






最近因为个人学习需要,简单调研了一下图像分割模型,做了个小汇总。以下是一些常见的深度学习图像分割网络:
1. FCN(全卷积网络):
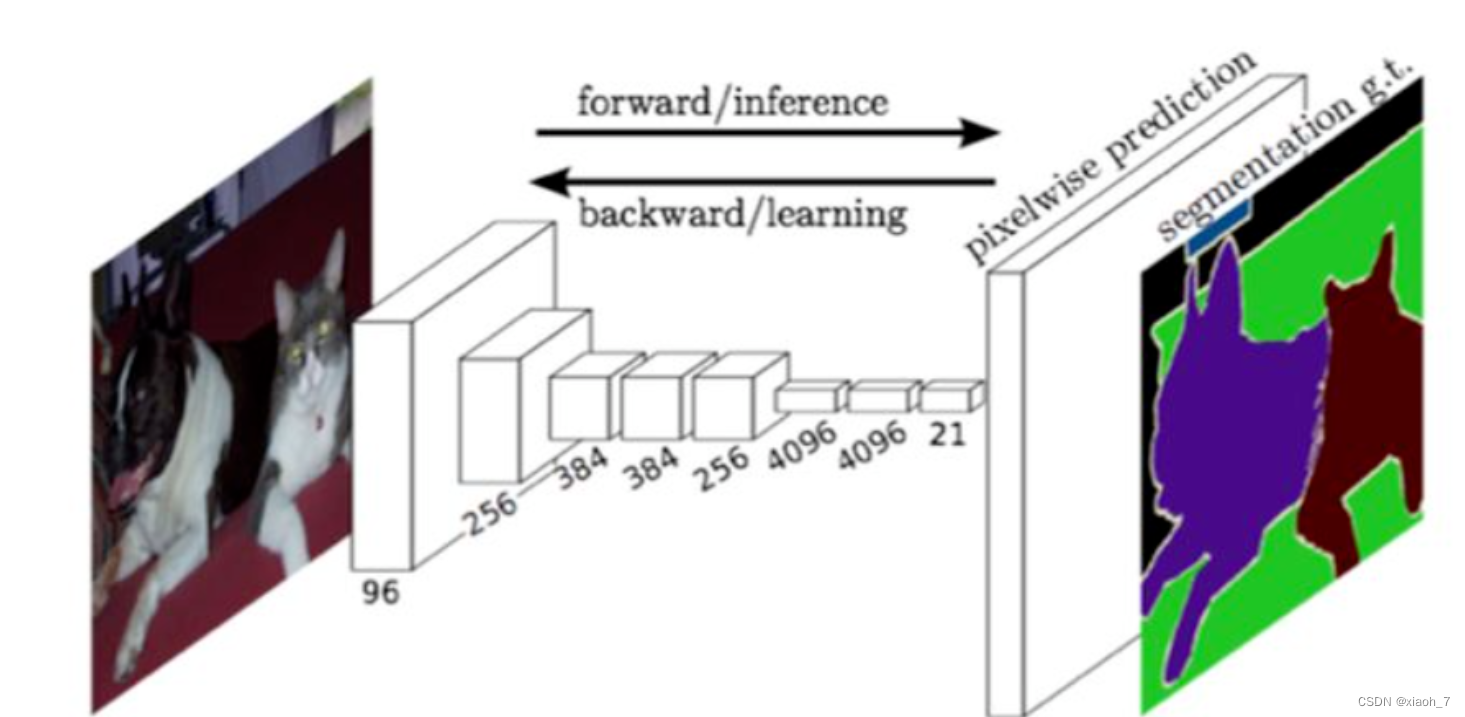
FCN是一种端到端的图像分割方法,它采用全卷积网络对图像进行像素级的分类,从而实现了图像分割。
FCN将传统CNN中的全连接层替换为卷积层,可以接受任意尺寸的输入图像,并通过反卷积操作将特征图恢复到原始图像大小,实现像素级的预测。
2. U-Net:
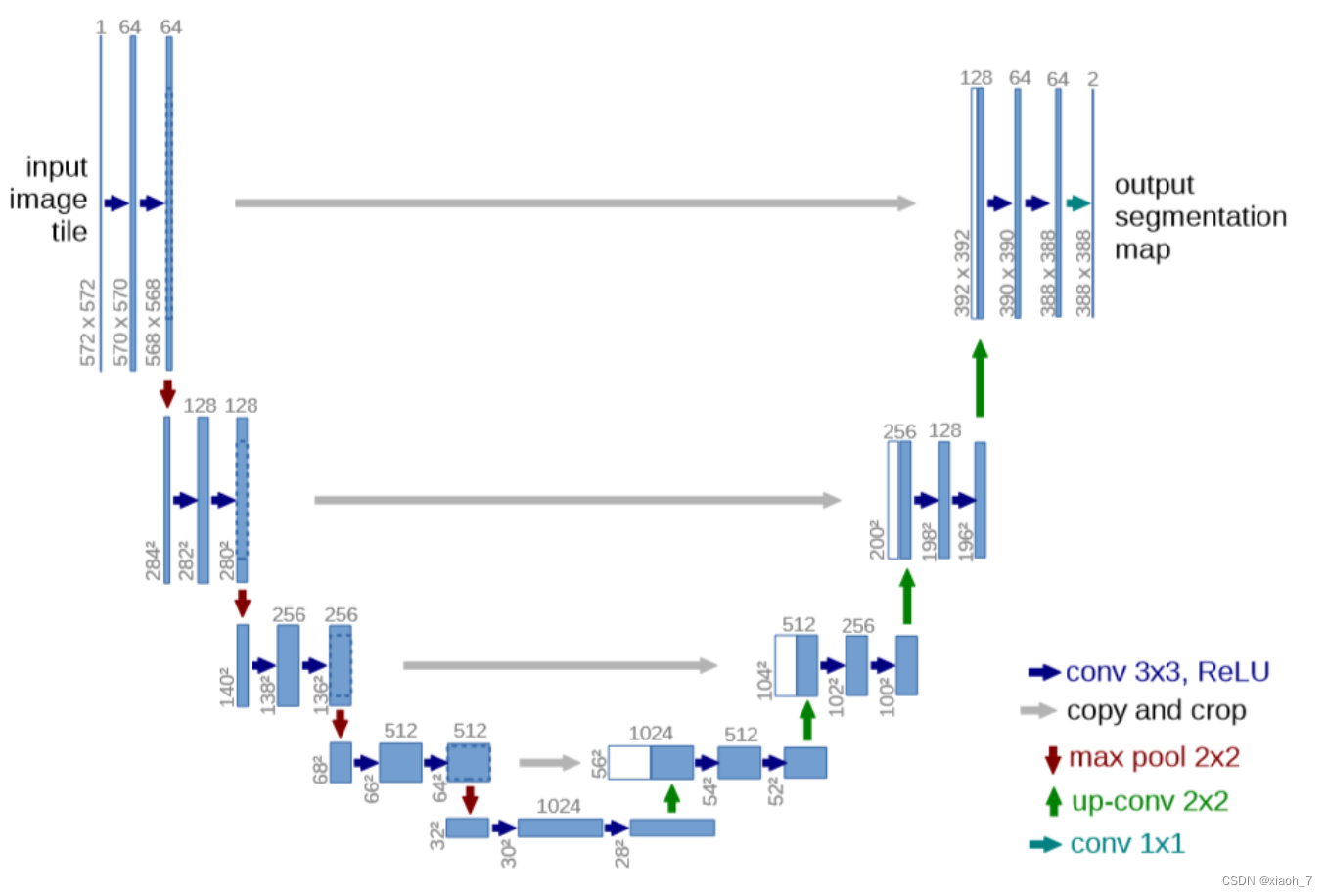
U-Net是一种在生物医学图像分割领域广泛应用的网络结构。
它采用编码器-解码器的结构,编码器逐渐减小特征图的尺寸并增加通道数,以捕获图像的上下文信息;解码器则逐渐恢复特征图的尺寸和细节,同时融合编码器中的相应特征图,以精确定位分割边界。
3. DeepLab:
