






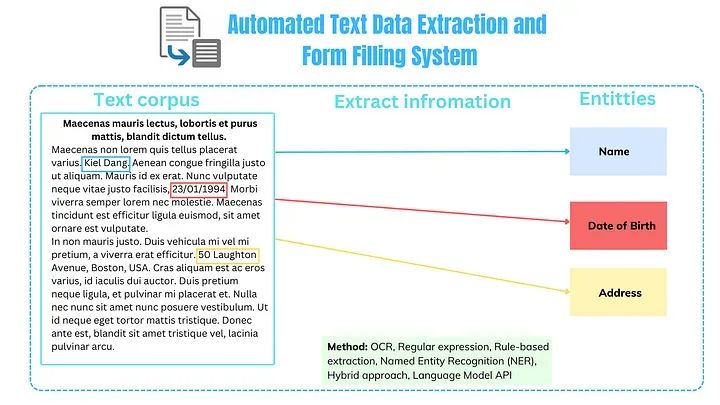
在一个数据是业务运营生命线的时代,从大量非结构化文本中提取有价值的信息可能是一项艰巨的挑战。无论是解析合同、发票还是手写笔记,准确而高效的文本数据提取需求变得愈发紧迫。该项目涉及多种方法和技术,包括用于文本识别的OCR、用于信息提取的语言模型和命名实体识别(NER),以及用于特定数据模式匹配和填充表单的正则表达式/规则。
动机
开发用于准确文本数据提取的OCR和语言模型的动机是多方面的,每个都受到利用自动化的力量、减少错误并加速业务增长的愿望驱使。
替代繁琐任务中的人类
减少错误
加速业务增长的更快购买决策
用例
以下是一些具体的用例,其中这样的系统可能非常有价值:
职位申请:每当候选人上传其简历时,系统将提取必要的信息并为候选人填写数据。
更快的报价流程:在保险、建筑或制造等行业中,快速而准确地生成报价对于业务竞争至关重要。
法律文件分析:协助法律专业人员解析庞大的法律文件、合同和协议,以识别关键条款、义务和潜在风险。
库存管理:通过从装箱单和发票中提取产品信息、数量和价格,自动跟踪库存,减少手动输入错误。
医疗记录数字化:加速患者记录和医疗文件的数字化过程,确保快速访问关键的医疗信息。
应用
在本教程中,作者将展示一个旨在简化获取住房保险报价过程的系统。我们将不再手动输入潜在客户提供的租赁协议中的数据,而是开发一种算法,使客户能够轻松上传他们的租赁协议或法律文件。然后,我们的系统将自动提取并填充必要的字段。
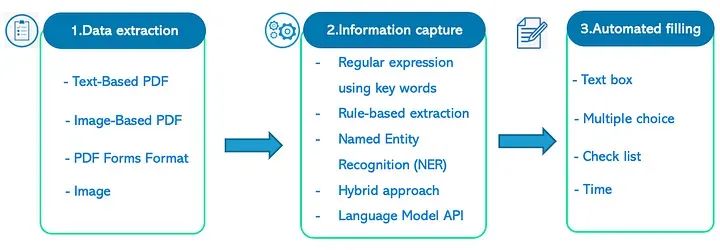
一. 项目设置
该项目经历了3个主要阶段:(1) 数据提取,(2) 相关信息捕获 和 (3) 填写表单。在这三个阶段中,第二步比较困难,而其他阶段在当今技术下相对容易。因此,在本文中,作者将主要关注这个阶段。
二. 执行
1. 文本数据提取
有许多用于文本提取的OCR包,但我们的目的是选择一个可以涵盖潜在客户可能上传其法律文件的所有输入格式的工具。
我能想到的有四种格式,可能是非结构化或结构化的,潜在客户可能会上传他们的法律文件。它们是:基于文本的PDF、基于图像的PDF、图像或仅PDF表格(这种情况很少见)。

为了高效地从这些格式中提取文本,我建议使用Python中的PDF2包。我们将所有文本保存在一个称为“text”的单个字符串中。
# Import library
from PyPDF2 import PdfReader
# Open the PDF file
pdf_file = PdfReader(open("data/sample.pdf", "rb"))
# Read all the pages in the PDF
pages = [pdf_file.pages[i] for i in range(len(pdf_file.pages))]
# Join all the pages into a single string
text = '\n'.join([page.extract_text() for page in pages])2. 信息捕获
由于这个步骤是系统的核心,作者将演示多种方法来准确捕获所需信息。假设我们只需要从此演示数据中提取5个元素:first_name(名字)、last_name(姓氏)、address(地址)、phone(电话)、date_of_birth(出生日期)。
a. 正则表达式方法
这种传统方法有一些缺点,因为它仅适用于结构化的输入数据,并且搜索列表可能会被耗尽。
# Import Regular Expression
import re
# Create empty lists to store our data
first_names = []
last_names = []
addresses = []
phones = []
dates_of_birth = []
# Define a function to capture the information from text file using Regular Expression
def extract_info_1(text, first_names, last_names, addresses, phones, dates_of_birth):
# Use regular expressions to search for the relevant information in the text
Address_keys = ["Location", "Located at", "Address", "Residence", "Premises", "Residential address"]
BOD_keys = ["Born on", "DOB", "Birth date", "Date of birth"]
