







文末有彩蛋!
本文是 Python 系列的第十二篇
机学可视化之 Scikit-Plot
深度学习之 Keras
深度学习之TensorFlow
深度学习之 PyTorch
深度学习之 MXnet
当机器学习工具 Scikit-Learn 遇上了可视化工具 Matplotlib,就衍生出 Scikit-Plot。
Scikit-Plot 是由 Reiichiro Nakano 创建的用在机器学习的可视化工具。它简直就是玩机器学习的数据科学家的福音,能最快速简洁的画出用 Matplotlib 要写很多行语句才能画出的图。每个人都喜欢用一行代码 (one-liner) 完成任务。
安装 Scikit-Plot 非常简单。
pip install scikit-plot注:要运行 Scikit-Plot 里面的函数,确定你已经安装好了 Scikit-Learn 和 Matplotlib。
要使用 Scikit-Plot,首先要引用它并起个别名skplt。
import scikitplot as skpltScikit-Plot 有四大模块,度量模块、估计器模块、聚类模块和降维模块。如下图所示

从 Scikit-Plot 官网中,搜集出这四大模块里所有的细分函数:
scikitplot.metrics
plot_confusion_matrix:分类的混淆矩阵
plot_precision_recall:分类的查准查全
plot_roc:分类的 ROC 曲线
plot_ks_statistic
plot_silhouette:度量聚类好坏的轮廓系数
plot_calibration_curve
plot_cumulative_gain
plot_lift_curve
scikitplot.estimators
plot_learning_curve:学习曲线
plot_feature_importances:特征重要性
scikitplot.cluster
plot_elbow_curve:决定簇个数的肘部曲线
scikitplot.decomposition
plot_pca_component_variance:可解释方差
plot_pca_2d_projection:高维投影到二维
红色的函数是比较常见的,本帖用三个数据集来讲解它们,但不是单单讲解这些绘图函数,而花大量时间画大量图标来详细讲解相关的知识点,每个绘图函数和要明晰的知识点如下:
plot_pca_component_variance:主成分方差是什么?
plot_pca_2d_projection:为什么要降维?
plot_confusion_matrix:混淆矩阵是什么?
plot_precision_recall:查准率和查全率是什么?
plot_roc:ROC 和 AUC 是什么?
plot_silhouette:轮廓系数是什么?
plot_elbow_curve:肘部方法是什么?
plot_learning_curve:学习曲线是什么?
plot_feature_importances:特征重要性是什么?
