







本专栏内容:本专栏主要针对MMDetection训练框架提供从入门到进阶的学习路线。主要分为三个阶段。三个阶段包括初入mmdetection、走进mmdetection和mmdetection进阶三大部分,并包含mmdeploy一站式部署。其中,
- 初入mmdetection系列主要通过基础环境的构建,跑通基于mmdetection的训练、推理流程,熟悉mmdetection的基本操作;
- 走进mmdetection系列主要介绍mmdetection的整体组成结构,帮助大家了解mmdetection框架训练的实现机制;
- mmdetection进阶系列主要通过AI缝合技术提升mmdetection框架训练模型指标的实战方案,也划分了初级和高级两个阶段,不仅帮助大家可以通过提供的实战方案提升模型指标,也能够自己掌握通过mmdetection进行AI缝合术。另外,也会引入一些训练过程中的常用技巧。
- mmdeploy一站式部署在模型训练之余,介绍使用mmdeploy进行TensorRT/ONNX等量化加速部署模型的转换及应用。
本篇内容: 基于MMDetection FP16混合精度训练的配置方案。以及训练过程中,出现非数据问题的长期不可逆NAN问题的解决方案。

https://github.com/open-mmlab/mmdetection
MMDetection是OpenMMlab项目中用于实现目标检测的开源训练框架,基于Pytorch(pytorch1.8+)。框架内提供了丰富的model和benchmark。
一、问题背景与现象
在使用 MMDetection 训练模型时,为了提升训练速度和节省显存,开启混合精度训练(FP16)。
配置方式:
# 在配置文件中添加以下配置2选1
fp16 = dict(loss_scale='dynamic') # 动态调整
fp16 = dict(loss_scale=dict(init_scale=256.0)) # 固定数值
问题现象:训练开始后,在迭代一定次数后,损失值(loss)突然变为不可逆转的长期的NaN。
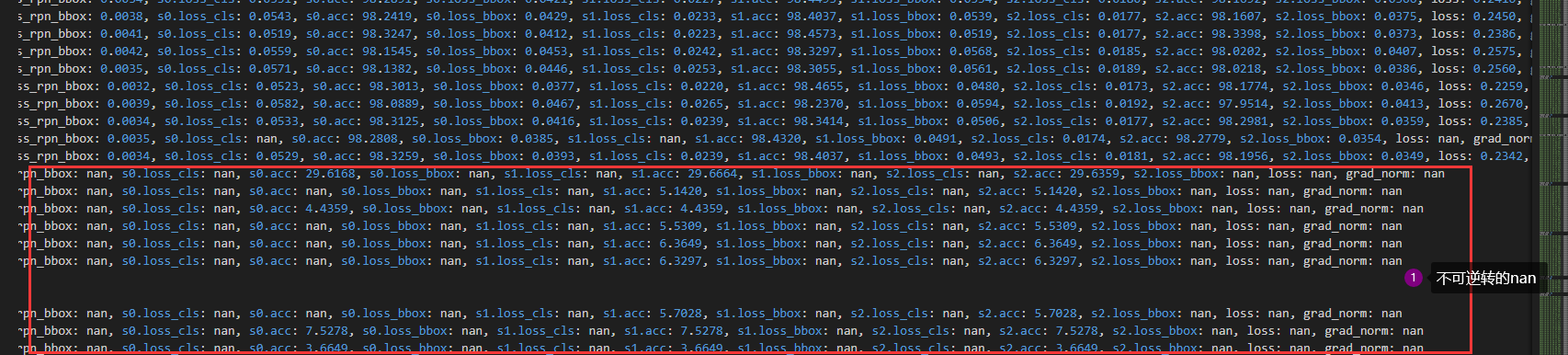
导致模型彻底无效,以下是验证时的结果,推理均为空。