Phone_keys = ["Phone", "Telephone", "Contact number", "Call at", "Phone number", "Mobile number"]
First_Name_keys = ["First name", "Given name", "First", "Given", "Tenant", "First and last name"]
Last_Name_keys = ["Last name", "Family name", "Surname", "Last"]
for keyword in Address_keys:
matches = re.findall(keyword + "\s*:\s*(.*)", text, re.IGNORECASE)
if matches:
addresses.extend(matches)
for keyword in BOD_keys:
matches = re.findall(keyword + "\s*:\s*(.*)", text, re.IGNORECASE)
if matches:
dates_of_birth.extend(matches)
for keyword in Phone_keys:
matches = re.findall(keyword + "\s*:\s*(.*)", text, re.IGNORECASE)
if matches:
phones.extend(matches)
for keyword in First_Name_keys:
matches = re.findall(keyword + "\s*:\s*(.*)", text, re.IGNORECASE)
if matches:
first_names.extend(matches)
for keyword in Last_Name_keys:
matches = re.findall(keyword + "\s*:\s*(.*)", text, re.IGNORECASE)
if matches:
last_names.extend(matches)
# Apply function
extract_info_1(text, first_names, last_names, addresses, phones, dates_of_birth)为了正确捕获所有信息,我们只需要更新每个列表的关键字,然后该函数将在这些关键字之后捕获所有信息。例如,客户的地址可能遵循以下关键字:Address_keys = [“Location”, “Located at”, “Address”, “Residence”, “Premises”, “Residential address”,…]
b. 基于规则的方法
这也是一种传统的方法,但因为我们可能了解每个信息片段的模式,所以它似乎是有帮助的。例如:由于我们的客户位于加拿大,电话号码可能具有以下模式:
(123) 456–7890,或
123–456–7890,或
123 456 7890,或
1234567890,或
这些带有+1前缀的电话。
因此,我们可以为每个元素使用这些规则来提取它。
# Import Regular Expression
import re
# Define a function to capture the information from text file using Regular Expression
def extract_info_2(text, first_names, last_names, addresses, phones, dates_of_birth):
# RULES
# Address pattern
# example: 123 Main St, Toronto, ON, M4B 1B3
address_pattern = re.compile(r"""
# Match the street address, which may include house/apartment number, street name, and street type
(\d+\s+\b[A-Z][a-z]+\b\s+\b[A-Z][a-z]+\b)
\s*,\s*
# Match the city, which should start with an uppercase letter
([A-Z][a-z]+)\s*,\s*
# Match the province abbreviation, which should be two uppercase letters
(ON)\s*
# Match the postal code, which should be formatted as A1A 1A1
(\b[A-Z]\d[A-Z]\s?\d[A-Z]\d\b)
""", re.VERBOSE)
# Phone number pattern
# example: (123) 456-7890 or 123-456-7890 or 1234567890 or these phones with +1
phone_pattern = re.compile(r"""
