






点击下方卡片,关注“小白玩转Python”公众号

图像分割是一门教会机器不是以像素,而是以物体、边界和等待被理解的故事来看待世界的艺术。图像分割是计算机视觉中的一个关键任务,它涉及将图像分割成多个部分,从而更容易分析图像内的不同物体或区域。近年来,为了在这一领域实现最先进的性能,开发了许多模型,每个模型都带来了独特的优势。下面,我们探讨了2024年的十大图像分割模型,详细说明了它们的工作原理、优点和缺点。
1. 由Meta AI开发的Segment Anything Model(SAM)
论文:https://arxiv.org/abs/2304.02643
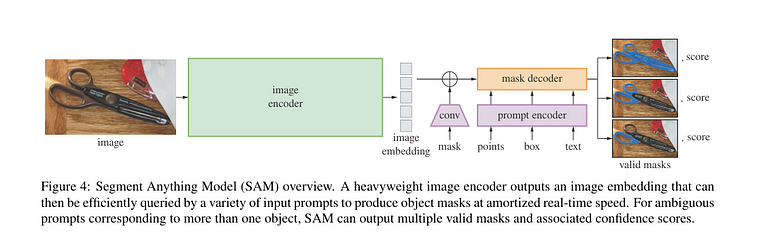
SAM是一个多功能的分割模型,旨在与任何图像一起工作,允许用户通过几次点击就能执行物体分割。它支持各种类型的输入提示,如边界框或文本,使其非常灵活。SAM利用大规模标注图像数据集,采用基于提示的分割方法。它使用视觉变换器(ViTs)作为骨干,并根据用户指定的提示适应不同的分割需求。
优点
多功能:可以处理多种类型的分割提示。
可扩展:在大规模数据集上预训练,使其具有很高的泛化能力。
快速:接近实时性能,适用于交互式应用。
缺点
高计算需求:训练和推理需要大量资源。
有限的细粒度控制:在复杂图像中可能难以处理小而精确的细节。
2. 由FAIR开发的DINOv2
论文:https://arxiv.org/abs/2304.07193

DINOv2基于自监督学习,产生高质量的图像特征,这些特征可以用于分割和其他视觉任务。与其前身不同,DINOv2不需要手动标记的数据进行训练。DINOv2使用ViT架构,通过自监督学习训练以理解物体边界和语义。预训练后可以微调以用于分割任务。
优点
无标签依赖:在不需要标记数据集的情况下实现高性能。
可转移特征:可以适应各种下游任务。
缺点
不专门用于分割:需要微调以在分割中获得最佳性能。
潜在过拟合:在微调期间可能在特定数据集上过拟合。
3. Mask2Former
论文:https://arxiv.org/abs/2112.01527
