










吴恩达机器学习 Chapter5 多元线性回归(Linear Regression with multiple variables)
Multiple variables => Multiple features
hypothesis
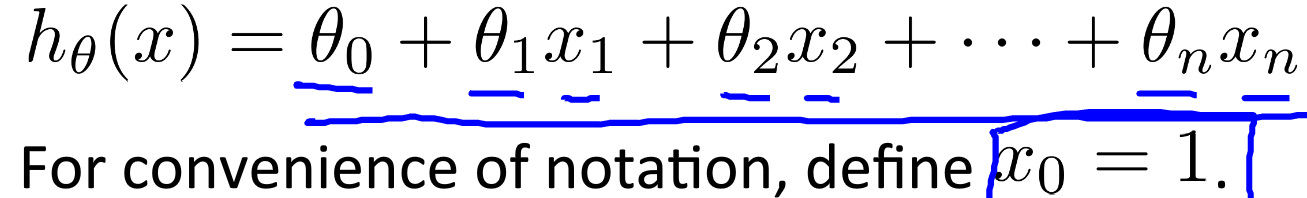
Vectorize
h
θ
(
x
)
=
θ
T
x
h_\theta(x) = \theta^Tx
hθ(x)=θTx
x
∈
R
n
+
1
,
θ
∈
R
n
+
1
x\in R^{n+1}, \theta \in R^{n+1}
x∈Rn+1,θ∈Rn+1
Cost function
Cost function remains the same. The parameters are vectorized.

New algorithm

NOTE: Still, the parameters should be updated simultaneously.
Gradient Descent Practice
Feature Scaling
Idea
Get every feature into approximately a − 1 ≤ x ≤ 1 -1\leq x \leq 1 −1≤x≤1 range. To make sure that the function will converge quickly.
Mean normalization
x
i
=
>
x
−
μ
i
s
i
x_i => \frac{x - \mu_i}{s_i}
xi=>six−μi
μ
i
\mu_i
μi: the mean of the feature
i
i
i
s
i
s_i
si : the range of the feature
i
i
i (
m
a
x
−
m
i
n
max - min
max−min) or standard deviation
NOTE: Do not apply to x 0 = 1 x_0=1 x0=1!
Learning Rate
Debugging
To make sure gradient descent is working correctly.
Ploting
J
(
θ
)
J(\theta)
J(θ):
- To debugging:
J
(
θ
)
J(\theta)
J(θ) should decrease after every iteration.
If gradient descent not work like this:

Try to use smaller α \alpha α - To judge whether convergengce: Declare convergence when J ( θ ) J(\theta) J(θ) decrease by less than 1 0 − 3 10^{-3} 10−3 in one iteration.
Summary: Not too big nor too small
- If too small: Slow to converge
- If too big: J ( θ ) J(\theta) J(θ) may not decrease every iteration; may not converge.
- To try α \alpha α: try …0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, …
Another solution: Normal equation
A method to solve for
θ
\theta
θ analytically.
Not work for complex algorithm.
Intuition
To get the minimum, set
∂
J
(
θ
)
∂
θ
j
=
0
\frac{\partial J(\theta)}{\partial \theta_j} = 0
∂θj∂J(θ)=0 for every
j
j
j
θ
=
(
X
T
X
)
−
1
X
T
y
\theta = (X^TX)^{-1}X^Ty
θ=(XTX)−1XTy
Feature scaling is unnecessary.
Advantage and Disadvantage (Compared to GD)
m training examples, n features
| Gradient Descent | Normal Equation |
|---|---|
| Need to choose α \alpha α | No need to choose α \alpha α |
| Needs many iterations | One time. No iteration. |
| Works well even when n is large | Need to compute ( X T X ) − 1 (X^TX)^{-1} (XTX)−1 O ( n 3 ) O(n^3) O(n3) slow if n is large |
| If n > 10 , 000 n > 10,000 n>10,000 | If n < 10 , 000 n<10,000 n<10,000 |
Normal equation and non-invertibility
When X T X X^TX XTX is non-invertible?
- Redundant features(linearly dependent)
- Too many features(
m
≤
n
m \leq n
m≤n)
=> Delete some features; or use regularization.















 4135
4135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









