









A*搜索算法介绍
Intro部分
原文链接link
我们的目的是让目标从起点移动到重点。
- Pathfinding解决的是找到从起点到终点的优化路径问题——这一路径避免障碍、敌人,最小化耗费(汽油、时间、距离、装备、金钱等)
- Movement解决的是选择路径并沿着它移动的问题
这两个其中任何一个都可能会耗费你很大的努力。一方面,带有复杂的搜索算法的pathfinder会在物体移动时只关注搜寻全局路径并让物体顺着这条路径走下去;另一方面,movement不会寻找路径,而是考虑周围的情况,一次只前进一步。只有结合这两个方面我们才能得到最好的结果。
A*算法是pathfinding中最受欢迎的选择,因为它相当灵活同时应用非常广泛。
Dijkstra与Greedy Best-First-Search 对比
- Dijkstra选择的是离起点最近的节点
- Greedy选择的是离重点最近的节点(用到了启发式函数heuristic)它不能保证找到最短路径,但却比Dijkstra运行速度要快很多。
- 当有障碍的时候,Dijkstra可以保证运行结果的质量,而Greedy则难以保证了。
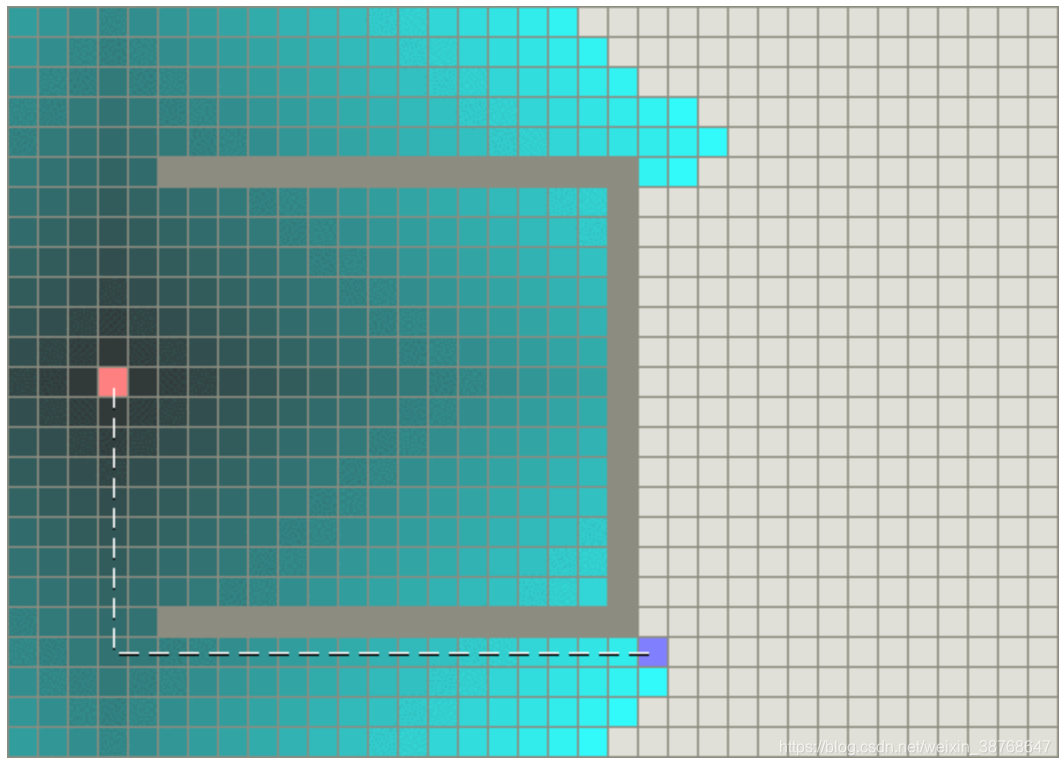
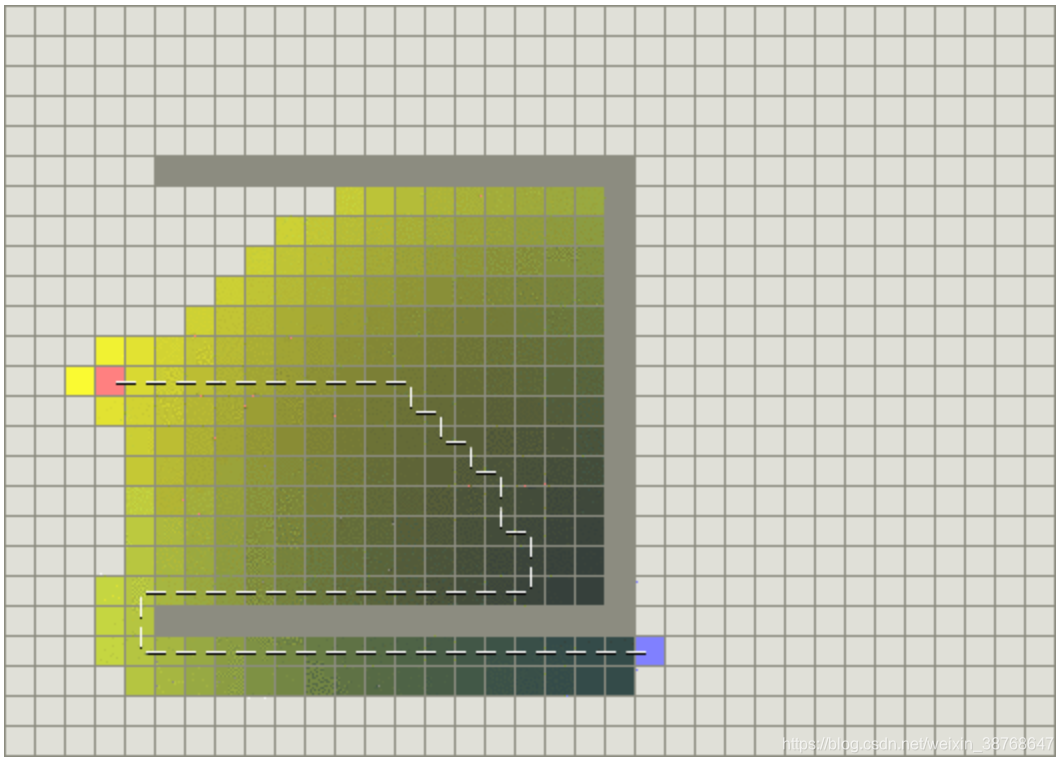
Dijkstra与GBFS相结合
这就是A算法的好处:既考虑目前已有的消耗,又考虑未来的消耗;保证运行效果的同时有提升了运行速度。
比较特别的一点在于:启发式算法通常只是给你一个估计性的解决方案,无法保证最优。而A是基于启发式算法创建的,虽然启发式算法本身无法保证结果的最优化,但A*算法却可以保证。
A*算法
A*算法的术语中
g(n)是从起点到任意节点n的确切costh(n)是从任意节点n到目标的估计cost
A*在两者之间找一个平衡f(n) = g(n) + h(n):
每次进入主循环之后,A*会寻找具有最小f(n)的节点
A*算法对于启发式函数(Heuristic)的使用
A*算法的启发式函数
用来控制A*的行为:
- 一个极端,如果
h(n)是0, 那么只有g(n)在起作用,A*就变成了Dijkstra算法,保证寻找最短路径 - 如果
h(n)总是小于或等于从节点n到终点的耗费,那么A可以保证找到最短路径。h(n)越低,A就会越多的探索节点,同时运行速度也就会越慢。 - 如果
h(n)恰巧等于从n到目标的耗费,那么A只会沿着最优路径,不会探索任何其他节点,运行速度就会变得非常快。虽然你不可能在任何情况下都保证这一点,但从这一点你可以知道,在完美的条件下,A算法的运行效果也是非常完美的。 - 如果
h(n)有时比从n到目标的耗费大,那么A*则不能保证找到最短路径,但这样会具有较快的运行速度。 - 在另一个极端,如果
h(n)和g(n)高度相关,A*算法则会变成GBFS
也就是说,我们可以决定我们想要A*帮我们做什么:在完全精确的情况下,我们可以在非常短的时间内找到最短路径。如果heuristic太低,我们也可以找到最短路径,但运算效率会降低;如果heuristic太高,那么运算效率会提升,但意味着我们需要放弃最短路径。