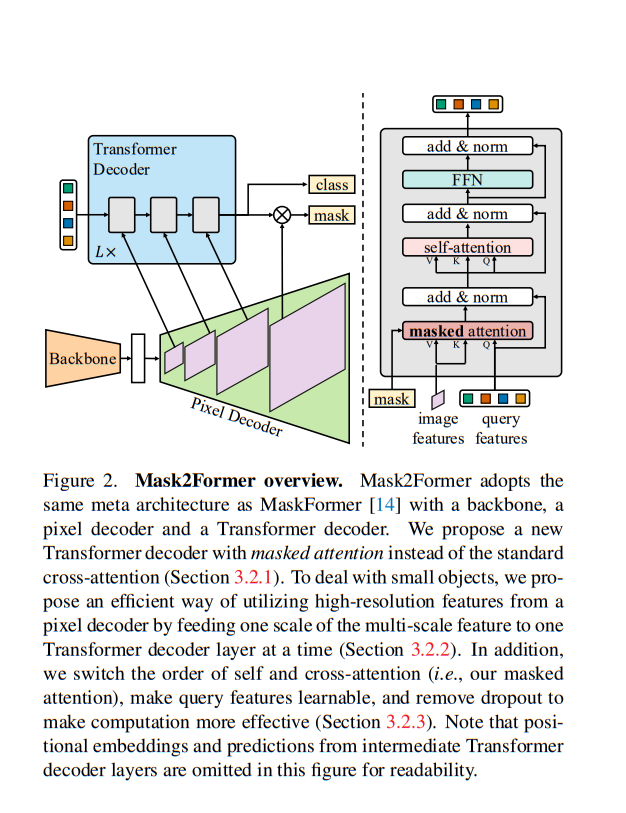
Mask2Former是一个通用的图像分割模型,将语义分割、实例分割和全景分割任务统一到一个框架中。该模型引入了一个掩码注意力变换器,其中注意力机制应用于掩码标记。这使得模型能够专注于重要区域并相应地进行分割。
优点
统一框架:可以高效处理多种分割任务。
高准确度:在各种基准测试中取得了最先进的结果。
缺点
复杂架构:基于变换器的方法资源密集型。
训练难度:需要大量的计算能力进行训练。
4. Swin Transformer
论文:https://arxiv.org/abs/2103.14030
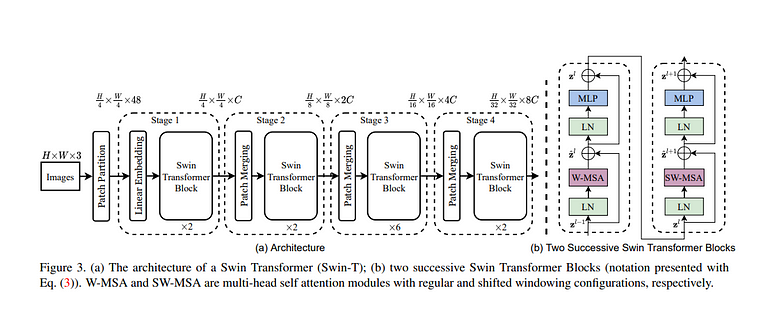
Swin Transformer是一个为计算机视觉任务设计的层次变换器模型,包括图像分割。它通过引入移位窗口机制,建立在将变换器用于视觉任务的思想之上。Swin Transformer采用基于窗口的注意力机制,每个窗口处理图像的局部区域,允许高效且可扩展的分割。
优点
高效注意力:基于窗口的机制减少了计算负荷。
层次表示:产生多尺度特征图,提高分割准确度。
缺点
有限的全局上下文:专注于局部区域,可能错过全局上下文。
复杂性:实现和微调需要高级知识。
5. SegFormer
论文:https://arxiv.org/abs/2105.15203
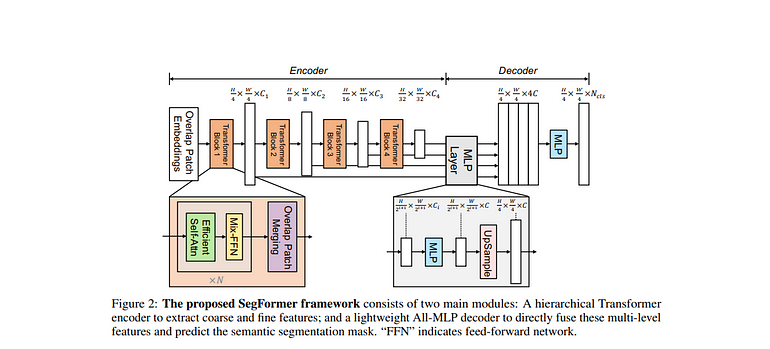
SegFormer是一个简单而高效的基于变换器的模型,用于语义分割,不依赖于位置编码,并使用层次架构进行多尺度特征表示。SegFormer将轻量级MLP解码器与变换器集成,创建多尺度特征层次结构,既提高了性能又提高了效率。
优点
简单高效:避免了像位置编码这样的复杂设计选择。
强大的泛化能力:在各种分割任务中表现良好。
缺点
仅限于语义分割:不如其他一些模型多功能。
缺乏细粒度控制:可能在较小的物体上挣扎。
6. MaxViT
论文:https://arxiv.org/abs/2204.01697
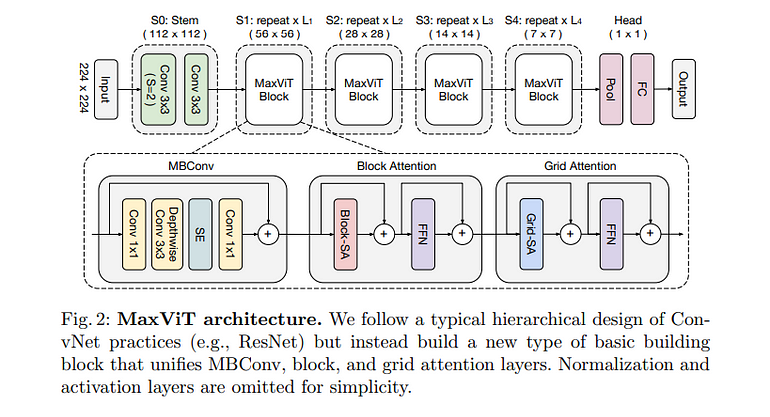