(?:
# match a phone number starting with the country code (1)
1\s*[\.-]?\s*\(?(\d{3})\)?[\.-]?\s*(\d{3})[\.-]?\s*(\d{4})
|
# match a phone number without the country code
\(?(\d{3})\)?[\.-]?\s*(\d{3})[\.-]?\s*(\d{4})
)
""", re.VERBOSE)
dob_pattern = re.compile(r"""
# Match dates in the format YYYY-MM-DD
(\d{4})-(\d{2})-(\d{2})
|
# Match dates in the format MTH DD, YYYY
(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\s+(\d{1,2}),\s+(\d{4})
|
# Match dates in the format Month DD YYYY
(January|February|March|April|May|June|July|August|September|October|November|December)\s+(\d{1,2})\s+(\d{4})
""", re.VERBOSE)
# Extract information using the new regex patterns
address_matches = address_pattern.findall(text)
if address_matches:
addresses.extend(address_matches)
phone_matches = phone_pattern.findall(text)
if phone_matches:
phones.extend(["-".join(filter(None, match)) for match in phone_matches])
dob_matches = dob_pattern.findall(text)
if dob_matches:
dates_of_birth.extend(["-".join(filter(None, match)) for match in dob_matches])
# Apply function
extract_info_2(text, first_names, last_names, addresses, phones, dates_of_birth)代码解释:
提供的代码定义了三个正则表达式模式(address_pattern、phone_pattern 和 dob_pattern),并附有解释它们目的的注释以及预期输入格式的示例。让我们逐个解释每个模式:
地址模式(address_pattern):
address_pattern = re.compile(r"""
# Match the street address, which may include house/apartment number, street name, and street type
(\d+\s+\b[A-Z][a-z]+\b\s+\b[A-Z][a-z]+\b)
\s*,\s*
# Match the city, which should start with an uppercase letter
([A-Z][a-z]+)\s*,\s*
# Match the province abbreviation, which should be two uppercase letters
(ON)\s*
# Match the postal code, which should be formatted as A1A 1A1
(\b[A-Z]\d[A-Z]\s?\d[A-Z]\d\b)
""", re.VERBOSE)这个正则表达式被设计用来匹配特定格式的街道地址,例如“123 Main St, Toronto, ON, M4B 1B3”。
它将地址拆分为几个组件:
房屋或公寓号码:\d+
街道名称(以大写字母开头,后跟小写字母):\b[A-Z][a-z]+\b
城市(以大写字母开头):[A-Z][a-z]+
省份缩写(例如,安大略省的“ON”):(ON)
邮政编码(格式为A1A 1A1):\b[A-Z]\d[A-Z]\s?\d[A-Z]\d\b
\s* 用于匹配可选的空白,而 \s*,\s* 用于匹配分隔这些组件的逗号。
电话号码模式(phone_pattern):
# Phone number pattern
# example: (123) 456-7890 or 123-456-7890 or 1234567890 or these phones with +1
phone_pattern = re.compile(r"""
