







今天我们要讨论损失函数(loss function)与优化器(optimizer),上周我们说到了线性分类器,我们将图片当成一个矩阵放入计算机中,其次我们寻找一个权值矩阵W,这个W我们可以当做是每一行像素的得分来理解,然后根据这个W与我们的数据矩阵进行点积,最终算出一个得分,其实在于深度学习中,我们所要做的工作就是寻找这么权值矩阵。
对于任意一个W矩阵,我们都会得到一个得分,就如下图中。我们可以看到如果一个好的W中,我们计算出的得分应该在他对应得正确的那一类中取得最高分,但是这是我们对应如下图像中人眼中看出来的,我们要写一个自动的能判断好坏的W的方法,所以自然而然的过度到了损失函数,损失函数,表示我们通过W计算的结果与真实结果的差别,所以我们要得到这个能使损失达到最小的W值。

当我们有了损失函数的概念的时候,我们就可以定量的衡量任意一个W,到底是好还是坏,我们要从W的可行域中找到W取什么值,会是最不坏的情况,而这个过程会是一个优化的过程。接下来我们举个栗子。
我们假设有三个训练样本,以及三类,下面这个cat与frog的分类是不对的,car的分类是正确的,然后我们通过定义损失函数L_i,qL_i函数中的变量一个就是我们通过W计算出来的值还有一个就是我们真是的label,来定量的描述训练样本的预测的好不好,最终的损失函数L是在整个数据集中N个样本的损失函数的和的平均值,这是很通用的公式,可以衍生到图片分类以外的问题,对任何问题这可以说是一个通用的设置,有了x跟y,你想用一个函数定量的描述出参数W是否让人满意,然后再所有的W中找到在训练集上损失函数极小化的W。

接下来我们以多分类的svm为栗子,我们看一下它的loss function,多分类的svm是处理多分类时候的一种推广,例如二元的svm,我们只有两个类,每个样本x,要么是正例,要么是负例,但是现在我们有多个类别了,我们想要,将这个概念推广到多分类的问题。首先我们先看单分类的损失函数,我们的计算方式如下图,除了真实的分类Y_i以外,对所有的分类Y都做加和,也就是说我们在所有错误的分类上做和,比较正确分类的分数和错误分类的分数,如果正确分类的分数比错误分类的分数高于某与安全的边距,我们把这个边际设为1,如果真实的分数很高,或者说真实分类的分数比任何错误分类的分数都要高很多,那么损失为0,接下来把图片对每个错误分类的损失加起来,就可以得到数据集中这个样本的最终损失,然后还是对整个训练集取平均。我们把它缩写成max(0,S_j-S_yi+1)(不懂?我也不懂,明天再细细研究下,忘了。。。),

当我们用图像表示,hinge loss,svm的损失函数,图像如下,这个名字来源于函数的图像,我们画出图像以后,这里x轴表示S_yi,是训练样本真实分类的分数,y轴是损失,可以看出随着真实分类的分数提升,损失会线性下降,一直到分数超过了一个阈值,损失函数就会是0,因为我们已经对这个样本成功的分对了类。

ps:课堂上一个学生问了老师:"老师,你这个公式到底是在计算什么?"其实,我也不知道,但是我们来个栗子看看,我们就知道,这个式子是怎么用,以及算什么了,大体的说,这个损失是在说如果真实分类的分数比其他的分数高很多,我们就很满意,那高很多,是高多少呢?这就需要高一个安全的边距,如果真实分类的分数,没有比其他分数高的多,那么我们会得到一些损失,这样是不好的情况,好了,我们来看下面图中的例子。首先这是一个猫的loss,我们就按公式,算出他的Li。

对于car来说,因为我们求出得分中,也是car的分数最高,我们算出来,其loss也是0.

再到frog,我们算出其loss为

最后我们求出这些不同样例的loss平均值。这5.27就反映了我们的算法是多么的不好,

接下来我们用一小段代码,来实现这个hinge loss.