(对于游戏设计,A*会非常有用:在某些情况下你会想要找到一条好的路径而不是最好的路径。通过调整g(n)和h(n)之间的平衡,我们可以适应各种需求)
速度还是准确度
需要在两者之间找到平衡
在游戏中,有时不需要找到最佳,而是找到一个与最佳相近的路径即可。如果使用一个永远保证不大于实际cost的函数意味着有时会过低的估计cost。
假设游戏中有两种类型的区域,平底和山地,平地的cost为1,山地的cost为3。同样的cost,A*在平地搜索距离是在山地搜索距离的三倍。这是因为有可能有一条路出现在平地上,而山被这平地所环绕。你可以通过把两种地形之间的差距heuristic设为1.5来加速A*搜索,使A比较3和1.5,这会比让A*比较3和1要好很多。同时它也满足山地,所以不会花太多时间去找路。或者,你也可以通过减少对山路的搜索来加速A*——告诉A搜索山路的cost是2而非3。两种方法都舍弃了最优解以求得速度。
单位
A*计算f(n) = g(n) + h(n),为了两值相加,
这些值需要在同一单位上(归一化)。如果如果g(n)估计的是小时而h(n)估计的是米,那么A*会认为二者其中之一太大或太小,要么得不到好的结果,要么运算速度就会大大降低。
精确的启发式函数
如果你的启发式函数恰巧等于你的最优路径,那么你会看到A*的搜索路径只会向外扩张少数的几个节点。事实上A*内部在每一个节点都会计算f(n) = g(n) + h(n)。如果g(n)和h(n)恰巧相等,那么所有不在正确路径的点的f值都会高于正确路径上点的f值。既然A*已经考虑了具有更低值的节点,那么它就不会考虑那些值相对高的节点,也就不会多走弯路。
预先计算精确的启发式函数
精确计算启发式函数的一个方法是预先计算出每两点之间的最短路径长度。但这在大多数游戏中几乎是不可能的。然而,有些方法可以帮助估计这一heuristic。
- 在细网格上面建立粗网格。预先计算两个粗网格点之间的距离。
- 预先计算航基准点之间的距离。这是粗网格方法的泛化方法。
然后加入h'来估计从任何地点走到近邻基准点的距离。后者如果可以的话也可以预先计算出来。这样最后的启发式函数就变成:
h(n) = h'(n,w1) +distance(w1,w2) + h'(w2, goal)
如果你想要一个更好但是会更昂贵的heuristic,需要分析比较所有分别靠近当前节点和目标的基准点。
线性精确启发式函数
在特殊情况下,你可以不需要预结算就能得到精确的启发式函数。如果你有一个无障碍无慢速区域的地图,那么从起始点到终点的最短距离就是一条直线。
如果你是用的是简单的启发式函数(不知到道路上的障碍),它需要匹配精确地启发式函数。如果不是,那么有可能你会在单位量化(scale)或者heuristic类型选择上面遇到问题。
网格地图的启发式函数
在网格上面,有很多有名的启发式函数可供你使用。
使用标准:
- 正方形网格,四方向移动,使用曼哈顿距离( L 1 L_1 L1)
- 正方形网格,八方向移动,使用对角线距离( L ∞ L_\infty L∞)
- 正方形网格,任意方向移动,你可能会想或不会想用欧氏距离( L 2 L_2 L2)。如果A*在寻找网格上路径,而你允许非网格化移动,那么你需要考虑其他方法的地图表示