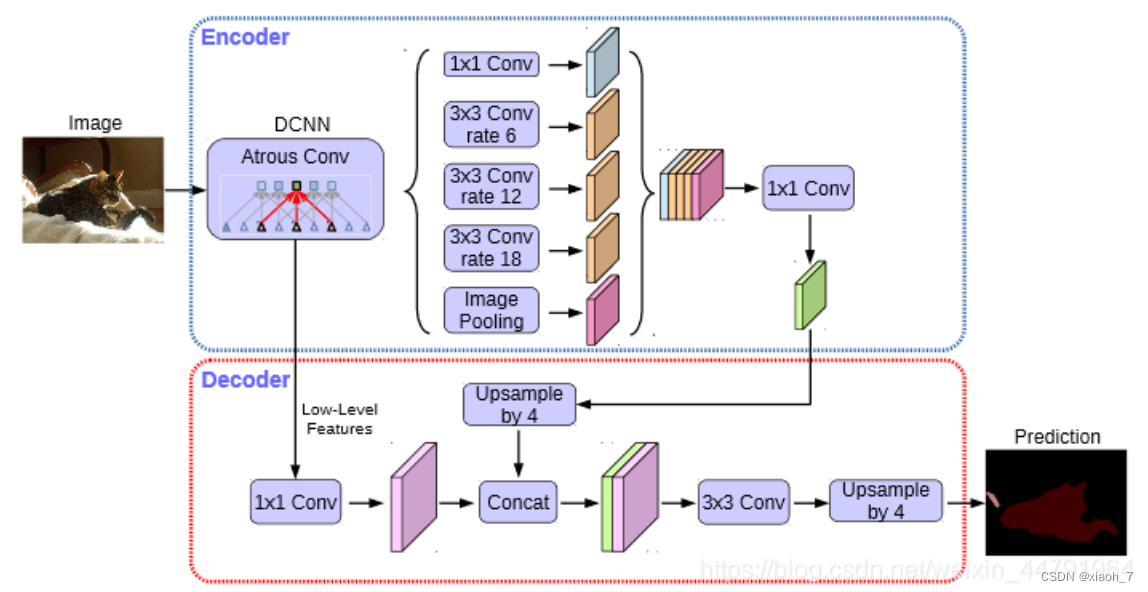
DeepLab系列网络结合了深度卷积神经网络(DCNNs)和概率图模型(如条件随机场CRF)来进行图像分割。
它采用空洞卷积(atrous convolution)来扩大感受野,同时保持特征图的分辨率,从而能够捕获更多的上下文信息。
DeepLab还引入了空洞空间金字塔池化(ASPP)模块,以多尺度捕获图像中的对象。
4. Mask R-CNN:
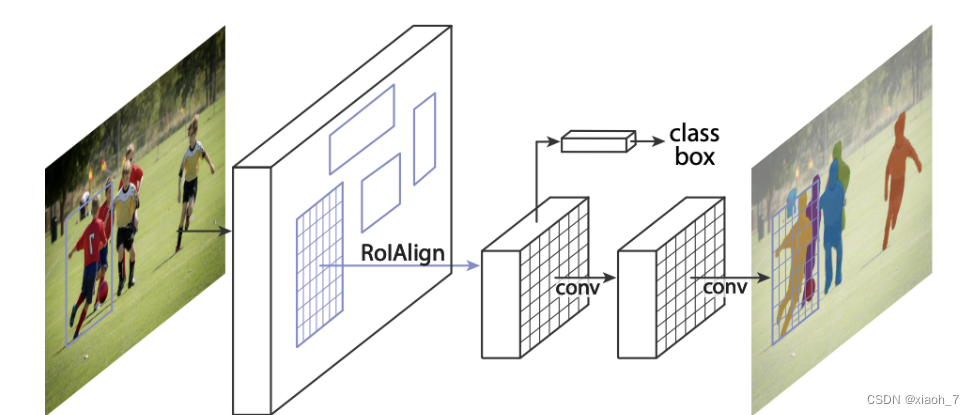
Mask R-CNN是在Faster R-CNN基础上扩展的一个网络,主要用于目标检测和图像分割任务。
它在每个检测到的对象上添加一个额外的掩码分支,以生成对象形状的像素级预测。
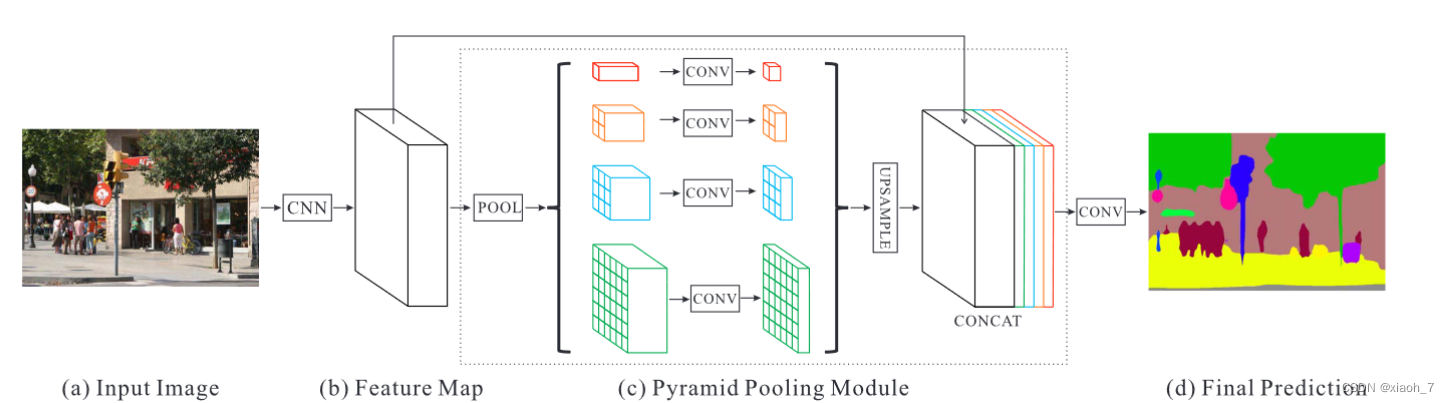
5. PSPNet(金字塔场景解析网络):
