






如果你以前使用过目标检测,是否曾因边界框未正确包围物体而感到沮丧?或者它提供了错误的或不完整的包围?那可以尝试使用图像分割,它比目标检测更先进,因为它完全包围了物体。对物体进行分割之后,可以快速将其转换为最先进的TensorFlow Lite(TFLite)模型。
什么是物体分割?
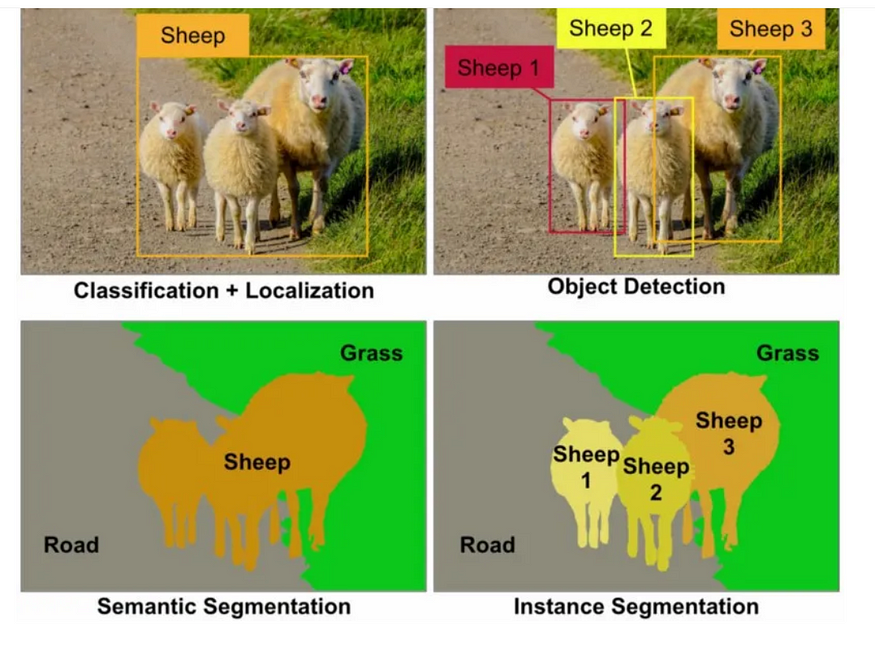
物体分割是一个计算机视觉问题,包括检测和区分图像中的离散物体或感兴趣区域。它也被称为图像或实例分割。物体分割的目的是为图像中的每个项目或实例提供唯一的标签或标识,同时精确定义这些物体的边界。
这项工作是语义分割的子集,它为图像中的每个像素分配一个标签,但不区分同一物品类别的不同实例。
用于物体分割的各种技术和算法包括传统方法,如阈值处理、边缘检测和区域生长,以及基于深度学习的方法,如卷积神经网络(CNN)和更高级的模型,如Mask R-CNN、YOLO(You Only Look Once)和FCN(完全卷积网络)。这些方法显著提高了物体分割任务的准确性和效率,使它们成为许多计算机视觉系统的重要组成部分。让我们开始进行图像分割编程
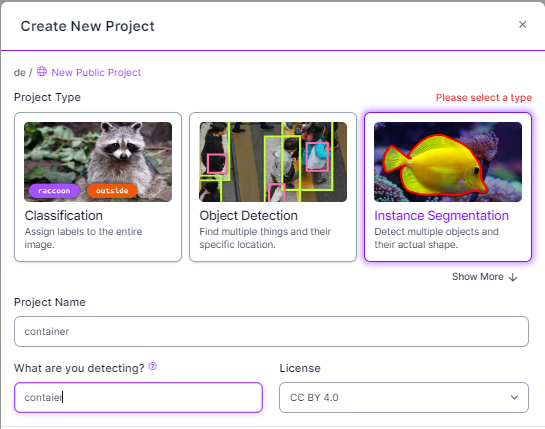
0. 在Roboflow中选择实例分割任务
选择实例分割,而不是目标检测
1. 从命令提示符中安装ultralytics
这将安装ultralytics ver8
!pip install ultralytics2. 读取图像并调整大小以适应屏幕
读取图像并在图像过大时调整大小。WaitKey(0)将无限期显示窗口,直到按下任意键(适用于图像显示)。
import cv2
from yolo_segmentation import YOLOSegmentation
img = cv2.imread("rugby.jpg")
img = cv2.resize(img,None, fx=0.3, fy=0.3)3. 下载权重并分配变量给YOLO分割模型
ys = YOLOSegmentation('yolov8m-seg.pt')
bboxes, classes, segmentations, scores = ys.detect(img)下面是YOLOSegmentation类的文件,我们可以在关键字"return"之后看到序列顺序。
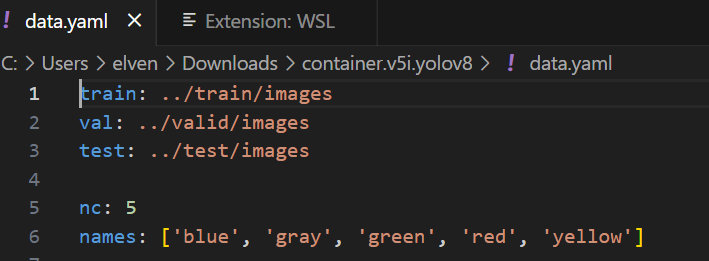
4. 了解data.yaml文件
Data.yaml文件指定文件的路径和类别ID。
蓝色的ID为0,灰色的ID为1,绿色的ID为2,红色的ID为3,黄色的ID为4。
#https://pysource.com/2023/02/21/yolo-v8-segmentationfrom ultralytics import YOLO
import numpy as np
class YOLOSegmentation:
def __init(self, model_path):
self.model = YOLO(model_path)
def detect(self, img):
height, width, channels = img.shape
results = self.model.predict(source=img.copy(), save=False, save_txt=False)
result = results[0]
segmentation_contours_idx = []
for seg in result.masks.segments:
# contours
seg[:, 0] *= width
seg[:, 1] *= height
segment = np.array(seg, dtype=np.int32)
segmentation_contours_idx.append(segment)
bboxes = np.array(result.boxes.xyxy.cpu(), dtype="int")
class_ids = np.array(result.boxes.cls.cpu(), dtype="int")
scores = np.array(result.boxes.conf.cpu(), dtype="float").round(2)
return bboxes, class_ids, segmentation_contours_idx, scores4. 解释代码
运行代码并尝试解释它。
它显示类别为飞盘或运动球的图像大小为448x640。
for bbox, class_id, seg, score in zip(bboxes, classes, segmentations, scores):