此外,我们对比 Scikit-Plot 和 Matplotlib,思路就是用后者来复现前者绘制的图。前者只要一行代码,后者需要大量代码,通过对比,读者也会更加喜欢 Scikit-Plot 的便捷性。
本帖目录如下:
第一章 - 手写数字数据集
1.1 数据介绍
1.2 可解释方差
1.3 降维投影
1.4 混淆矩阵
1.5 查准率查全率
1.6 接受者操作特征曲线
第二章 - 鸢尾花数据集
2.1 数据介绍
2.2 肘部曲线
2.3 轮廓系数
第三章 - 乳腺癌数据集
3.1 数据介绍
3.2 学习曲线
3.3 特征重要性
第四章 - Scikit-Plot vs Matplotlib
4.1 plot_pca_component_variance
4.2 plot_pca_2d_projection
4.3 plot_confusion_matrix
4.4 plot_precision_recall
4.5 plot_roc
4.6 plot_silhouette
4.7 plot_elbow_curve
4.8 plot_learning_curve
4.9 plot_feature_importances
总结

用谷歌和百度搜索了下,除了 Scikit-Plot 的官方文档,只有一篇关于它的英文博客,而且内容也不是很丰富,希望这篇是中文版的第一篇介绍 Scikit-Plot 的好文。
1.1
数据介绍
本小节使用的数据是
手写数字数据集 (MNIST)
MNIST 有 70000 张规格较小的手写数字图片,由美国的高中生和美国人口调查局的职员手写而成。每张图片有 784 个特征。这是因为每个图片都是 28*28 像素的,并且每个像素的值介于 0~255 之间。
下图以数字 8 举例,看看如何将一张图片转换成 784 个像素的。
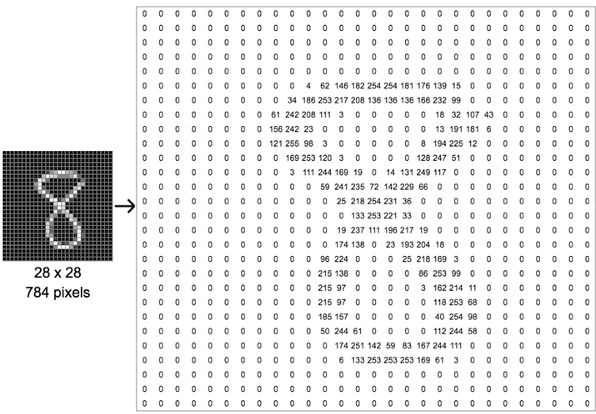
MNIST 的类别就 10 类,就是数字 0 到 9。
由于 MNIST 的数据集比较大,在 sklearn 中用 fetch_的方法,详细解释见〖机器学习之 Sklearn〗的小节 2.2 。再用 train_test_split 的方法将训练集和测试集分成 80:20 (test_size=0.2)。
from sklearn.model_selection import train_test_split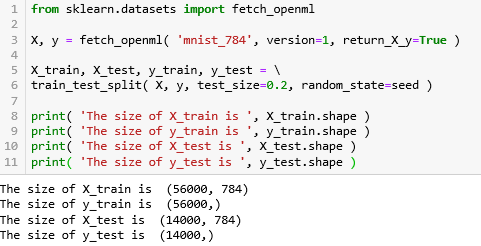
70000 张的图片分成含 56000 张的训练集和含 14000 张的测试集,而且 X 有 784 个特征 (784 个像素),X 和 y 的形状为
X = (样本数,特征数)
y = (样本数,)
照片像素在 0 到 255 之间,做正规化 (除以 255) 使得 X_train 和 X_test 里的元素在 0 和 1 之间。
X_train, X_test = X_train/255.0, X_test/255.0取 y 里不重复的类别个数,10 类,分别是数字 0, 1, 2, ..., 9。