MaxViT引入了一个多轴变换器架构,结合了局部和全局注意力机制,为各种视觉任务,包括分割,提供了强大的结果。MaxViT利用基于窗口和基于网格的注意力,允许模型有效地捕捉局部和全局依赖关系。
优点
全面注意力:在局部和全局特征提取之间取得平衡。
多功能:在各种视觉任务中表现良好。
缺点
高复杂性:需要大量的计算资源进行训练和推理。
难以实施:复杂的架构使其在实践中更难应用。
7. HRNet
论文:https://arxiv.org/pdf/1908.07919v2
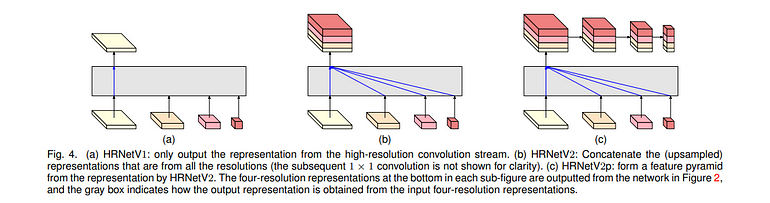
HRNet旨在在整个模型中保持高分辨率表示,与传统架构不同,后者会下采样中间特征图。HRNet使用并行卷积构建高分辨率表示,确保在整个网络中保留空间信息。
优点
高分辨率输出:在分割过程中擅长保留细节。
强大的性能:在基准测试中始终提供高准确度。
缺点
重型模型:计算成本高且体积大。
推理速度慢:比一些更轻的模型慢,因此不太适合实时应用。
8. Deeplabv3+
论文:https://arxiv.org/abs/1802.02611
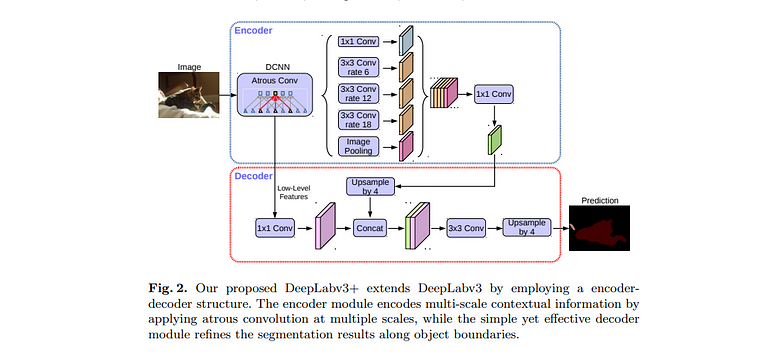
DeepLabv3+是一个用于语义分割的强大且广泛使用的模型,它利用了空洞卷积和空间金字塔池化模块来捕获多尺度上下文信息。DeepLabv3+在多个速率下应用空洞卷积以捕获多尺度特征,然后是解码器模块用于精确的物体边界。
优点
高度准确:在语义分割任务中取得了顶级性能。
支持良好:在工业和研究中广泛使用,有多种实现可用。
缺点
资源密集型:需要大量的内存和计算能力。
不适合实时应用:与最新模型相比相对较慢。
9. U-Net++
论文:https://arxiv.org/abs/1807.10165
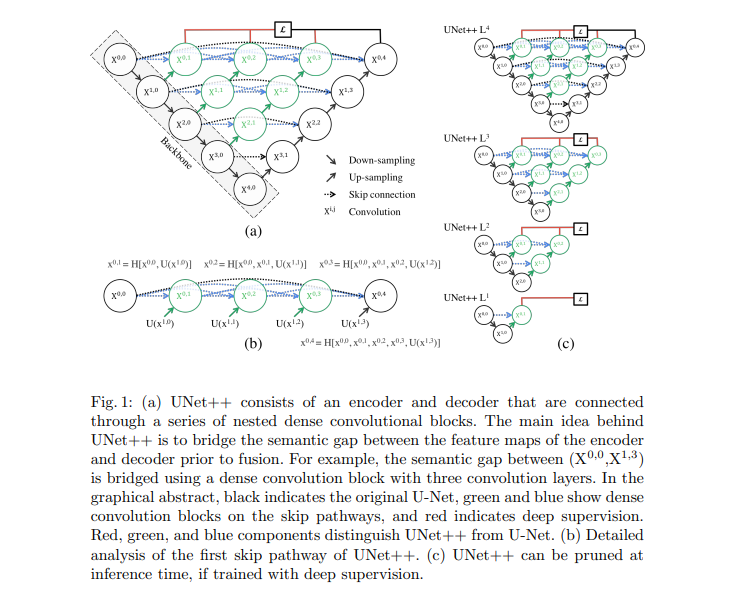
U-Net++是流行的U-Net架构的嵌套版本,旨在提高医学图像分割的性能。U-Net++通过一系列嵌套和密集的跳跃连接修改了原始的U-Net,帮助更好地捕获空间特征。