- 六边形网格,六方向移动,使用适应六边形网格的曼哈顿距离
用每步最小cost乘以步与步之间的距离。比如,如果你以米为单位,距离是三个方格,每个方格边长 15 15 15米,那么heuristic将返回 4 × 15 = 45 4\times15 = 45 4×15=45米。heuristic返回的单位应该与损失函数的单位相同。
曼哈顿距离
标准的方格启发式函数。
function heuristics(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * (dx + dy)
D如何选取:与你损失函数的单位相匹配如果想得到最优路径和一个合理的heuristic,将D设成相邻格之间的最低cost。在不存在障碍、区域移动消耗具有最低消耗D,每向目标移近一步:g += D; h -=D;移近两步,f仍会保持不变。也就意味着启发性函数(heuristic)和消耗函数(cost)相符合。如果放弃最优路线来提升速度,可以通过增加D或者通过减小最低最高边耗费的比率的方法。
对角线距离
如果允许对角线移动,需要不同的heuristic。 ( 4 e a s t , 4 n o r t h ) (4east,4north) (4east,4north),使用曼哈顿距离的话对角移动一格会变成 8 × D 8\times D 8×D。实际上你只需要想northeast移动 4 4 4,所以heuristic应该是 4 × D 2 4\times D_2 4×D2,其中 D 2 D_2 D2时对角移动一格的损耗。
functiong heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * (dx + dy) + (D2 - 2 * D) * min(dx, dy)
在这里我们首先计算如果你不能对角移动所用的步数,然后减去你用对角线移动节省下的步数。如果对角线移动,首先你会移动min(dx,dy)步对角线,每步消耗
D
2
D_2
D2,同时这省掉了你
2
×
D
2\times D
2×D的非对角线距离。(译者注:这里对角线移动指的是每个小方格的角对角移动,不适用于小方格的组合。例如,我们无法从(0,0)点直接对角移动到(3,1),需要对角移动到(1,1),然后再直线移动到(3,1))
当
D
=
1
D = 1
D=1 且
D
2
=
2
D_2 = 2
D2=2时,对角线距离叫做 切比雪夫距离。当
D
=
1
D = 1
D=1 且
D
2
=
2
D_2 = \sqrt2
D2=2时,对角线距离叫做Octile距离。
其他写法:
# 先算最长边直线距离,然后用短边直线距离减去对角线距离
D * max(dx, dy) + (D2 - D) * min(dx,dy)`
# 先算需要走的直线距离,加上对角线距离
if(dx > dy) (D * (dx - dy) + D2 * dy) else (D * (dy - dx) + D2 * dx)
欧氏距离
如果物体可以任意角度移动,而非只是按网格移动的话。那么你需要使用直线距离。