cv2.rectangle(img,(x,y), (x2, y2),(0,0,255),2)
print(bboxes)
5. 绘制边界框
绘制边界框以确保我们正确地识别了物体。
for bbox, class_id, seg, score in zip(bboxes, classes, segmentations, scores):
cv2.rectangle(img,(x,y), (x2, y2),(0,0,255),2)
6. 绘制多边形
以下是opencv的格式:cv2.polylines(image, [pts], isClosed, color, thickness)
for bbox, class_id, seg, score in zip(bboxes, classes, segmentations, scores):
cv2.rectangle(img,(x,y), (x2, y2),(0,0,255),2)
cv2.polylines(img,[seg], True, (255,0,0), 2)7. 在图像中显示类别ID
for bbox, class_id, seg, score in zip(bboxes, classes, segmentations, scores):
cv2.rectangle(img,(x,y), (x2, y2),(0,0,255),2)
cv2.polylines(img,[seg], True, (255,0,0), 2)
cv2.putText(img,str(class_id), (x, y-10), cv2.FONT_HERSHEY_PLAIN, 2, (0,0,255),2)
8. 若要填充形状,只需使用FillPoly
for bbox, class_id, seg, score in zip(bboxes, classes, segmentations, scores):
cv2.rectangle(img,(x,y), (x2, y2),(0,0,255),2)
cv2.polylines(img,[seg], True, (255,0,0), 2)
cv2.putText(img,str(class_id), (x, y-10), cv2.FONT_HERSHEY_PLAIN, 2, (0,0,255),2)
cv2.fillPoly(img, pts=[seg], color=(255, 0, 0))
9. 现在加载我们自己的图像
现在将自己的权重和图像添加到pycharm中
更改以下代码
img = cv2.imread("rugby.jpg")
→ img = cv2.imread("container.jpg")
ys = YOLOSegmentation('yolov8m-seg.pt')
→ ys = YOLOSegmentation('best.pt')
img = cv2.imread("rugby.jpg")
ys = YOLOSegmentation('yolov8m-seg.pt')img = cv2.imread("container.jpg")
ys = YOLOSegmentation('best.pt')10. 测试图像
这是Pycharm中的测试结果。根据data.yaml文件,类别ID为0(蓝色),1(灰色),2(绿色),3(红色)和4(黄色)。


9.1 分数
分数按照Roboflow中的顺序,生成为data.yaml文件。

我们可以看到灰色颜色有一个重复的问题,左侧被认为是灰色物体。
9.2 分数
分数显示蓝色和黄色的检测分数相对较高。最差的得分是灰色,因为其中一个物体被过度检测。

10. 现在将其转换为TFLite模型
要转换为TFlite模型,只需运行以下命令
!yolo export model=/content/runs/segment/train2/weights/best.pt format=tflite
结论
正如您所看到的,通过物体分割,我们可以获得更精确的位置和边界框。尝试这个方法,看看是否可以将它与其他OpenCV函数一起使用!
参考文献
Ref1:https://nirmalamurali.medium.com/image-classification-vs-semantic-segmentation-vs-instance-segmentation-625c33a08d50
Ref2:https://pysource.com/2023/02/21/instance-segmentation-yolo-v8-opencv-with-python-tutorial/
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









