







Prerequisites
Outline
- Section 1: Intro to kNN
- Section 2: Classification with kNN
- Section 3: Hyperparameter Tuning for k k k with T-fold Cross Validation
- Section 4: Regression with kNN
k nearest neighbours (kNN)
The purpose of this notebook is to understand and implement the kNN algorithm. You are not allowed to use any package that has a complete kNN framework implemented (e.g., scikit-learn).
Section 1: Intro to kNN ^
The kNN algorithm can be used both for classification and regression. Broadly speaking, it starts with calculating the distance of a given point x x x to all other points in the data set. Then, it finds the k nearest points closest to x x x, and assigns the new point x x x to the majority class of the k nearest points (classification). So, for example, if two of the k=3 closest points to x x x were red while one is blue, x x x would be classified as red.
On the other hand in regression, we see the labels as continuous variables and assign the label of a data point x x x as the mean of the labels of its k nearest neighbours.
import numpy as np
from sklearn.datasets import make_classification, fetch_california_housing
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
Important things first: You already know that the kNN algorithm is based on computing distances between data points. So, let’s start with defining a function that computes such a distance. For simplicity, we will only work with Euclidean distances in this notebook, but other distances can be chosen interchangably, of course.
Implement in the following cell the Euclidean distance
d
d
d, defined as
d
(
p
,
q
)
=
∑
i
=
1
D
(
q
i
−
p
i
)
2
,
d(\boldsymbol p, \boldsymbol q) = \sqrt{\sum_{i=1}^D{(q_i-p_i)^2}} \, ,
d(p,q)=i=1∑D(qi−pi)2,
where
p
\boldsymbol p
p and
q
\boldsymbol q
q are the two points in our
D
D
D-dimensional Euclidean space.
## EDIT THIS FUNCTION
def euclidean_distance(p, q):
return np.sqrt(np.sum((p-q)**2, axis=1)) ## <-- SOLUTION
Section 2: Classification with kNN ^
We start with using kNN for classification tasks, and create a dataset with sklearn’s make_classification function and standardise the data.
X_class, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, n_clusters_per_class=1, n_classes=3, random_state=15)
## EDIT THIS FUNCTION
def standardise(X):
mu = np.mean(X, 0)
sigma = np.std(X, 0)
X_std = (X - mu) / sigma ## <-- SOLUTION
return X_std
X = standardise(X_class)
As with any other supervised machine learning method, we create a training and test set to learn and evaluate our model, respectively.
# shuffling the rows in X and y
p = np.random.permutation(len(y))
X = X[p]
y = y[p]
# we split train to test as 70:30
split_rate = 0.7
X_train, X_test = np.split(X, [int(split_rate*(X.shape[0]))])
y_train, y_test = np.split(y, [int(split_rate*(y.shape[0]))])
We visualise the data set with points in the training set being fully coloured and points in the test being half-transparent.
# define colormaps
cm = plt.cm.RdBu
cm_bright = ListedColormap(['blue', 'red', 'green'])
# visual exploration
plt.figure(figsize=(12,8))
plt.xlabel(r'$X^{(1)}$', size=24)
plt.ylabel(r'$X^{(2)}$', size=24)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.25)
plt.show()
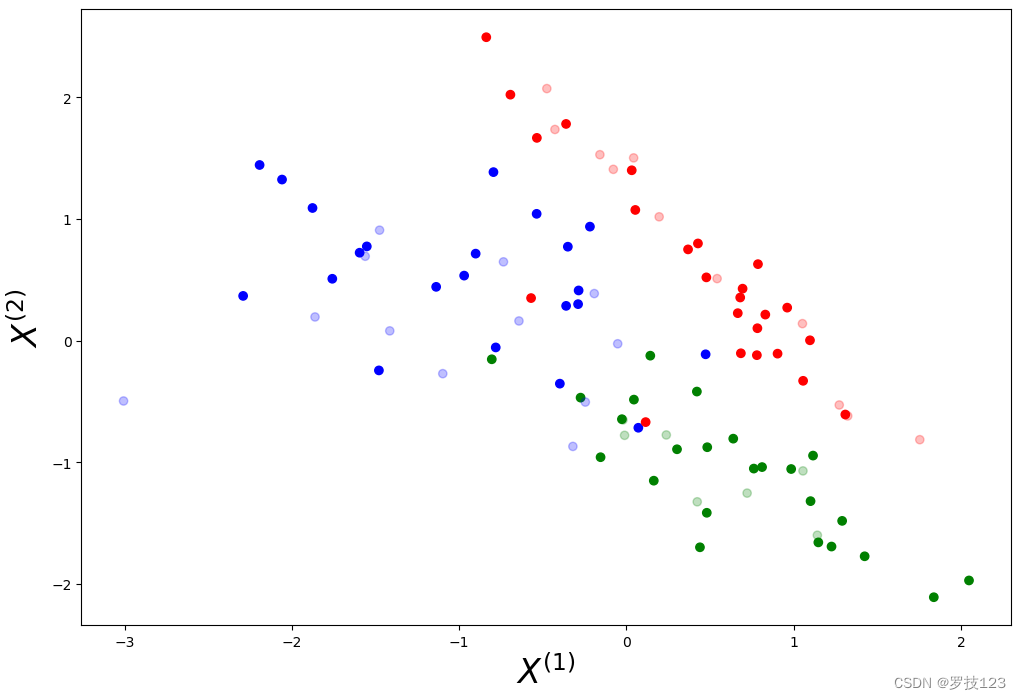
We try to find the k nearest neighbours in our training set for every test data point. The majority of labels of the k closest training points determines the label of the test point.
