







机器学习笔记之 K-NEAREST NEIGHBORS
主要教材是英文的,所以一般笔记直接写英文了不翻译
- *Two major types of supervised learning problems: classification & regression
classification: predict a class label, which is a choice from a predefined list of possibilities.
regression: predict a continuous number, or a floating-point number in programming tasks. - k-NN algorithm is arguably the simplest machine learning algorithm. The model consists of only storing the training dataset. This algorithm considers an arbitrary number, k of neighbours, which are where the name of the algorithm comes from.
K-NN for Classification
在python之中可以通过scikit-learn 里的 KNeighborsClassifier 来实现
'''首先载入需要使用到的包'''
'''这里的mglearn 是为了引入与教材上相同的数据库以便比较运行是否产生错误'''
import mglearn
import matplotlib.pyplot as plt
'''对样本进行储存和自动分离得到训练样本和测试样本'''
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
'''make_blobs 是随机产生N个中心的相对集中的数据'''
from sklearn.datasets import load_breast_cancer
'''关于如何取点的一个直观说明'''
mglearn.plots.plot_knn_classification(n_neighbors=1)


'''首先先获得数据集'''
x,y = mglearn.datasets.make_forge()
'''获得训练样本和测试样本'''
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=0)
'''使用3个距离最近的点来进行分类'''
clf = KNeighborsClassifier(n_neighbors = 3)
''' 用训练样本进行训练'''
clf.fit(x_train,y_train)
'''使用测试样本进行验证'''
print('Test set predictions: %s'%(clf.predict(x_test)))
运行结果

'''模型的运行的好坏检查'''
print('Test set accuracy:%s'%(clf.score(x_test,y_test)))
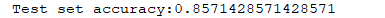
这表明模型的预测对于接近86%的测试样本来说是正确的
mglearn.plots.plot_2d_classification(clf,x,fill = True, eps= 0.5)
mglearn.discrete_scatter(x[:,0],x[:,1],y)
plt.show()
划分的情况如下图

这里可以看一下不同的取点数目对于划分的影响
'''对不同的K值进行可视化处理'''
def knntest(df, n, axx):
x, y = df
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
clf = KNeighborsClassifier(n_neighbors=n)
clf.fit(x_train, y_train)
mglearn.plots.plot_2d_classification(clf, x, fill=True, ax=axx, eps=0.5)
mglearn.discrete_scatter(x[:, 0], x[:, 1], y, ax=axx)
fig, axes = plt.subplots(2, 5, figsize=(20, 10))
'''试着看在不同的K值下对划分的影响'''
for i, ax in zip(range(1, 6), axes[0, :]):
knntest(df, i, ax)
print('%s is completed'%i, '\n')
ax.set_xlabel('feature0')
ax.set_ylabel('feature1')
ax.set_title('K-NEAREST TEST ')
axes[0, 0].legend()
for i, ax in zip(range(6, 11), axes[1, :]):
knntest(df, i, ax)
print('%s is completed'%i, '\n')
ax.set_xlabel('feature0')
ax.set_ylabel('feature1')
ax.set_title('K-NEAREST TEST CLASSIFICATION')
axes[1, 0].legend()
plt.show()
可以看到随着K值的增加,分界面变得越来越平滑。可以想象到的是随着K值的逐渐增大,直到整个数据集的其他点都是被取的点,这个时候每个点对应的neighbors基本都是相同的,预测结果也会几乎一样。

所以应该存在一个K值使得预测准度和测试准度比较接近,下面以SCIKIT里的乳腺癌人群的数据库为例
cancer = load_breast_cancer()
x_train,x_test,y_train,y_test = train_test_split(cancer.data,cancer.target,stratify=cancer.target,random_state=66)
train_accuracy = []
test_accuracy = []
for i in range(1,11):
clf = KNeighborsClassifier(n_neighbors = i)
clf.fit(x_train,y_train)
train_accuracy.append(clf.score(x_train,y_train))
test_accuracy.append(clf.score(x_test,y_test))
plt.xlabel('number of neighbors')
plt.ylabel('Accuracy')
plt.title('Accuracy of KNN by number of neighbors')
plt.plot(range(1,11),test_accuracy,'g-',label = 'test accuracy')
plt.plot(range(1,11),train_accuracy,'b--',label = 'training accuracy')
plt.legend()
plt.show()
从下图中可以看到,训练准度随着K值增大而降低,而测试准度在k=6时与训练准度较为接近,可以理解为对这组数据来说K=6是相对理想的。

K-NN for Regression
在python之中可以通过scikit-learn 里的 KNeighborsRegressor 来实现
from sklearn.neighbors import KNeighborsRegressor
'''看一下这种情况下的取点例子'''
mglearn.plots.plot_knn_regression(n_neighbors=3)

x,y = df
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
reg = KNeighborsRegressor(n_neighbors = 3)
reg.fit(x_train,y_train)
print('Train score: %s'%(reg.score(x_train,y_train)),'\n','Test score :%s'%(reg.score(x_test,y_test)))
可以看出这里的R^2只有0.63,可能模型在这个样本数目下的不是很好
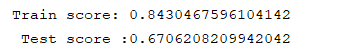
试着将样本数从100变到40,于是
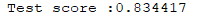
'''方便对不同的K值进行处理'''
def knnreg(data, n):
x, y = data
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
reg = KNeighborsRegressor(n_neighbors=n)
reg.fit(x_train, y_train)
return reg
'''回归可视化'''
def runknnregplot(line,reg,x_train,y_train,x_test,y_test,ax,xlabel = 'feature0',ylabel='feature1'):
ax.plot(line, reg.predict(line))
ax.plot(x_train, y_train, 'r^')
ax.plot(x_test, y_test, 'b*')
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_title('Train score:{:.2f}Test score:{:.2f}'.format(reg.score(x_train,y_train),reg.score(x_test,y_test)))
return ax
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
x, y = df
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
fig, axes = plt.subplots(2, 5, figsize=(25, 10))
for i, ax in zip(range(1, 9), axes[0, :]):
reg = knnreg(df, i)
runknnregplot(line,reg,x_train,y_train,x_test,y_test,ax)
'''方便提示进行到第几位'''
print('%s is done ' % i)
axes[0,0].legend(['Model prediction', 'Training dataset', 'Testing dataset'])
for i, ax in zip(range(9, 17), axes[1, :]):
reg = knnreg(df, i)
runknnregplot(line,reg,x_train,y_train,x_test,y_test,ax)
print('%s is done ' %i)
axes[1,0].legend(['Model prediction', 'Training dataset', 'Testing dataset'])
plt.show()
可以看出,虽然随着K值的增加曲线逐渐变得光滑,但并不是K值越大越好,测试准度在K=10左右是较好的,

总结(这也是笔记就不翻译中文了)
- Strengths: Easy to understand, often give reasonable performance, good baseline algorithm before trying other complex techniques
- Weaknesses: predictions become slow when the dataset is extremely large, perform not well when features of datasets are very large















 2071
2071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