PSPNet提出了一种金字塔池化模块,该模块可以聚合不同区域的上下文信息,从而提高了图像分割的准确性。
它通过金字塔池化操作捕获不同尺度的上下文信息,并将其与原始特征图融合,以产生最终的分割结果。
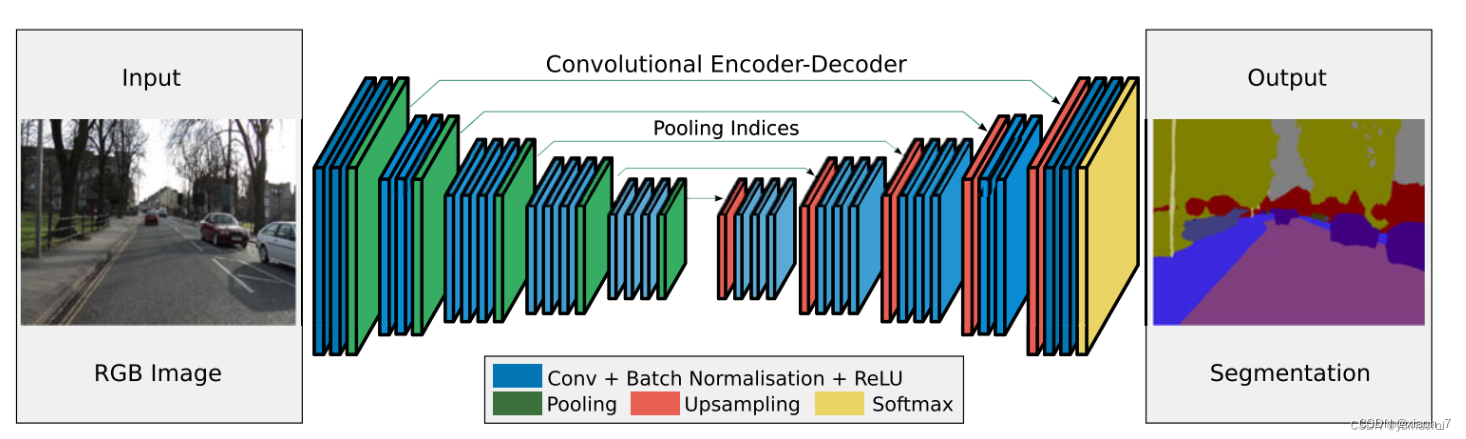
6. SegNet:
SegNet是一个用于图像分割的编码器-解码器网络结构。
它的编码器部分与VGG16网络类似,但解码器部分采用了上采样和对应的编码器特征图的组合,以恢复图像的细节和分辨率。
我在以下是将以上图像分割常见深度学习网络结构汇总为表格:
| 网络名称 | 描述 | 主要特点 |
|---|---|---|
| FCN (全卷积网络) | 端到端的图像分割方法 | 替换全连接层为卷积层,接受任意尺寸输入,通过反卷积恢复特征图大小 |
| U-Net | 编码器-解码器结构,常用于医学图像分割 | 编码器减小尺寸并增加通道数,解码器恢复尺寸和细节,融合编码器特征 |
| DeepLab | 结合DCNNs和概率图模型(如CRF) | 采用空洞卷积扩大感受野,引入ASPP模块捕获多尺度信息 |
| Mask R-CNN | 在Faster R-CNN基础上扩展,用于目标检测和图像分割 | 在每个检测到的对象上添加掩码分支,生成像素级预测 |
| PSPNet (金字塔场景解析网络) | 引入金字塔池化模块,聚合不同区域上下文信息 | 金字塔池化操作捕获多尺度上下文,与原始特征图融合 |
| SegNet | 编码器-解码器结构 | 编码器与VGG16类似,解码器采用上采样和编码器特征图组合 |
版权声明
本博客内容仅供学习交流,转载请注明出处。















 3975
3975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