(?:
# match a phone number starting with the country code (1)
1\s*[\.-]?\s*\(?(\d{3})\)?[\.-]?\s*(\d{3})[\.-]?\s*(\d{4})
|
# match a phone number without the country code
\(?(\d{3})\)?[\.-]?\s*(\d{3})[\.-]?\s*(\d{4})
)
""", re.VERBOSE)它可以匹配以下格式的电话号码:
带国家代码(例如,+1或1):1\s*[\.-]?\s*\(?(\d{3})\)?[\.-]?\s*(\d{3})[\.-]?\s*(\d{4})
没有国家代码:\(?(\d{3})\)?[\.-]?\s*(\d{3})[\.-]?\s*(\d{4})
其中,(\d{3}) 和 (\d{4}) 分别捕获区号和线路号。
出生日期模式(dob_pattern):
dob_pattern = re.compile(r"""
# Match dates in the format YYYY-MM-DD
(\d{4})-(\d{2})-(\d{2})
|
# Match dates in the format MTH DD, YYYY
(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\s+(\d{1,2}),\s+(\d{4})
|
# Match dates in the format Month DD YYYY
(January|February|March|April|May|June|July|August|September|October|November|December)\s+(\d{1,2})\s+(\d{4})
""", re.VERBOSE)这个正则表达式旨在匹配不同日期格式的出生日期,包括YYYY-MM-DD、MTH DD、YYYY和Month DD YYYY等格式。
它由三个主要组成部分组成,由|(交替)分隔:
格式为YYYY-MM-DD的日期:(\d{4})-(\d{2})-(\d{2})
格式为MTH DD, YYYY(例如,Jan 01, 2023)的日期:(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\s+(\d{1,2}),\s+(\d{4})
格式为Month DD YYYY(例如,January 1, 2023)的日期:(January|February|March|April|May|June|July|August|September|October|November|December)\s+(\d{1,2})\s+(\d{4})
\d{4}、\d{2} 和 \d{1,2} 用于分别匹配年、月和日组件。
地址提取(address_pattern):
地址模式是为了找到具有多个组件的完整街道地址(例如,街道号码、街道名称、城市、省份、邮政编码)并符合特定格式。
address_pattern.findall(text) 返回输入文本中找到的所有匹配项的列表。
如果找到任何地址匹配项,代码将它们全部附加到地址列表。
电话号码提取(phone_pattern):
电话号码模式旨在找到各种格式的电话号码,包括带有或不带有国家代码的号码。
phone_pattern.findall(text) 返回输入文本中找到的所有电话号码匹配项的列表。
为了确保一致的格式,代码处理每个电话号码匹配项,使用连字符(-)连接各个组件(区号、前缀、线路号)。
然后,将这些格式化的电话号码附加到电话列表。
出生日期提取(dob_pattern):
dob_pattern模式旨在找到不同日期格式的出生日期(例如,YYYY-MM-DD、MTH DD、YYYY、Month DD YYYY)。
dob_pattern.findall(text) 返回输入文本中找到的所有出生日期匹配项的列表。
代码处理每个出生日期匹配项,通过必要时使用连字符(-)连接各个组件,以确保一致的格式。
然后,将这些格式化的出生日期附加到dates_of_birth列表。
c. 命名实体识别(NER)模型:
在spaCy的NER(命名实体识别)模型中,实体被分类为各种类型,以识别和标记文本中不同类型的命名实体。spaCy的NER模型识别的实体类型包括但不限于:
PERSON:个人的名字。
ORG:组织、公司或机构的名字。
GPE:地缘政治实体,如国家、城市和州。
LOC:非地缘政治位置,如自然地标或水体。
DATE:以各种格式表示的日期(例如,“2023年1月1日”或“2023-01-01”)。
TIME:以各种格式表示的时间(例如,“下午3:00”或“15:00:00”)。
MONEY:货币值,包括货币符号(例如,“$100”或“€50”)。
