






点击下方卡片,关注“小白玩转Python”公众号
OpenAI最近发布了GPT-4o——据称是OpenAI最好的AI模型,但价格只有GPT-4的一半!这个新模型提供了实时的多模态能力,涵盖文本、视觉和音频,其智能水平与GPT-4Turbo相同,但效率更高——这意味着它具有更低的延迟,文本生成速度快2倍,而且非常重要的是,它的价格是GPT-4Turbo的一半。
动机
如果你需要分析图像以收集结构化信息,你来对地方了。在这篇文章中,我们将快速学习如何使用OpenAI最新最先进的模型——GPT-4o,从图像中提取结构化信息。
工作流程
首先导入相关的库:
import base64
import json
import os
import os.path
import re
import sys
import pandas as pd
import tiktoken
import openai
from openai import OpenAI在本文中,我将使用以下图像进行演示。你可以对自己的图像应用相同的原理,提出任何问题:
 用来提取信息的图像
用来提取信息的图像
步骤1:加载和编码图像
图像主要有两种方式提供给模型:通过传递图像链接或通过在请求中直接传递base64编码的图像。Base64是一种编码算法,可以将图像转换为可读的字符串。你可以在用户、系统和助手消息中传递图像。
由于我的图像存储在本地,让我们将本地图像编码为base64 URL。以下函数读取图像文件,确定其MIME类型,并将其编码为base64数据URL,适合传输到API:
import base64
from mimetypes import guess_type
# Function to encode a local image into data URL
def local_image_to_data_url(image_path):
# Guess the MIME type of the image based on the file extension
mime_type, _ = guess_type(image_path)
if mime_type is None:
mime_type = "application/octet-stream" # Default MIME type if none is found
# Read and encode the image file
with open(image_path, "rb") as image_file:
base64_encoded_data = base64.b64encode(image_file.read()).decode("utf-8")
# Construct the data URL
return f"data:{mime_type};base64,{base64_encoded_data}"步骤2:设置API客户端和模型
要构建流水线,首先使用我们的API密钥设置OpenAI API客户端:
openai.api_key = 'your api key'
client = OpenAI(api_key = openai.api_key)
model = "gpt-4o"这一步初始化OpenAI客户端,使我们能够与GPT-vision模型进行交互。现在,我们准备好运行流水线。
步骤3:运行GPT-4o流水线以处理图像并获取响应
在此代码中,我们遍历指定目录中的图像,编码每个图像,并向GPT-4o模型发送请求。模型被指示分析图像并提取结构化信息,返回的应该是JSON格式。
#define the base directory for the images, encode them into base64, and use the model to extract structured information:
base_dir = "data/"
data_urls = []
responses = []
path = os.path.join(base_dir, "figures")
if os.path.isdir(path): # Ensure it's a directory
# use the image and ask question
for image_file in os.listdir(path)[:1]:
image_path = os.path.join(path, image_file)
try:
print(f"processing image: {image_path}")
data_url = local_image_to_data_url(image_path)
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": """
You are `gpt-4o`, the latest OpenAI model that can interpret images and can describe images provided by the user
in detail. The user has attached an image to this message for
you to answer a question, there is definitely an image attached,
you will never reply saying that you cannot see the image
because the image is absolutely and always attached to this
message. Answer the question asked by the user based on the
image provided. Do not give any further explanation. Do not
reply saying you can't answer the question. The answer has to be
in a JSON format. If the image provided does not contain the
necessary data to answer the question, return 'null' for that
key in the JSON to ensure consistent JSON structure.
""",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": """
You are tasked with accurately interpreting detailed charts and
text from the images provided. You will focus on extracting the price for all the DRINKS from the menu.
Guidelines:
- Include all the drinks in the menu
- The output must be in JSON format, with the following structure and fields strictly adhered to:
Response Format:
The output must be in JSON format, with the following structure and key strictly adhered to:
- dish: the name of the appetizer dish
- price: the price of the appetizer dish
- currency: the currency
""",
},
{"type": "image_url", "image_url": {"url": data_url}},
],
},
],
max_tokens=3000,
)
content = response.choices[0].message.content
responses.append(
{ "image": image_file, "response": content}
)
except Exception as e:
print(f"error processing image {image_path}: {e}")
responses响应输出变量以JSON格式返回,按照我的提示请求,它看起来与参考照片一致。
```json
[
{
"drink": "Purified Water",
"price": 3.99,
"currency": "$"
},
{
"drink": "Sparkling Water",
"price": 3.99,
"currency": "$"
},
{
"drink": "Soda In A Bottle",
"price": 4.50,
"currency": "$"
},
{
"drink": "Orange Juice",
"price": 6.00,
"currency": "$"
},
{
"drink": "Fresh Lemonade",
"price": 7.50,
"currency": "$"
}
]
```步骤4:将JSON格式转换为数据框
你还可以通过以下代码将JSON输出解析为数据框,从而创建结构化数据格式:
def format_output_qa(output, debug = False):
print(f"Raw model output: {output}")
try:
# cleanup the json output
output_text = output.replace("\n", "")
output_text=output_text.replace("```json", "")
output_text=output_text.replace("```", "")
if debug is True:
return output_text
# Now load it into a Python dictionary
output_dict = json.loads(output_text)
# create a df
df = pd.DataFrame(output_dict)
except Exception as e:
print(f"Error processing output: {e}")
df = pd.DataFrame({"error": str(e)}, index=[0])
return df
# Now process each response in the list
df_output = pd.DataFrame()
for response_dict in responses:
response = response_dict["response"]
df = format_output_qa(response)
df["image"] = response_dict["image"]
df_output = pd.concat([df_output, df], ignore_index=True)
df_output结果如下:
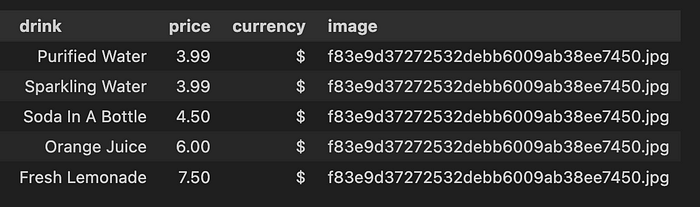
结论
这是一个简单而强大的流水线,利用GPT-4o的视觉能力从图像中提取数据,将非结构化的视觉数据转化为结构化数据以供进一步分析。无论你是在收集和分析视觉内容,这些步骤都为将图像处理集成到AI工作流程中提供了坚实的基础。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









