1.导入模块
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.svm import SVC
2.生成聚类数据
smaples,target = make_blobs(n_samples=40,n_features=2,centers=2)
参数含义:
n_samples是待生成的样本的总数。
n_features是每个样本的特征数。
centers表示类别数。
cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]

3.创建向量机对象,指定内核
svc = SVC(kernel='linear')
4.训练模型
svc.fit(samples,target)
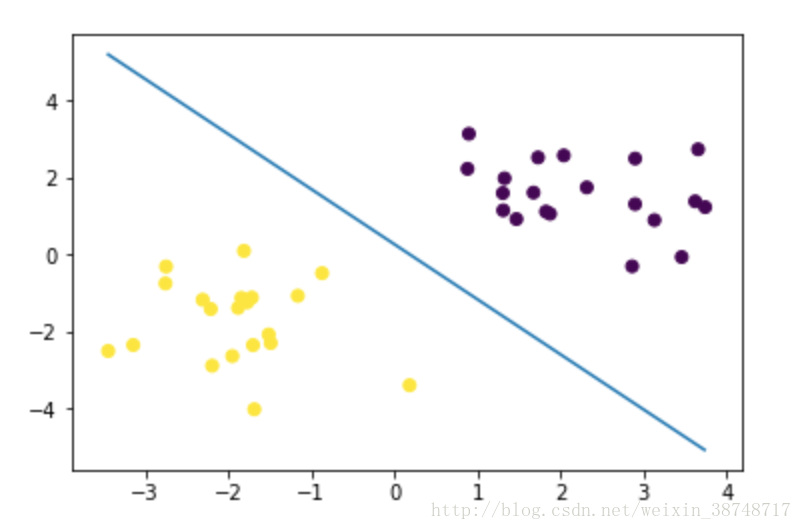
5.确定最大间隔超平面
w = (-svc.coef_[:,0]/svc.coef_[:,1])[0]
k=svc.intercept_[0]
xmin,xmax = samples[:,0].min(),samples[:,0].max()
x= np.arange(xmin,xmax,0.01)
y=w*x+k
plt.plot(x,y)
plt.scatter(samples[:,0],samples[:,1],c=target)
6.获取支持向量
a1 = svc.support_vectors_[0]
a2 = svc.support_vectors_[-1]
display(a1,a2)
7.画出约束边界
- 计算约束边界的截距(斜率和超平面斜率一致,不需要重新计算)
k1 = a1[1]-w*a1[0]
k2 = a2[1]-w*a2[0]
y1 = w*x +k1
y2 = w*x +k2
plt.plot(x,y1,color='blue')
plt.plot(x,y2,color='blue')
plt.plot(x,y)
plt.scatter(samples[:,0],samples[:,1],c=target)
plt.scatter(svc.support_vectors_[:,0],svc.support_vectors_[:,1],color='r')
























 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