优点
在医学应用中强大:专门为医学图像分割任务设计。
提高准确性:在许多情况下比原始的U-Net取得了更好的结果。
缺点
医学专注:不如列表中的其他模型通用。
资源需求:由于其嵌套架构,需要更多资源。
10. GC-Net(全局上下文网络)
论文:https://arxiv.org/abs/2012.13375

GC-Net引入了一个全局上下文模块,该模块捕获图像中的长距离依赖关系,使其适用于语义和实例分割任务。全局上下文模块从整个图像中聚合上下文信息,允许在复杂场景中更好地分割准确度。GC-Net使用全局上下文块通过从整个图像而不是仅局部区域捕获上下文来增强特征图。这种全局视图允许模型更准确地分割物体,特别是在上下文重要的情况下(例如,大型或被遮挡的物体)。
优点
捕获长距离依赖关系:非常适合分割上下文重要的复杂图像。
高效:尽管功能强大,全局上下文模块计算效率高,适合各种应用。
缺点
有限的实时应用:尽管效率高,但在需要极快速推理时间的场景中仍可能挣扎。
未针对小物体优化:由于其专注于全局上下文,可能在小物体上挣扎。
TIPS: 上述突出显示的模型代表了2024年的顶级图像分割,每个模型都提供了针对不同任务和上下文的独特优势。从像SAM和Mask2Former这样的多功能框架到像U-Net++和GC-Net这样的高度专业化架构,该领域随着效率和准确性的进步不断发展。在选择分割模型时,考虑特定用例和资源限制至关重要。像Swin Transformer和DeepLabv3+这样的高性能模型提供了出色的准确性,但像SegFormer和GC-Net这样的更轻、更高效的模型可能更适合实时应用。这个动态且快速发展的领域无疑将继续看到突破,新模型将推动计算机视觉领域的可能性边界。
· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者删除
YOLO11
YOLO · 目录
上一篇探索 YOLO11:更快、更智能、更高效

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