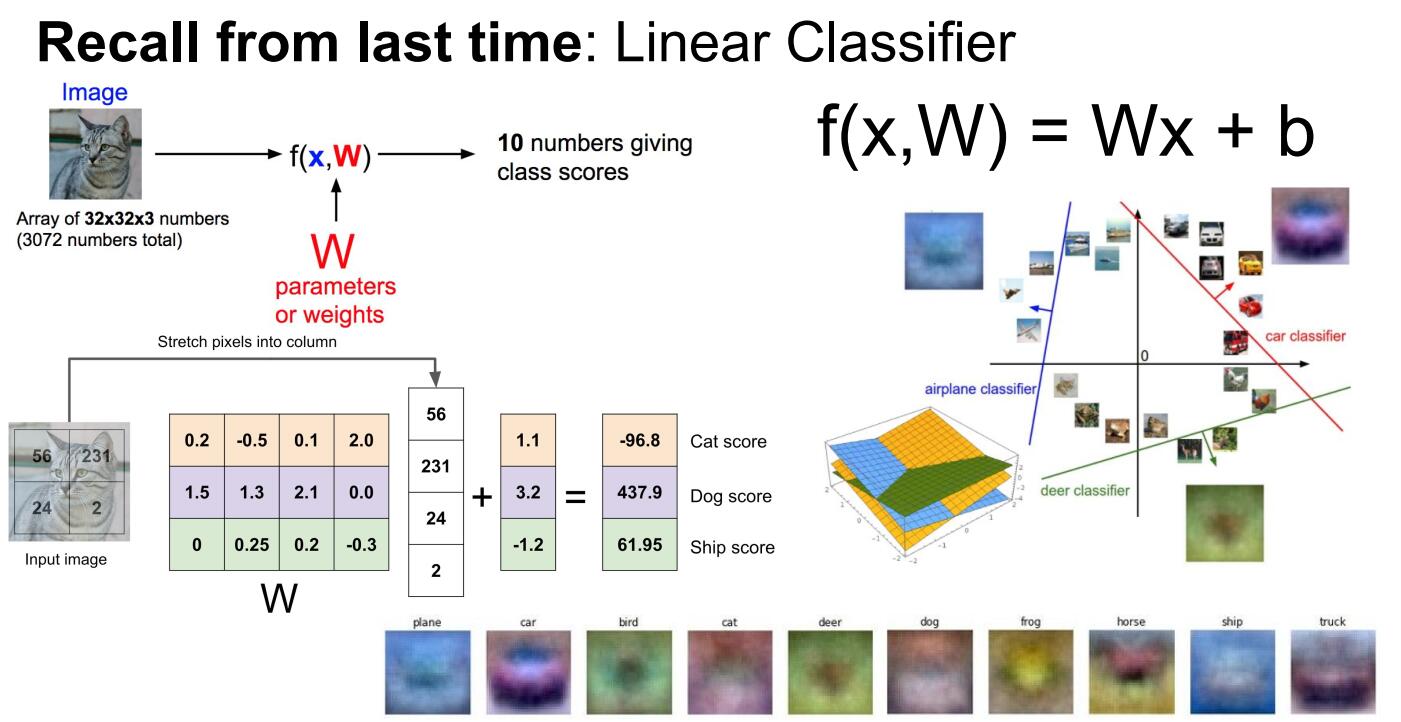
再说到loss function的时候,除了高数分类器,需要拟合训练集之外,我们通常会添加一项,也就正则化项,用来鼓励模型以某种方式选择更简单的W,这里所谓的简约,取决于任务的规模跟模型的种类,我们运用这种直观的方式在基于这一思想并运用于机器学习中,我们会直接假设正则化惩罚项,这通常记为R,这样一来,标准损失函数就有了两个项,数据丢失项跟正则项,这里有一些超参数拉姆达,用来平衡这两个项,最后是整个模型会变得简单,减少过拟合。
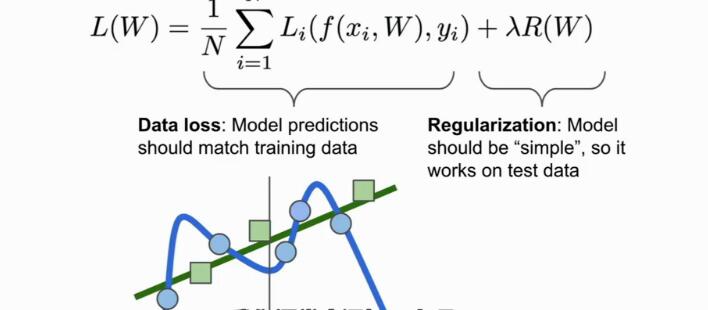
接下来我们说一下logistic regression或者叫softmax loss,回想一个多类别的svm函数的背景,针对那些得分,我们并没有一个解释,当我们进行分类时,我们的模型函数F,给我们输出了10个数字,这是每一类的得分,但是我们并对这些数字,没有一个直观的理解,我们只是说想要得到正确分类下的得分,我们通过softmax函数来算出属于这一类的概率。这是我们得到最直观的理解,比如我们对于cifar10,里面有十分类,我们输入一张图片,算出属于猫的概率是百分之80,我们就可以判定,我们认为这是一只猫。其中softmax函数如下,其中我们用指数运算,将其所有的指数运算之和作为分母,每个类别的指数化后除以分母,得到属于这一类别的概率。

