







排序算法有8种:
插入排序:直接插入,希尔排序
选择排序:选择,堆排序
交换排序:冒泡排序,快速排序
归并排序
基数排序
上面八种排序我们可以用一个场景进行串联:——打针
记忆方法
护士给我们治病打针,用针管插到血管中的方式有两种一个是直接插入(直接插入排序),还有个先画一个S符号然后插入(shell排序),药物进入到血液中后,进行对好的细胞和有病的细胞进行区分(选择排序),我们可以简单随便进行选择(简单选择),或者可以将细胞全拿过来堆在一起来选择(堆排序),找到后有病细胞后,我们将其中有问题的蛋白质跟好的蛋白质交换(交换排序),可以快速的吹个泡泡(快排,冒泡)让自己先处于安全的空气环境然后开始治疗,那些有问题的蛋白质被替换出来后,由我们的这些药物进行搜集并归类在一起(归并排序),最后由我们的jiji(基数排序)将这些无用的东西排出去
这只是方便记住有什么,关键还是这些排序怎么用才是最主要的
经典排序算法总结与实现 ---python
经典排序算法在面试中占有很大的比重,也是基础,为了未雨绸缪,在寒假里整理并用Python实现了七大经典排序算法,包括冒泡排序,插入排序,选择排序,希尔排序,归并排序,快速排序,堆排序。希望能帮助到有需要的同学。之所以用Python实现,主要是因为它更接近伪代码,能用更少的代码实现算法,更利于理解。
本篇博客所有排序实现均默认从小到大。
冒泡,选择,插入,都是从前向后。
一、冒泡排序 BubbleSort
介绍:
冒泡排序的原理非常简单,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
源代码:(python实现)
|
冒泡排序思想,子循环是(判断+交换0) ,主循环是 给自循环一个数组长度的次数。
优化; 若当前子循环中没有发生交换,则说明当前数组满足条件。
def maopao(nums):
global count
for i in range(len(nums)-1):
Flag=True
for j in range(len(nums)-1-i):
print(nums)
if nums[j+1]<nums[j]:
nums[j+1],nums[j]=nums[j],nums[j+1]
Flag=False
if Flag:
break
return nums
print(maopao([6,7,4,2,8,1,4,9,6]))
二、选择排序 SelectionSort
介绍:
选择排序无疑是最简单直观的排序。它的工作原理如下。
步骤:
- 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 以此类推,直到所有元素均排序完毕。
源代码:(python实现)
def xuanze(nums):
n=len(nums)
for i in range(0,n):
min=i
for j in range(i+1,n):
if nums[j]<nums[min]:
min=j
nums[min],nums[i]=nums[i],nums[min]
return nums
print(xuanze([6,7,4,2,8,1,4,9,6]))
三、插入排序 InsertionSort
介绍:
插入排序的工作原理是,对于每个未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
步骤:
- 先置条件,从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果被扫描的元素(已排序)大于新元素,将该元素后移一位
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
排序演示:

源代码:(python实现)
def charu(nums):
n=len(nums)
for i in range(1,n):
if nums[i]<nums[i-1]:
tmp=nums[i]
min=i
for j in range(i-1,-1,-1):
if nums[j]>tmp:
nums[j+1]=nums[j]
min=j
else:
break
nums[min]=tmp
return nums
print(charu([6,7,4,2,8,1,4,9,6]))
四、希尔排序 ShellSort
介绍:
希尔排序,也称递减增量排序算法,实质是分组插入排序。由 Donald Shell 于1959年提出。希尔排序是非稳定排序算法。
希尔排序的基本思想是:将数组列在一个表中并对列分别进行插入排序,重复这过程,不过每次用更长的列(步长更长了,列数更少了)来进行。最后整个表就只有一列了。将数组转换至表是为了更好地理解这算法,算法本身还是使用数组进行排序。
例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ]。这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45
排序之后变为:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94
最后以1步长进行排序(此时就是简单的插入排序了)。
源代码:(python实现)
def sorted(nums):
n=len(nums)
gap=round(n/2)
while gap>0:
print(gap)
for i in range(gap,n):
tmp=nums[i]
j=i
while j>=gap and nums[j-gap]>tmp:
nums[j]=nums[j-gap]
j-=gap
nums[j]=tmp
gap=round(gap/2)
return nums
nums=[6,7,4,2,8,1,4,9,6]
print(sorted(nums))
上面源码的步长的选择是从n/2开始,每次再减半,直至为0。步长的选择直接决定了希尔排序的复杂度。在维基百科上有对于步长串行的详细介绍。
五、归并排序 MergeSort
介绍:
归并排序是采用分治法(先递归分解数组,再合并数组。)
先考虑合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
再考虑递归分解,基本思路是将数组分解成left和right,如果这两个数组内部数据是有序的,那么就可以用上面合并数组的方法将这两个数组合并排序。如何让这两个数组内部是有序的?可以再二分,直至分解出的小组只含有一个元素时为止,此时认为该小组内部已有序。然后合并排序相邻二个小组即可。
排序演示:
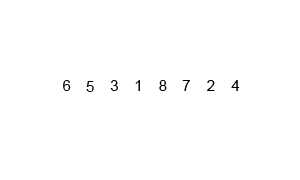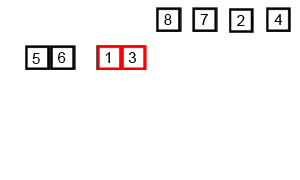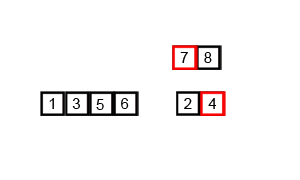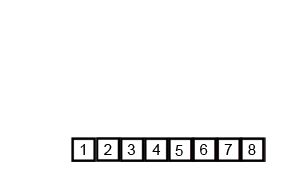
源代码:(python实现)
nums = [1,1,1,2,2,3]
def gui(nums):
if len(nums)<=1:
return nums
mid=len(nums)//2
left=gui(nums[:mid])
right=gui(nums[mid:])
print(left) #[4] [3] [8] [2] [7, 8] [3, 4, 9]
return merge(left,right )
def merge(left,right):
lp,rp=0,0
result=[]
print(left) #[4] [3] [8] [2] [7, 8] [3, 4, 9]
while lp<len(left) and rp<len(right):
if left[lp]<=right[rp]:
result.append(left[lp])
lp+=1
else:
result.append(right[rp])
rp+=1
result+=left[lp:]
result += right[rp:]
return result
if __name__ == '__main__':
nums = [3,4,9,8,7, 2, 3]
a=gui(nums)
print(a)
六、快速排序 QuickSort(选取基准数+双指针)
介绍:
快速排序通常明显比同为Ο(n log n)的其他算法更快,因此常被采用,而且快排采用了分治法的思想,所以在很多笔试面试中能经常看到快排的影子。可见掌握快排的重要性。
步骤:
- 从数列中挑出一个元素作为基准数。
- 分区过程,将比基准数大的放到右边,小于或等于它的数都放到左边。
- 再对左右区间递归执行第二步,直至各区间只有一个数。
排序演示:
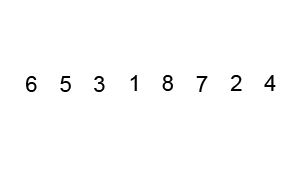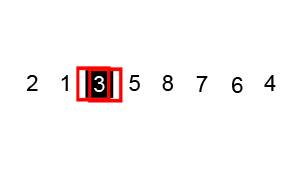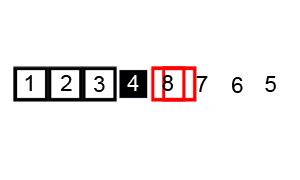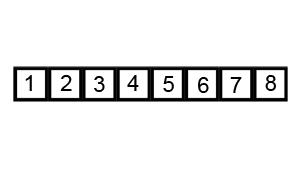
源代码:(python实现)
def qosort(nums,l,r):
if l>=r:
return nums
#tmp=nums[l]
lp=l
rp=r
while lp<rp:
while nums[rp]>=nums[l] and lp<rp: #记住,这里一定是从右指针开始!!否则会出错,
rp-=1
while nums[lp]<=nums[l] and lp<rp:
lp+=1
nums[rp],nums[lp]=nums[lp],nums[rp]
nums[rp],nums[l]=nums[l],nums[rp]
qosort(nums,l,rp-1)
qosort(nums,rp+1,r)
return nums
def kuai_pai(nums):
n=len(nums)
return qosort(nums,0,n-1)
print(kuai_pai([6,7,4,2,8,1,4,9,6]))
七、堆排序 HeapSort
介绍:
堆排序在 top K 问题中使用比较频繁。堆排序是采用二叉堆的数据结构来实现的,虽然实质上还是一维数组。二叉堆是一个近似完全二叉树 。
二叉堆具有以下性质:
- 父节点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
- 每个节点的左右子树都是一个二叉堆(都是最大堆或最小堆)。
步骤:
-
构造最大堆(Build_Max_Heap):若数组下标范围为0~n,考虑到单独一个元素是大根堆,则从下标
n/2开始的元素均为大根堆。于是只要从n/2-1开始,向前依次构造大根堆,这样就能保证,构造到某个节点时,它的左右子树都已经是大根堆。 -
堆排序(HeapSort):由于堆是用数组模拟的。得到一个大根堆后,数组内部并不是有序的。因此需要将堆化数组有序化。思想是移除根节点,并做最大堆调整的递归运算。第一次将
heap[0]与heap[n-1]交换,再对heap[0...n-2]做最大堆调整。第二次将heap[0]与heap[n-2]交换,再对heap[0...n-3]做最大堆调整。重复该操作直至heap[0]和heap[1]交换。由于每次都是将最大的数并入到后面的有序区间,故操作完后整个数组就是有序的了。 -
最大堆调整(Max_Heapify):该方法是提供给上述两个过程调用的。目的是将堆的末端子节点作调整,使得子节点永远小于父节点 。
排序演示:

源代码:(python实现)
def max_dui(nums,start,end): #构建最大堆
root=start
while True:
left=2*root+1
if left>end:
return nums
if left+1 <=end and nums[left]< nums [left+1]:
left+=1
if nums[ left] > nums [root]:
nums [left], nums[root]= nums [root], nums[ left]
root=left
else:
break
def heap_sort(nums) :
n=len(nums)
first=round(n/2) #最后一个非叶子节点
for start in range(first,-1,-1): #从最后节点构建最大堆, 循环结束能找到max(nums)
max_dui(nums,start,n-1)
print('nums',nums)
for end in range(n-1,0,-1): #从最后一个节点构建最大堆,依次找到max top K
nums[end],nums[0]=nums[0],nums[end]
max_dui(nums,0,end-1)
print('nums1',nums)
return nums
print(heap_sort([1,4,7,9,2,10,1,3,1,9]))
桶排序:
def bucket(nums):
buckets=[0]*(max(nums)-min(nums)+1) #建立与列表元素个数相同的桶
for i in range(len(nums)): #给(小到大)桶中放入水
buckets[nums[i]-min(nums)]+=1
result=[]
for i in range(len(buckets)): #从小桶到大桶逐步倒出水
if buckets[i]!=0:
result += [i + min(nums)] * buckets[i]
return result
a=bucket([5,3,6,1,2,7,5,10])
print(a)
总结
下面为七种经典排序算法指标对比情况:

基数排序:非比较的整数排序算法,通过键值比较(将整数按位数切割成不同的数字,然后对每个位数上的数字进行分别比较)
分类:最高有效位(MSD) 或最低有效位(LSD)
数据结构:数组
最坏性能:O(w * n)
最坏情况空间复杂度:O(w + N)















 38万+
38万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