function heuristic(node) =
dx = abs(node.x - goal.y)
dy = abs(node.y - goal.y)
return D * sqrt(dx * dx + dy * dy)
然而在这种情况下,如果直接使用A*有可能会遇到问题,因为损失函数g和启发式函数h不等。因为欧氏距离比曼哈顿或者对角线距离都要短,你可以得到最优路径,但A*运行时间会变长。
不开方的欧氏距离
有些人建议使用距离的平方避免昂贵的开放计算。
==!!不要这样做!!==这样会导致尺度问题(scale problem)。g和h之间的尺度需要匹配,因为你把它们相加来组成f。当计算f的时候,距离的平方会比g要大很多,因此你会扩大h的值。如果距离非常长,最终结果就是g(n)占比很小无法影响f,A*最终降为贪婪最佳优先搜索。
如果你觉得开放耗费太大的话,要么用快速平方根估计欧氏距离,要么用对角线距离估计欧氏距离。
多个目标
如果你想搜索几个目标的其中之一,那么你需要建立一个heuristich'(x) = min(h1(x), h2(x),h3(x),...),其中h1(x), h2(x),h3(x),...是任意目标到当前点的heuristic。
一种解决方法是,我们可以使用增加一个新目标节点,然后将它和原来的每个目标之间连接一条cost为0的边。到达新目标节点的路径毕竟会经过其中一个原来的目标节点。
如果你想找到到达所有目标的路径,你的最优选择是Dijkstra算法。
切断联系
在一些网格地图中有很多路具有相同的距离。比如,在平面没有变化的区域,使用网格会导致许多相等的路径。A*会找到所以具有相同f值的路径,而不是只找到一个就截止了。
解决这一问题的快速方法是调整g或者h的值。切断联系需要有确定的顶点(比如不能是个随机数值),需要使f值不同。既然A*的搜索依靠f值,使他们不同意味着只有其中一个f值会被搜索到。
切断联系的方法之一,是稍稍改变一下h的单位级(scale)。如果我们向下减,随着我们向目标移动,f值会增加。不幸的是,这意味着A*更愿意搜索起点周围的点。因此我们可以稍微增加h的值(即使是
0.1
0.1%
0.1)。A*会更愿意在目标点周围扩散搜索。heuristic *= (1.0 + p)
因子p应该选择那些满足p < (minimum cost of taking one step) / (expected maximum path length)假设路径不大于
1000
1000
1000,你可以选择
p
=
1
/
1000
p = 1/1000
p=1/1000。(注意这其实有点打破heuristic的合理性,但在游戏中其实并不重要)这种做法的结果是A*探索的节点要比之前少很多(也就是提升了速度)。
当存在障碍的情况下,A*仍需要努力找到一条路绕过障碍,但绕过障碍后,A*探索的节点又会变为很少。
Steven van Dijk介绍说一种更直接的方法是把h值传递到一个比较函数。当f相等时,比较函数会通过比较h值来打破联系。

















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









