






环境配置
关于MMPose的教程其实也挺多的,但是在环境配置的时候,发现配置的过程中参照别的教程总会有一些bug出现,所以在配置了很多遍之后,强烈建议还是按照官方的教程进行配置。
官方github环境配置文件位置mmpose/install.md at master · open-mmlab/mmpose · GitHub
下面我们就来参照官方的步骤先配置我们的环境:
第一步: 希望你已经安装好conda环境
conda create --mymmpose python=3.8 -y
conda activate mymmpose第二步: 进入pytorch官网,安转你电脑cudnn对应的torch, torchvision
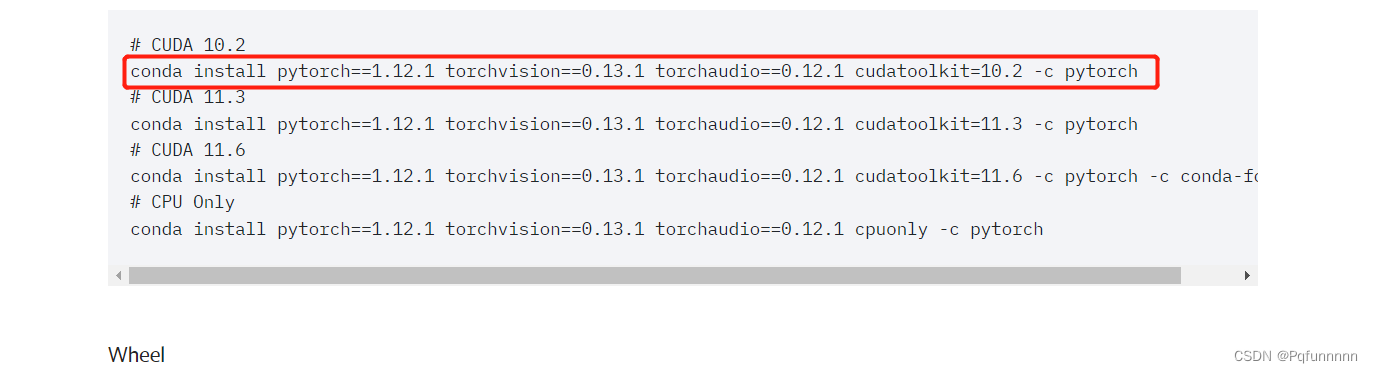
第三步: 安装mmcv-full, 这一步可能会出现一些问题,因为我在安装的时候发现
# 官方的方法:
pip install -U openmim
mim install mmcv-full
# 推荐方法:
pip install mmcv-full==1.4.5 -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.7/index.html
这里安装mmcv的库的时候,需要注意这是个大坑,直接install,可能会与torch与cuda的版本不匹配,因此这里推荐使用的方法是去官网:Installation — mmcv 1.7.1 documentation
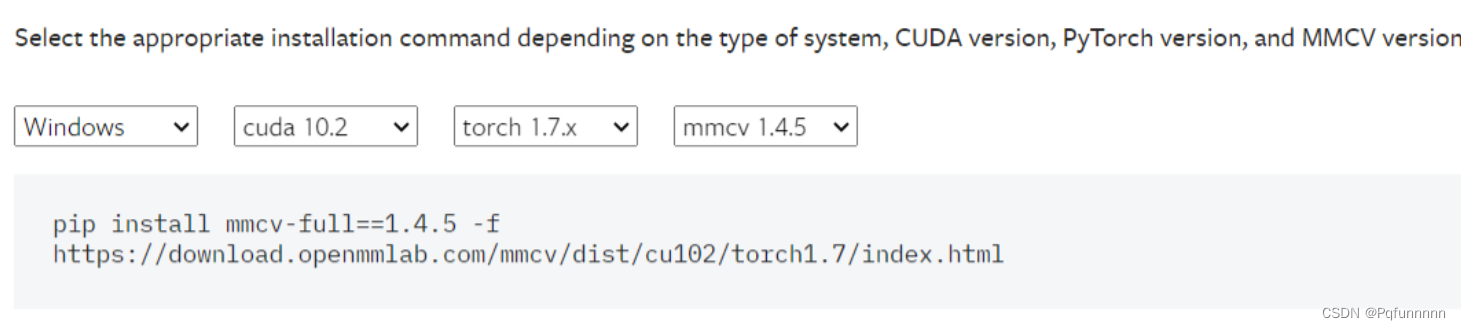
第四步: git clone mmpose 把mmpose的代码git下来,用pycharm打开,可以看到如下的文件列表:
模型运行
对于如何使用里面的模型,一开始跟着教程走的时候,我发现我只会使用识别图片的那个,但是想运行视频或者换个模型就发现不知道该怎么入手了,好找慢慢研究算是知道了该怎么运行每一个模型了