PERCENT:百分比值(例如,“10%”或“50 percent”)。
QUANTITY:测量或数量(例如,“5千克”或“10米”)。
ORDINAL:序数(例如,“第一”、“第二”、“第三”)。
CARDINAL:基数(例如,“一”、“二”、“三”)。
PRODUCT:产品的名字,如品牌名或特定物品。
EVENT:事件、会议或发生的名字。
LANGUAGE:语言或与语言相关的术语。
LAW:法律引用,如法律或法规。
WORK_OF_ART:艺术作品、书籍或音乐作品的标题。
NORP:国籍或宗教或政治团体。
FAC:设施、建筑物或结构的名字。
PHONE:电话号码。
这是使用NER提取文本数据时的一个示例结果:
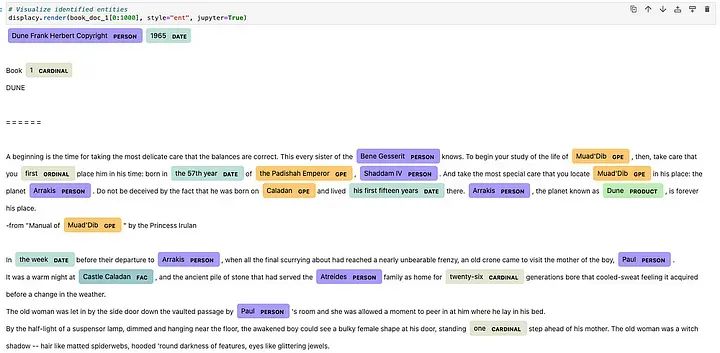
在这种方法中,我们可以利用上述高亮的实体(1、3、5、19)来提取我们需要的信息。
import spacy
# Load the large English NER model
nlp = spacy.load("en_core_web_sm")
# Define a function to capture the information from text using Named Entity Recognition
def extract_info_3(text, first_names, last_names, addresses, phones, dates_of_birth):
# Initialize variables to store extracted information
first_name = ""
last_name = ""
address = ""
phone = ""
date_of_birth = ""
# Process the text with spaCy NER model
doc = nlp(text)
# Extract the information using Named Entity Recognition
for ent in doc.ents:
if ent.label_ == "PERSON":
# Check if the entity text is a first name
if not first_name:
first_name = ent.text.strip()
else:
# If we already have a first name, assume the current entity is the last name
last_name = ent.text.strip()
elif ent.label_ == "GPE":
# GPE represents geographical entities, which could include addresses
address = ent.text.strip()
elif ent.label_ == "PHONE":
# PHONE entity type (custom) for phone numbers
phone = ent.text.strip()
elif ent.label_ == "DATE":
# DATE entity type for dates, which could include date of birth
date_of_birth = ent.text.strip()
# Append the extracted information to the pre-defined lists
first_names.append(first_name)
last_names.append(last_name)
addresses.append(address)
phones.append(phone)
dates_of_birth.append(date_of_birth)d. 混合方法
这种方法结合了上述所有方法,我们只需将文本通过所有3个函数传递,就能够进一步获取数据。在每个列表中,我们将首先排列重复次数较多的元素,然后是频率较低的词语。
e. 语言模型方法 —— 上下文学习模型
对于非结构化数据,我强烈推荐使用这种方法,因为它相对于以上所有4种方法都能够给我们更好的结果。为什么呢?
法律文件是抽象的。对于我们的案例,租赁协议可能使用复杂和复杂的语言,传统方法可能无法胜任。
上传的数据是非结构化的。我们的客户有多种类型的表单,从图像到PDF,格式各异。与此同时,传统方法只适用于结构化和有模式的数据。
一个字段有很多实体。例如,我们可能会遇到租赁协议中有许多名字,可能是租户1、租户2、房东和房东的配偶。传统方法如何猜测是谁呢?
准确性大于充分。有时,通过我们的系统删除错误的填充词并输入新信息所花费的时间比没有这样的系统填写表单更多。而且,这也涉及到我们客户的体验 —— 一个公司如何提供糟糕的报价体验能够提供良好的保险服务呢?