## EDIT THIS FUNCTION
def k_neighbours(X_train, X_test, k=5, return_distance=False):
n_neighbours = k
dist = []
neigh_ind = []
# compute distance from each point x_test in X_test to all points in X_train (hint: use python's list comprehension)
point_dist = [euclidean_distance(x_test, X_train) for x_test in X_test] ## <-- SOLUTION
# determine which k training points are closest to each test point
for row in point_dist:
enum_neigh = enumerate(row)
sorted_neigh = sorted(enum_neigh, key=lambda x: x[1])[:k]
ind_list = [tup[0] for tup in sorted_neigh]
dist_list = [tup[1] for tup in sorted_neigh]
dist.append(dist_list)
neigh_ind.append(ind_list)
# return distances together with indices of k nearest neighbours
if return_distance:
return np.array(dist), np.array(neigh_ind)
return np.array(neigh_ind)
Once we know which k neighbours are closest to our test points, we can predict the labels of these test points.
We implement this in a “pythonic” way and call the previous function k_neighbours within the next function predict.
Our predict function determines how any point
x
test
x_\text{test}
xtest in the test set is classified. Here, we only consider the case where each of the k neighbours contributes equally to the classification of
x
test
x_\text{test}
xtest.
## EDIT THIS FUNCTION
def predict(X_train, y_train, X_test, k=5):
# each of the k neighbours contributes equally to the classification of any data point in X_test
neighbours = k_neighbours(X_train, X_test, k=k)
# count number of occurences of label with np.bincount and choose the label that has most with np.argmax (hint: use python's list comprehension)
y_pred = np.array([np.argmax(np.bincount(y_train[neighbour])) for neighbour in neighbours]) ## <-- SOLUTION
return y_pred
To evaluate the algorithm in a more principled way, we need to implement a function that computes the mean accuracy by counting how many of the test points have been classified correctly and dividing this number by the total number of data points in our test set.
Again, we do this is in a pythonic way and call the previous predict function within the next function score.
## EDIT THIS FUNCTION
def score(X_train, y_train, X_test, y_test, k=5):
y_pred = predict(X_train, y_train, X_test, k=k) ## <-- SOLUTION
return np.float(sum(y_pred==y_test))/ float(len(y_test))
It is quite common to print both the training and test set accuracies.
k = 8
print('Training set mean accuracy:', score(X_train, y_train, X_train, y_train, k=k))
print('Test set mean accuracy:', score(X_train, y_train, X_test, y_test, k=k))
Training set mean accuracy: 0.8714285714285714
Test set mean accuracy: 0.9666666666666667
<ipython-input-10-1ef50d68801b>:4: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.float(sum(y_pred==y_test))/ float(len(y_test))
Questions
- Does the solution above look reasonable?
- Play around with different values for k. How does it influence the classification mean accuracy?
- Compare the training and test set accuracy. Is there a difference? If so, what does the difference tell you?
- Choose different ratios for the split between training and test set, and re-run the entire algorithm. What can you learn from different ratios?
- Considering an accuracy estimate on a test-split wich contains 30% of the dataset examples is 0.86, do we guarantee to obtain the same accuracy estimate when we apply our model on infinetely large unseen test examples, i.e. does the accuracy of your model on the test-split generalize well on unseen data? From this week’s lecture notes, what would you suggest to improve our confidence in the accuracy estimate, so it is more closer estimate to the true accuracy when testing on unseen examples?
