










Pytorch实现MNIST手写数据集识别
pytorch从入门到实战学习笔记
本文搭建简单的深层神经网络模型,对MNIST手写数据集进行识别。该神经网络由784个输入神经元,100个隐层神经元和10个输出神经元构成。待读者通过这个例子掌握深层神经网络特征,便可自行设计。
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
# Hypwe parameters
EPOCH = 10
BATCH_SIZE = 100 #批处理大小
LR = 0.001 #learning rate
DOWNLOAD_MNIST = False #在这里,我已经下载了MNIST数据集了,就不用再下载了,否则为True
# MNIST Dataest
train_data = torchvision.datasets.MNIST( #下载MNIST数据
root='./mnist/',
train=True,
transform=torchvision.transforms.ToTensor(), #下载的数据改成Tensor的数据 图片数据(0,255),转换为(0,1)的totensor数据
download=DOWNLOAD_MNIST
) #设置训练集
test_data = torchvision.datasets.MNIST(root='./data',train=False,transform=torchvision.transforms.ToTensor(),download=True) #设置测试集
train_loader = Data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True) #训练集中,shuffle必须为True 打乱次序
test_loader = Data.DataLoader(dataset=test_data,batch_size=BATCH_SIZE,shuffle=False)
# Neural Network Model
class Net(torch.nn.Module): # 设置DNN模型
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_feature,n_hidden) #设置 输入层到隐含层
self.relu = nn.ReLU() #激活函数
self.predict = torch.nn.Linear(n_hidden,n_output) #隐含层到输出层
def forward(self, x):
out = self.hidden(x)
out = self.relu(out)
out = self.predict(out)
return out
net = Net(784,100,10)
print(net)
# Loss and Optimizer
optimizer = torch.optim.SGD(net.parameters(),lr=LR)
loss_func = nn.CrossEntropyLoss()
Loss_list = [] #创建一个list,以便后续可视化
Accuracy_list = []
#Train the Model
for epoch in range(EPOCH):
running_loss = 0
running_acc = 0
for i, (images, labels) in enumerate(train_loader): #批处理
images = Variable(images.view(-1, 28*28))
labels = Variable(labels) #Convert torch tensor to Variable 将数据用Variable包起来输入模型中
outputs = net(images) #前向传播,将包好的数据输入net
loss = loss_func(outputs, labels) #损失函数
running_loss += loss.item()*labels.size(0) #由于loss是batch取均值的,所以把要把batch size乘回去
_,pred = torch.max(outputs,1) #预测结果
num_correct = (pred == labels).sum()
running_acc += num_correct.item() #正确结果的总数
optimizer.zero_grad() #梯度清零 以免影响其他batch
loss.backward() #反向传播
optimizer.step() #梯度更新
print('Train{} epoch, Loss: {:.6f},Acc: {:.6f}'.format(epoch + 1, running_loss / (len(train_data)),running_acc / (len(train_data)))) 输出每个epoch的 loss 和 acc
Loss_list.append(running_loss / (len(train_data)))
Accuracy_list.append(running_acc / (len(train_data)))
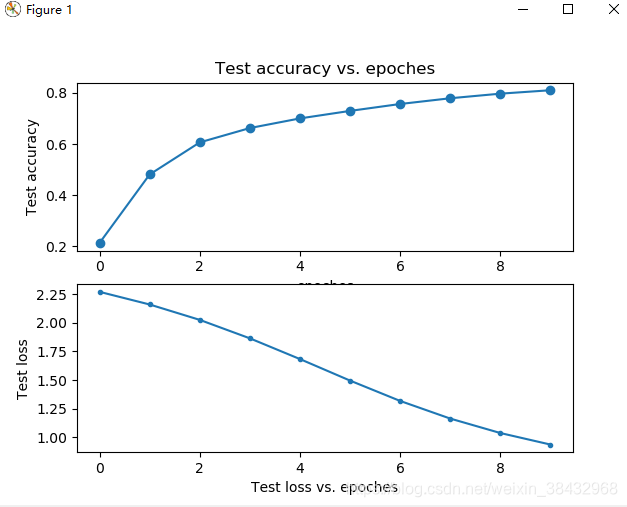
# 我这里迭代了10次,所以x的取值范围为(0,10),然后再将每次相对应的准确率以及损失率附在x上
x1 = range(0, 10)
x2 = range(0, 10)
y1 = Accuracy_list
y2 = Loss_list
plt.subplot(2, 1, 1)
plt.plot(x1, y1, 'o-')
plt.title('Test accuracy vs. epoches')
plt.ylabel('Test accuracy')
plt.subplot(2, 1, 2)
plt.plot(x2, y2, '.-')
plt.xlabel('epoches')
plt.ylabel('Test loss') #将精确率可视化的过程
#Test the model
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(images.view(-1,28*28))
outputs = net(images)
_,predicted = torch.max(outputs.data,1)
total +=labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (100*correct /total))
具体可视化过程参照:
https://blog.csdn.net/tequilaro/article/details/81841748
结果
















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