二、问题根源分析
- FP16 精度限制:FP16(半精度浮点数)的数值表示范围和精度远低于 FP32(单精度浮点数)。它能表示的最大正数约为
65504,最小正数约为6.1e-5。 - 损失计算的敏感性:目标检测模型的损失计算(尤其是分类损失
CrossEntropyLoss)对数值精度非常敏感。当模型前向传播输出的分类得分(cls_score)数值过大时,在 FP16 精度下会发生数值上溢,变为inf。 @force_fp32装饰器的局限性:虽然 MMDetection 的BBoxHead基类的loss方法自带@force_fp32装饰器,旨在将输入转换为 FP32 再计算损失。但问题在于,转换时机可能太晚。如果cls_score在进入loss方法之前就已经在 FP16 计算中溢出为inf,那么即使后续转换为 FP32,inf也无法恢复为有效的数值,最终导致损失计算为NaN。
三、解决方案:双重保险策略
为解决此问题,采用 “双重保险” 策略,通过自定义 bbox_head 来主动干预数据处理流程。
核心思路
- 提前转换精度:在损失计算逻辑的最前端,主动将模型输出的
cls_score和bbox_pred从 FP16 转换为 FP32。 - 数值范围裁剪:在模型前向传播输出
cls_score后,立即对其进行数值裁剪,将其限制在一个 FP16 能够安全表示的范围内,从源头上避免上溢。
实施步骤
步骤 1: 创建自定义的 BBoxHead 文件
在项目中创建一个新文件(例如 /mmdet/models/roi_heads/bbox_heads/convfc_bbox_head.py/my_bbox_heads.py),实现自定义的 MyStableShared2FCBBoxHead。并在__init__.py中导入新建的MyStableShared2FCBBoxHead。
# -*- coding: utf-8 -*-
import torch
from mmcv.runner import force_fp32
from mmdet.models.builder import HEADS
from mmdet.models.roi_heads.bbox_heads import Shared2FCBBoxHead
@HEADS.register_module()
class MyStableShared2FCBBoxHead(Shared2FCBBoxHead):
"""
一个为混合精度训练设计的、更稳定的 BBoxHead。
核心优化:
1. 在 forward 方法中对分类得分 (cls_score) 进行数值裁剪。
2. 在 loss 方法中使用 @force_fp32 装饰器强制 FP32 计算。
"""
def __init__(self, *args, **kwargs):
"""
使用 *args 和 **kwargs 接收所有父类参数,保持配置兼容性。
"""
super(MyStableShared2FCBBoxHead, self).__init__(*args, **kwargs)
def forward(self, x):
"""
重写 forward 方法以添加数值裁剪。
"""
# 执行父类的 forward 逻辑
cls_score, bbox_pred = super(MyStableShared2FCBBoxHead, self).forward(x)
# --- 关键优化 1: 数值裁剪 ---
# 将 cls_score 裁剪到 [-100, 100],这个范围在 FP16 中是安全的,
# 足以保证 softmax 和交叉熵损失计算的稳定性。
cls_score = torch.clamp(cls_score, min=-100.0, max=100.0)
return cls_score, bbox_pred
@force_fp32(apply_to=('cls_score', 'bbox_pred'))
def loss(self,
cls_score,
bbox_pred,
rois,
labels,
label_weights,
bbox_targets,
bbox_weights,
reduction_override=None):
"""
重写 loss 方法,并强制将 cls_score 和 bbox_pred 转为 FP32。
"""
# 调用父类的 loss 方法,此时传入的已是 FP32 数据
losses = super(MyStableShared2FCBBoxHead, self).loss(
cls_score, bbox_pred, rois, labels, label_weights,
bbox_targets, bbox_weights, reduction_override
)
return losses
步骤 2: 修改配置文件
在配置文件中,将 model.roi_head.bbox_head 的 type 指向新创建的类。
# ... 其他配置 ...
model = dict(
# ... backbone 和 neck 配置 ...
roi_head=dict(
type='StandardRoIHead',
# ... 其他配置 ...
bbox_head=[
dict(
# --- 修改这里 ---
type='MyStableShared2FCBBoxHead',
# --- 以下配置保持不变 ---
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80, # 根据您的数据集修改
bbox_coder=dict(...),
loss_cls=dict(...),
loss_bbox=dict(...)
),
# 第二和第三个 stage 的 bbox_head 也需要做同样的修改
dict(type='MyStableShared2FCBBoxHead', ...),
dict(type='MyStableShared2FCBBoxHead', ...)
]),
# ... 其他配置 ...
)
# ... 其他配置 ...
四、效果验证
应用上述方案后,重新启动训练。
- 训练过程中,损失值(loss)不再出现
NaN。 - 模型能够稳定地完成所有 epoch 的训练。
- 最终模型的精度(mAP)与使用纯 FP32 训练的模型相当或略有提升。
五、总结与关键点
- 根本原因:FP16 精度限制导致模型输出在进入损失函数前发生数值溢出。
- 解决方案:通过自定义
bbox_head,实现了 “提前精度转换”和“数值范围裁剪” 的双重保险。 - 代码核心:
forward方法中的torch.clamp(cls_score, min=-100.0, max=100.0)是第一道防线。loss方法上的@force_fp32(apply_to=('cls_score', 'bbox_pred'))是第二道防线。
- 适用性:此方案适用于因混合精度训练而出现
NaN的两阶段或单阶段检测器,只需将对应的bbox_head进行类似修改即可。
通过此方案,可以在享受混合精度训练带来的速度提升和显存节省的同时,保证训练过程的数值稳定性,是解决此类问题的标准且有效的实践。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