1. 首先打开demo文件,里面是分别是3d模型运行文件,自上而下模型,自下而上模型的运行文件等。

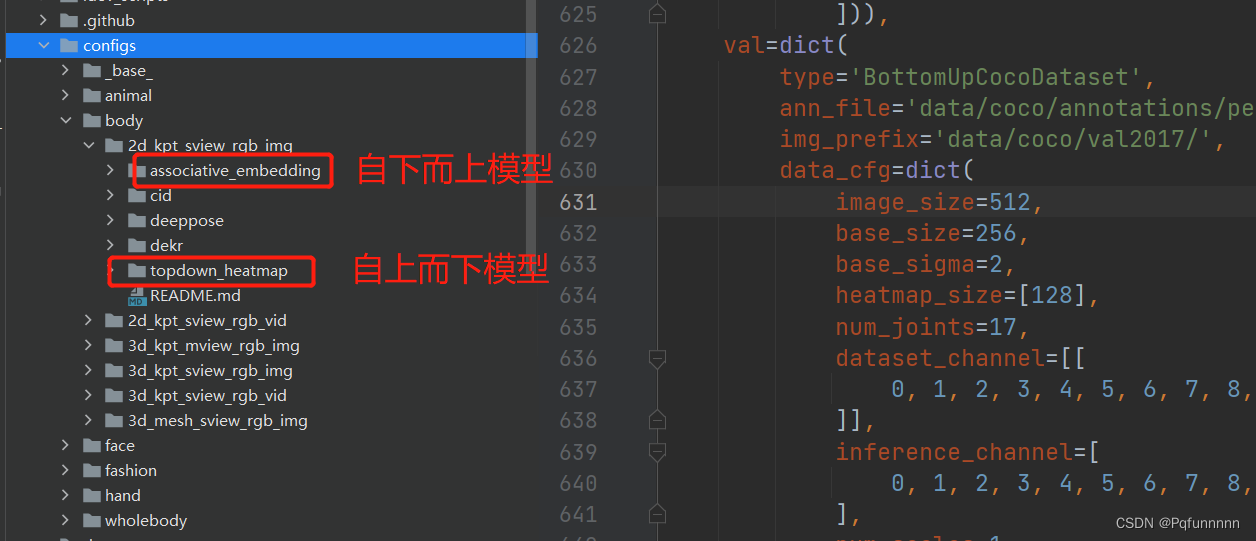
2. configs文件目录下,可以看到分别由animal, body, face, fashion, hand, wholebody等,分别是不同识别的模型的配置文件,可以看到下图给出的assoociative_embedding和topdown_heatmap两个文件夹,这两个文件夹下面的文件分别就是不同backbone对应的模型配置:
3. 模型的运行,这里给出识别单个图片和视频的运行方首先打开mmpose的官方文档,找到modelzoo里面的Backbones, 这里有所有模型的预训练权重文件,下载对应的权重文件进行识别即可:

自上而下模型:这里以hrnet_w32模型为例,先下载模型权重 ,然后将模型权重文件放到项目中,最后是自己新建一个文件夹,专门用来放置各个模型的权重文件。
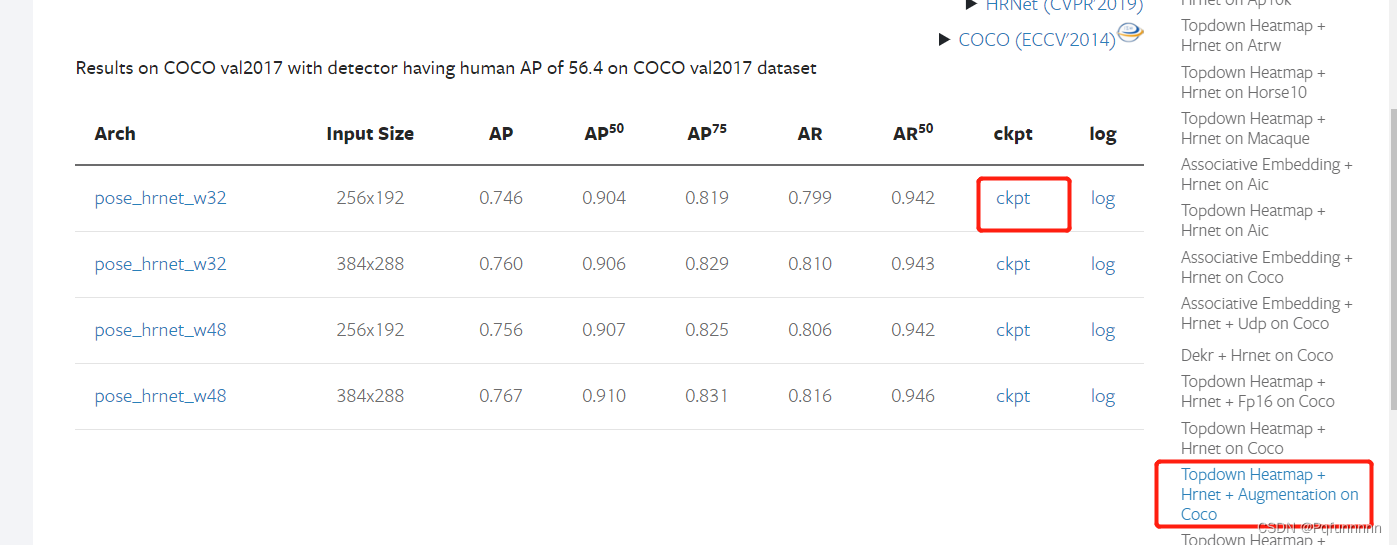
下面就是导入一个视频或者一张图片,进行推理:
- 第一个参数:./demo/top_down_video_demo_full_frame_without_det.py 表示使用的是自上而下的模型,对视频进行识别,并且是不需要mmdection的;
- 第二个参数:./configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288.py 这个文件就是刚才下载的权重文件对应的模型配置文件,位于configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco文件夹下,找到对应的模型配置文件;
- 第三个参数:./demo/weights_files/hrnet_w32_coco_384x288-d9f0d786_20200708.pth 刚才下载好的权重文件的位置;
