4)查看文件
查看文件
hadoop fs -ls hdfs://localhost:9000/user
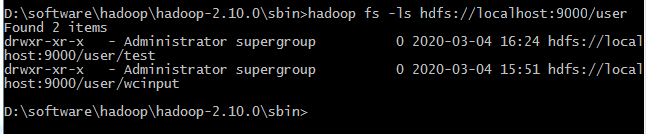 ```
```
hadoop fs -ls hdfs://localhost:9000/user/test
















 2576
2576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









