








What I cannot create, I do not understand. - Richard Feynman
前言
你左拥右抱着 Stable Diffusion 和 MidJourney 创造美轮美奂的图片。
你熟练使用着 ChatGPT 和 LLaMa 创造辞致雅赡的文字。
你来回切换着 MuseNet 和 MuseGAN 创造高山流水的音乐。
毋庸置疑,人类最独特的能力就是创造,但在科技日新月异发展的今天,我们通过创建机器来创造!机器可以给定风格绘制原创艺术品 (draw),可以编写一长篇连贯文章 (write),可以创作悦耳的音乐 (compose),还可以为复杂游戏制定获胜策略 (play)。这个科技就是生成式人工智能 (Generative Artificial Intelligence, GenAI),现在只是 GenAI 革命的开始,现在是学习 GenAI 的最佳时机。
1. 生成和判别模型
GenAI 是一个 buzzword,其背后本质是生成模型 (generative model),它是机器学习的一个分支,目标是训练模型以生成与给定数据集相似的新数据。
假设我们有一个马的数据集。首先,我们可以在此数据集上训练生成模型,以捕获控制马图像中像素之间复杂关系的规则。然后,从此模型中进行采样,以创建原始数据集中不存在的但是逼真的马图像,过程如下图所示。
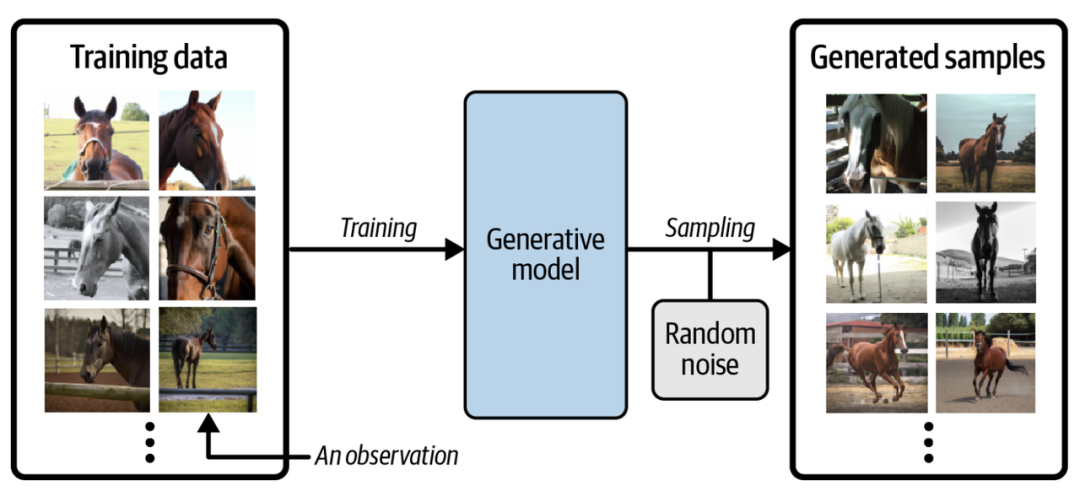
为了真正理解生成模型的目标和重要性,将其与判别模型 (discriminative model) 进行比较是必要的。其实机器学习里大多数的问题都是由判别模型解决的,看以下例子。
假设我们有一个绘画数据集,一些是梵高画的,一些是其他艺术家画的。有了足够的数据,我们就可以训练一个判别模型来预测一幅给定的画是否由梵高所作,过程如下图所示。
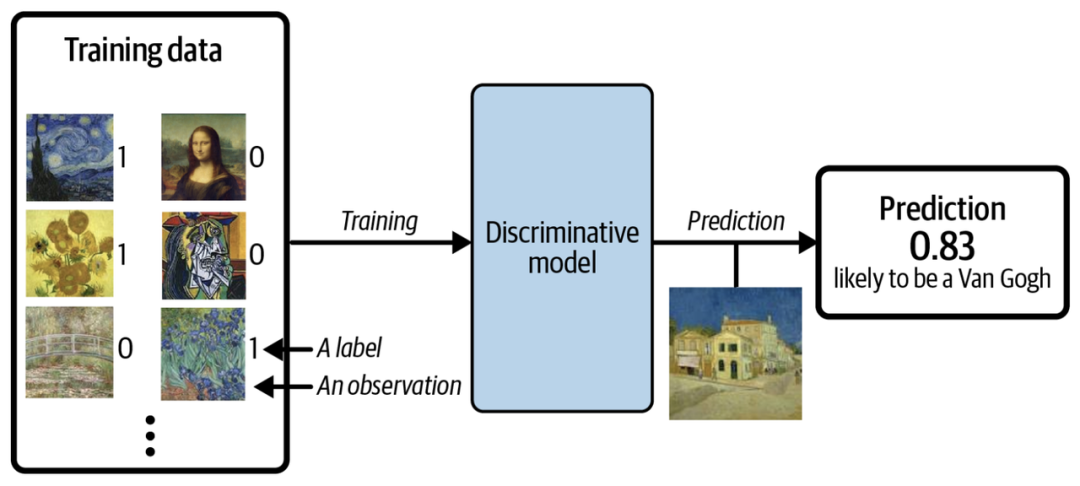
当使用判别模型时,训练集中每个示例都有一个标签 (label),对于以上二分类问题,通常梵高的画的标签为 1,非梵高的画的标签为 0。上图中模型最后预测的概率是 0.83,那么它很有可能是由梵高所作。和判别模型不同的是,生成模型不需要示例里含有标签,因为它的目标是生成新数据,而不是给数据预测标签。
例子看完,让我们用数学符号来精准定义生成模型和判别模型:
判别模型对 p(y|x) 建模,给定特征 x 来估计标签 y 的条件概率。
生成模型对 p(x) 建模,直接估计特征 x 的概率,从这个概率分布中采样即可生成新的特征。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2604
2604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