- 第四个参数: --video-path ./demo/mytest/p3.mp4 需要识别的视频的位置
- 第五个参数: --out-video-root mytest/ 输出的识别结果的视频的位置
识别图片只需要将第一个参数改为: bottom_up_img_demo.py 以及后面的文件改为需要识别的图片的路径即可
python ./demo/top_down_video_demo_full_frame_without_det.py ./configs/body/2d_kpt_
sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_384x288.py ./demo/weights_files/hrnet_w32_coco_384x288-d9f0d786_20200708.pth --video-path ./demo/myt
est/p3.mp4 --out-video-root mytest/
自下而上的模型:
方法跟上面是一模一样的,找一个bottom-up的权重文件,找到对应的模型配置文件,进行训练即可,不过多赘述了。
最后就是为什么只介绍top-down和bottom-up模型呢,因为我目前看的就是这两种模型,还没有去试过别的,我也尝试了不同的模型识别人的效果,个人测试的效果是,同样使用hrnet模型,top-down和bottom-up的推理速度相差很大,在70s共计1200帧左右的视频上进行识别,top-down的速度为80秒左右,而bottom-up的速度为1800秒左右,可以说相差是非常大的,目前还没有研究是什么原因,因为我目前只是吧项目跑通了,还没有研究到底是个什么构造,为什么会有这么大的差别也不是很明白..................















 1487
1487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









