







 本文详细探讨了特征融合中的Add+Concat操作在深度学习网络中的应用,如ResNet、FPN和UNet,并解释了两者间的联系与区别。Add主要适用于特征相似度高的情况,而Concat直观体现多层信息。区别在于Add保持通道数不变,而Concat增加通道数。适合场景包括编码解码结构和分辨率特征融合。
本文详细探讨了特征融合中的Add+Concat操作在深度学习网络中的应用,如ResNet、FPN和UNet,并解释了两者间的联系与区别。Add主要适用于特征相似度高的情况,而Concat直观体现多层信息。区别在于Add保持通道数不变,而Concat增加通道数。适合场景包括编码解码结构和分辨率特征融合。
信息融合举例
特征融合目前有两种常用的方式,一种是
a
d
d
add
add操作,这种操作广泛运用于
R
e
s
N
e
t
ResNet
ResNet与
F
P
N
FPN
FPN中。一种是
C
o
n
c
a
t
Concat
Concat操作,这种操作最广泛的运用就是
U
N
e
t
UNet
UNet,
D
e
n
s
e
N
e
t
DenseNet
DenseNet等网络中。如下图所示:

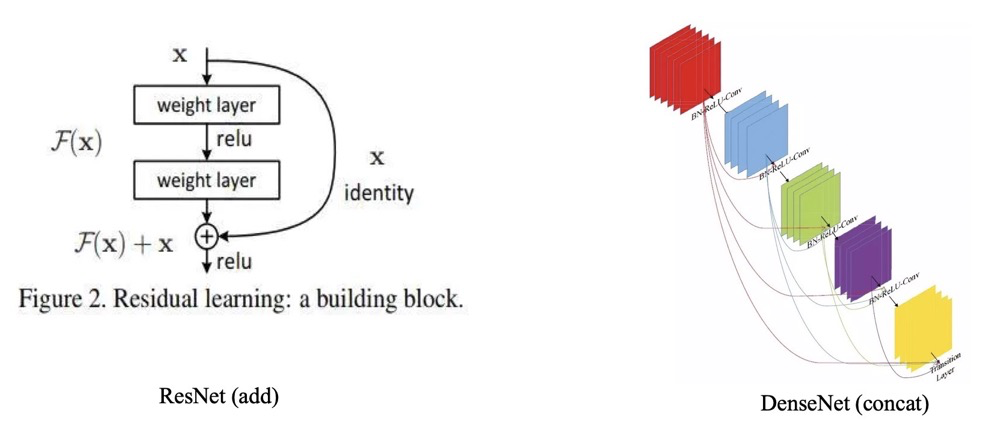
也有如 H R N e t HRNet HRNet这样的,多分辨率之间使用 a d d add add形式的特征融合。
代码演示
>>> import torch
>>> img1 = torch.randn(2, 3, 58, 58)
>>> img2 = torch.randn(2, 3, 58, 58)
>>> img3 = img1 + img2
>>> img4 = torch.cat((img1, img2), dim=1)
>>> img3.size()
torch.Size([2, 3, 58, 58])
>>> img4.size()
torch.Size([2, 6, 58, 58])
>>>
那么对于 A d d Add Add操作与 C o n c a t Concat Concat操作,它们中间有哪些区别与联系呢?
联系
a d d add add 和 c o n c a t concat concat 形式都可以理解为整合多路分支 f e a t u r e feature feature m a p map map 的信息,只不过 c o n c a t concat concat 比较直观(同时利用不同层的信息),而 a d d add add 理解起来比较生涩(为什么两个分支的信息可以相加?)。 c o n c a t concat concat 操作时时将通道数增加, a d d add add 是特征图相加,通道数不变。
对于两路通入而言,其大小( H , W H, W H,W )是一样的。假设两路输入的通道分别为 X 1 , X 2 , … X c X_{1}, X_{2}, … X_{c} X1,X2,…Xc, Y 1 , Y 2 , … Y n Y_{1}, Y_{2},…Y_{n} Y1,Y2,…Yn。
则对于 C o n c a t Concat Concat的操作,通道数相同且后面带卷积的话, a d d add add等价于 c o n c a t concat concat之后对应通道共享同一个卷积核。
当我们需要聚合的两个分支的
F
e
a
t
u
r
e
Feature
Feature叫做
X
X
X与
Y
Y
Y的时候,我们可以使用
C
o
n
c
a
t
Concat
Concat, 概括为:
Z
o
u
t
=
∑
i
=
1
c
X
i
∗
K
i
+
∑
i
=
1
c
Y
i
∗
K
i
+
c
Z_{out}=\sum_{i=1}^{c} X_{i} * K_{i}+\sum_{i=1}^{c} Y_{i} * K_{i+c}
Zout=i=1∑cXi∗Ki+i=1∑cYi∗Ki+c
对于
a
d
d
add
add的操纵,可以概括为:
Z
add
=
∑
i
=
1
c
(
X
i
+
Y
i
)
∗
K
i
=
∑
i
=
1
c
X
i
∗
K
i
+
∑
i
=
1
c
Y
i
∗
K
i
Z_{\text {add }}=\sum_{i=1}^{c}\left(X_{i}+Y_{i}\right) * K_{i}=\sum_{i=1}^{c} X_{i} * K_{i}+\sum_{i=1}^{c} Y_{i} * K_{i}
Zadd =i=1∑c(Xi+Yi)∗Ki=i=1∑cXi∗Ki+i=1∑cYi∗Ki
因此,采用
a
d
d
add
add操作,我们相当于加入一种先验。当两个分支的特征信息比较相似,可以用
a
d
d
add
add来代替
c
o
n
c
a
t
concat
concat,这样可以更节省参数量。
区别
- 对于 C o n c a t Concat Concat操作而言,通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
- 对于 a d d add add层更像是信息之间的叠加。这里有个先验, a d d add add前后的 t e n s o r tensor tensor语义是相似的。
结论
因此,像是需要将 A A A与 B B B的 T e n s o r Tensor Tensor进行融合,如果它们语义不同,则我们可以使用 C o n c a t Concat Concat的形式,如 U N e t UNet UNet, S e g N e t SegNet SegNet这种编码与解码的结构,主要还是使用 C o n c a t Concat Concat。
而如果 A A A与 B B B是相同语义,如 A A A与 B B B是不同分辨率的特征,其语义是相同的,我们可以使用 a d d add add来进行融合,如 F P N FPN FPN等网络的设计。
大家好,我是灿视。目前是位算法工程师 + 创业者 + 奶爸的时间管理者!
我曾在19,20年联合了各大厂面试官,连续推出两版《百面计算机视觉》,受到了广泛好评,帮助了数百位同学们斩获了BAT等大小厂算法Offer。现在,我们继续出发,持续更新最强算法面经。
我曾经花了4个月,跨专业从双非上岸华五软工硕士,也从不会编程到进入到百度与腾讯实习。
欢迎加我私信,点赞朋友圈,参加朋友圈抽奖活动。如果你想加入<百面计算机视觉交流群>,也可以私我。

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