现在我们需要做的是去促使我们计算得到的概率分布,即我们通过softmax计算得到的结果去匹配下面的目标概率分布,即正确的类别应该具有几乎所有的概率,你可以用多种方式来列这个方程,你可以在目标概率分布于计算出的改了吧分布间计算KL散度,以比较他们的差异,你可以去做一个最大似然估计,但是今天,我们真的想要的是真实类别的概率应该比较高并且接近于1,然后我们的损失函数就是真实类别概率的对数再取负值,直观理解我们可以想象一下log函数的曲线,我们loss函数是log函数之后取负数,所以我们要得到log函数的值最大,这时候取负数得到最小值,所以,就需要我们的概率最大,趋近于1,。

接下来继续看这个栗子,我们算出它的softmax 损失函数的值,好,都看得懂哈~~~~~

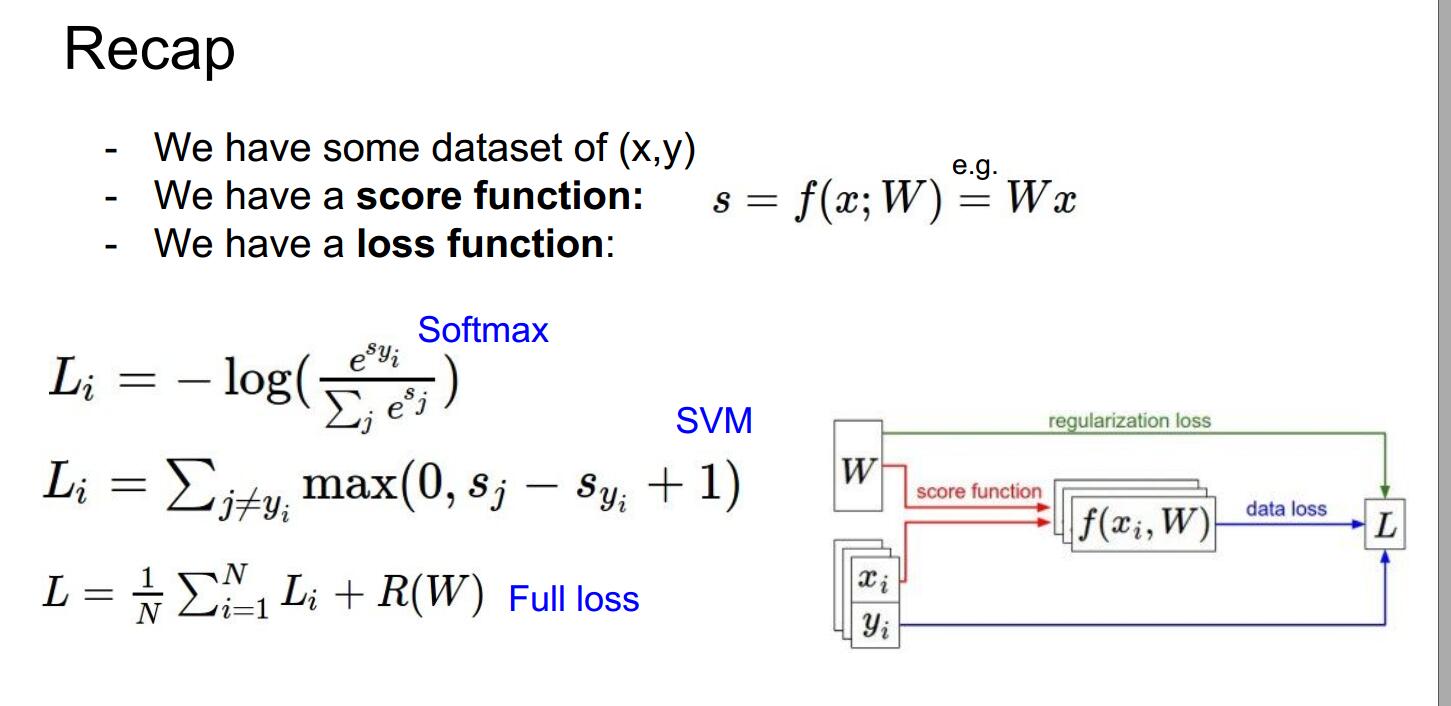
接下来我们总结一下,假设我们拥有一些数据集(x,y),我们有一个得分函数s = f(x;W) = Wx,我们再有一个loss函数,softmax函数或者hinge loss来计算我们的模型是多么的糟糕。
好了,这时候,如果你有疑问,我们怎么找到使这个loss最小的W,那么,好,下一部分,优化器见~~~~~















 3332
3332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