n_class = len(np.unique(y))n_class
10看看训练集中前 100 张图片和对应的标签 (左下角蓝色小字)。


在下面五节我们来多分类 0 到 9 这十个数字。由于 784 个特征太多,首先我们想用「主成分分析」做特征降维,并投影在二维平面可视化数据,之后再用「对率回归」来分类,并画出相应的混淆矩阵、查准率查全率,接受者操作特征曲线等指标。
1.2
可解释方差
Scikit-Plot 中的 plot_pca_component_variance 函数可以画出「主成分分析」里「主成分个数-解释方差比率」一一对应的关系图。
先看一个「主成分分析」的知识点。
PCA 经常用于减少数据集的维数,同时保持数据集中的 对方差贡献最大 的特征。
关于方差的直观解释如下图,深青点是数据,红色轴和灰色轴可想象成两个超平面,红点和灰点则是数据在超平面上的投影。那么方差是衡量投影数据的分散程度。
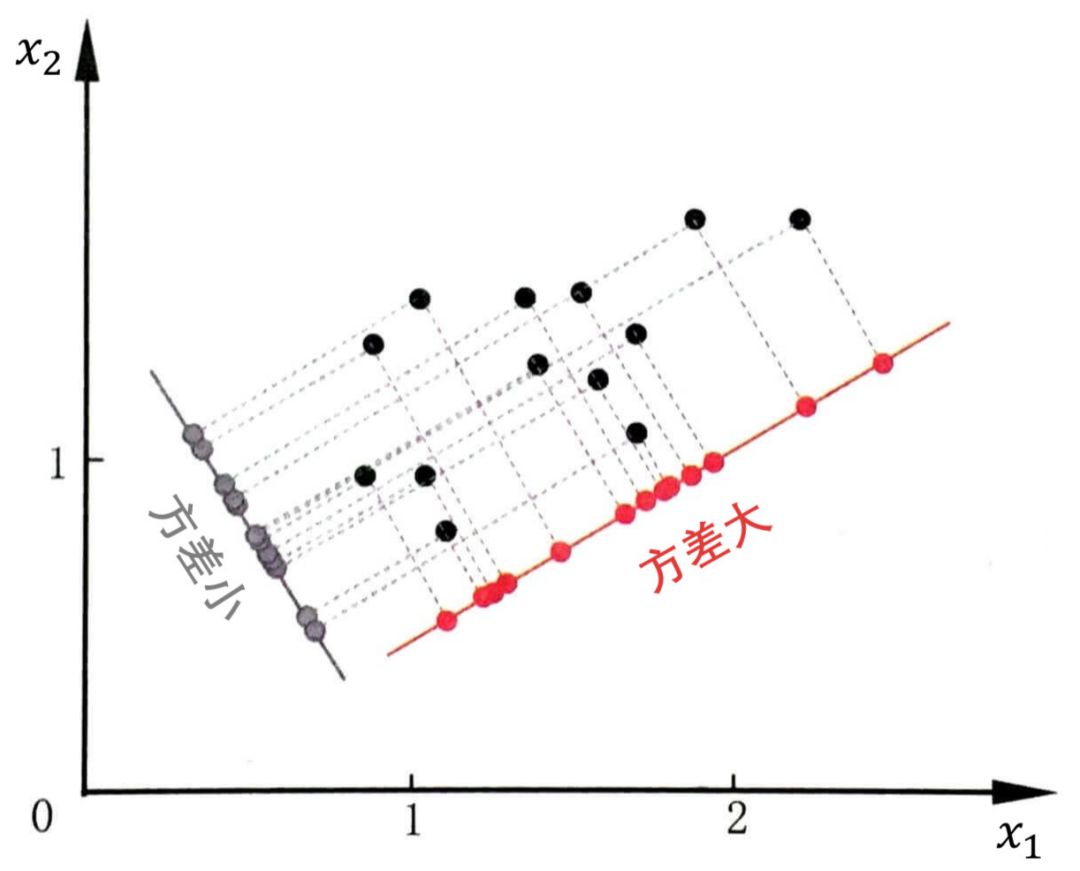
显然把数据投影在 红色轴 上 (大方差) 以后更容易分类。因此 PCA 做的事情就是让样本点在某个超平面上的投影能尽可能地分开,即需最大化投影点的方差。
我们总听到有人说「前 3 个主成分解释了 75% 的总方差」,这到底是什么意思呢?首先 PCA 每个主成分 PC 都可以解释数据中一部分方差,排序图如下,方差率越高,说明越是重要的 PC。
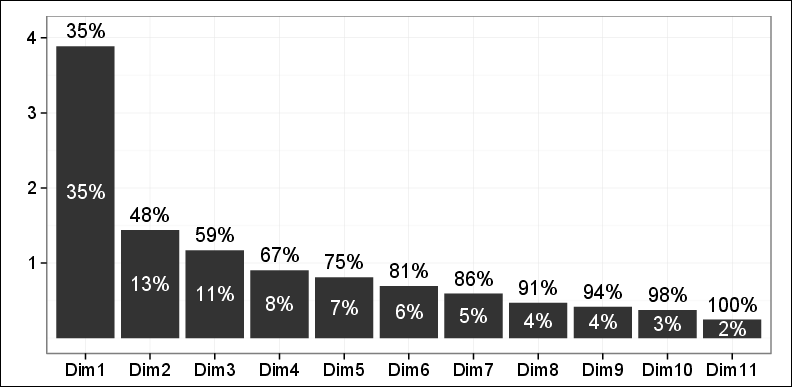
总方差等于每一个 PC 的方差之和,而 PC i 可解释的方差比率等于
方差比率 i = 方差 i /总方差
具体来讲
第一个 PC 解释了 35% 的总方差
前两个 PC 解释了 48% 的总方差
...
前十个 PC 解释了 98% 的总方差
所有 PC 解释了 100% 的总方差
显然,用到的 PC 越多,解释了方差比率也就越高。一般来说,我们都先定一个「可解释方差」的阈值 (threshold),然后找出对应的 PC 的个数。用上图的例子,我们希望 80% 的方差能被解释,因此选前 6 个 PC。
首先创建 PCA 估计器命名为 pca,再拟合训练集X_train。
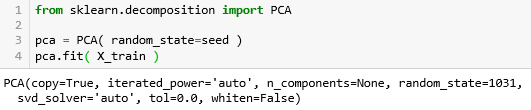
函数 plot_pca_component_variance 用到的参数有 3 个:
pca:PCA 估计器
target_explained_variance:可解释方差的比率
figsize:图片大小
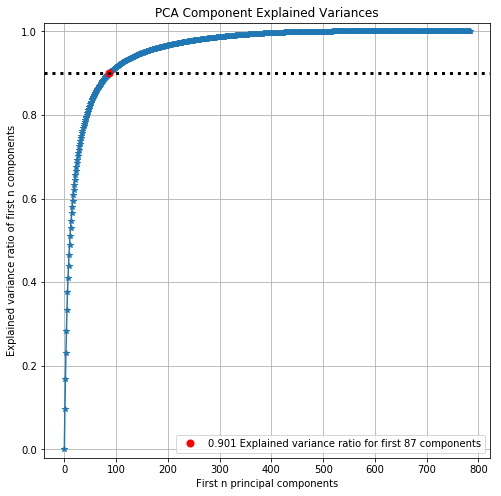
上图展示了两条信息:
蓝色曲线 - PC 个数和可解释方差比率呈递增关系,而且一开始猛增,后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5218
5218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