像ChatGPT API这样的大型语言模型能够比我们的传统方法更好地理解文档的上下文。特别是当我们使用其API对模型进行上下文/数据库的训练时;我们称之为上下文学习算法。
下面的代码只是一个示例,演示了如何使用API提取数据。事实上,我们需要使用我们的数据库来训练模型,反馈结果并进行循环。这个过程需要时间,但最终会带来惊人的回报。有关上下文学习的更多信息,请参考我的其他文章。
# 1. Import the necessary libraries
import openai
import os
import pandas as pd
import time
# 2. Set your API from ChatGPT account
openai.api_key = '<YOUR API KEY>'
# 3. Set up a function to get the result
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
# 4. Create a promt from text file and our words:
question = "Read and understand the document, then help me extract 5 pieces of information including (1) First name, (2) last name, (3) date of birth, (4) address, (5) phone number of tenants only. Here is the content of the document: ".join(text)
# 5. Query the API
response = get_completion(question)
print(response)完成这一步之后,您只需要从响应中提取数据,即可获得所需信息。
3. 表单自动填充
在这一步中,由于我们可以控制所有填充的字段,因此对于每位数据科学家来说,执行这个阶段相当容易。
这高度依赖于我们拥有的内部系统,但我可以演示如何使用Selenium进行网络浏览和填充来从外部填写表单。
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
# Load the website
web = webdriver.Chrome()
web.get('https://secure.sonnet.ca/#/quoting/property/about_you?lang=en')
# Wating for the web to load before filling out
time.sleep(5)
# Inputs field
#ADDRESS
Address_input = "50 Laughton Ave M6N 2W9" # KEY
Address_fill = web.find_element("xpath",'//*[@id="addressInput"]')
Address_fill.send_keys(Address_input)
# FIRST NAME
FirstName_input = "Kiel" # KEY
FirstName_fill = web.find_element("xpath",'//*[@id="firstName"]')
FirstName_fill.send_keys(FirstName_input)
# LAST NAME
LastName_input = "Dang" # KEY
LastName_fill = web.find_element("xpath",'//*[@id="lastName"]')
LastName_fill.send_keys(LastName_input)
# MONTH OF BIRTH
dropdown_month = web.find_element("id","month-0Button")
dropdown_month.click()
option = web.find_element("xpath", "//span[contains(text(), 'January')]") #KEY
option.click()
# DATE OF BIRTH
Date_input = "23" # KEY
Date_fill = web.find_element("xpath",'//*[@id="date-0"]')
Date_fill.send_keys(Date_input)
# YEAR OF BIRTH
Year_input = "1994" # KEY
Year_fill = web.find_element("xpath",'//*[@id="year-0"]')
Year_fill.send_keys(Year_input)
# Prevent auto closing the web after application finishes the script.
input("Press enter to close the browser")
web.quit()结论
在开发自动文本数据提取和表单填充系统的过程中,我们深入探讨了技术与对高效数据处理不断增长的需求相遇的领域。我们项目的核心动机是利用自动化的力量来替代人类进行繁琐任务,减少错误,并促进业务增长的更快决策。通过各种方法,我们旨在解决从非结构化文本数据中提取有价值信息并准确填写表单的具有挑战性的任务。
我们探索了一系列技术,从传统方法如正则表达式和基于规则的方法到更先进的方法,涉及spaCy的命名实体识别(NER)模型。每种方法都具有其独特的优势,适用于不同类型的输入数据和场景。
此外,我们介绍了一种混合方法,结合了多种方法的优势,实现了更强大和灵活的解决方案。最后,我们探讨了像ChatGPT API这样的大型语言模型的潜力,该模型在理解复杂的法律文件并根据上下文提取相关信息方面表现出色。
所学到的经验:
数据的多样性:我们了解到非结构化文本数据可能以各种格式存在,设计提取系统时考虑到这种多样性至关重要。一刀切的方法可能不够有效。
方法的选择:不同的方法各有优势和劣势。正则表达式适用于结构化数据,而NER模型擅长理解上下文。选择的方法应与特定用例和数据类型保持一致。
混合解决方案:结合多种方法可以提高提取系统的准确性和适应性。充分利用不同方法的优势可以产生更可靠的结果。
大型语言模型:像ChatGPT API这样的语言模型有处理复杂数据和上下文的潜力,使其成为处理具有挑战性情景下数据提取的有价值工具。
测试和验证:彻底的测试和验证对确保提取数据的准确性至关重要。现实世界的数据可能引入意外的变化,系统应具备足够的鲁棒性来处理它们。
用户友好的界面:在实施这样的系统时,为数据输入和输出创建用户友好的界面可以提高可用性和采用率。
总的来说,开发自动文本数据提取和表单填充系统的过程是一个动态的旅程,受到技术不断演进和对数据准确性和效率不断增长的需求的推动。通过不断适应和整合新的方法和技术,企业可以保持在数据管理的前沿,做出明智的决策并加速其增长。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除

















 2224
2224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