3 Hyperparameter Tuning for k k k with T-fold Cross ^
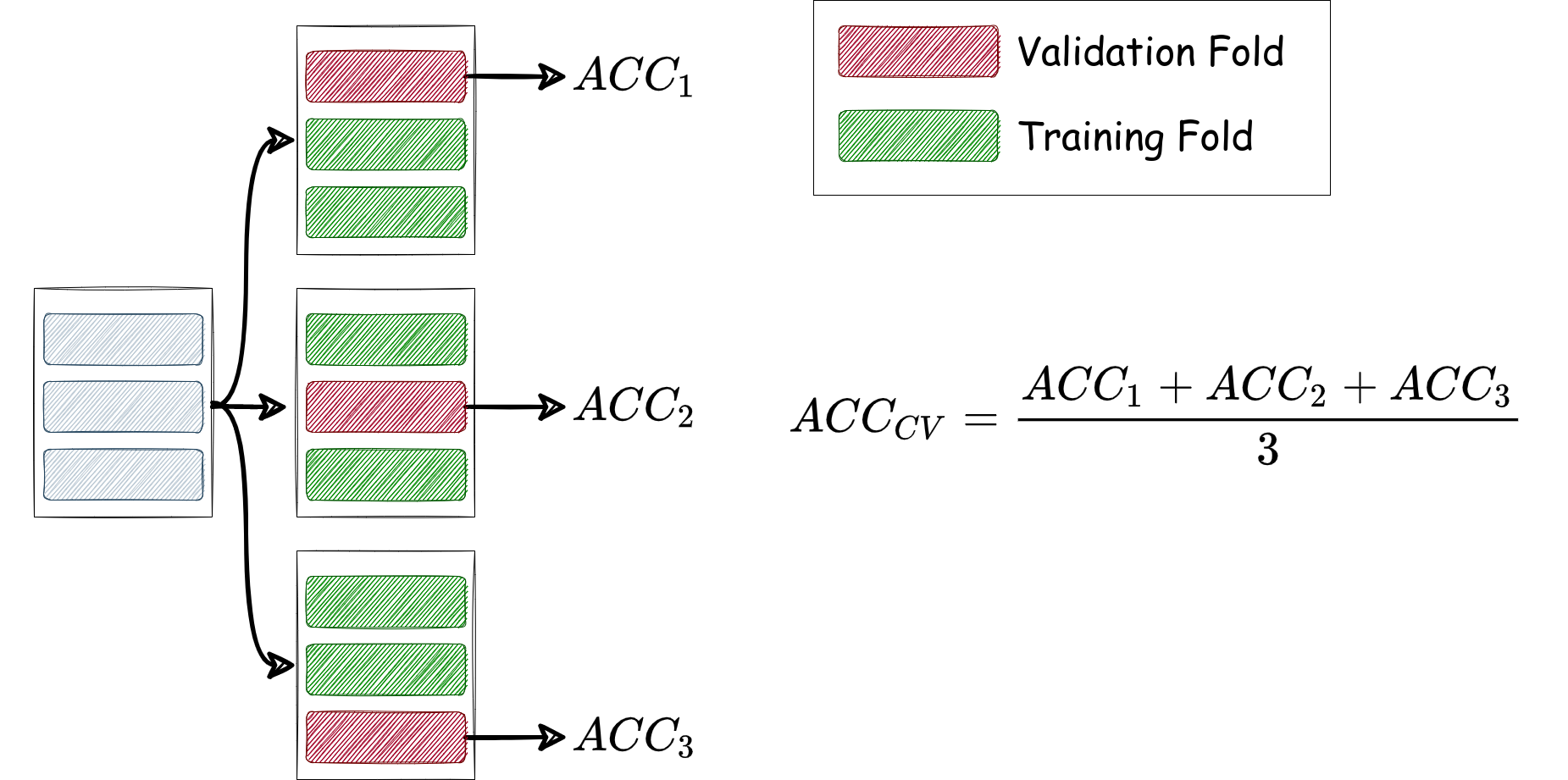
Let’s consider a systematic way to help select the best k k k (i.e. the hyperparameter of k k k-NN). In previous cells, we splitted our data into 70%:30% for training:test examples. Now we need to choose the best k k k, but without looking at the accuracy on the test set (which should be used at the end to assess the predictive power of the model with the chosen k k k). To this end, we perform T T T-fold cross validation, where, importantly, we don’t evaluate the accuracy of the model using the same examples on which we trained our model, rather on a held out validation set. We can achieve this by running T T T experiments, and in each one we use disjoint partitions for the training and accuracy examples. By averaging the accuracy estimates over the T T T experiments, we get a more precise and reliable accuracy estimate than before. If we consider T = 3 T=3 T=3 folds, then we can run the three experiments and evaluate the average accuracy as in the figure below:
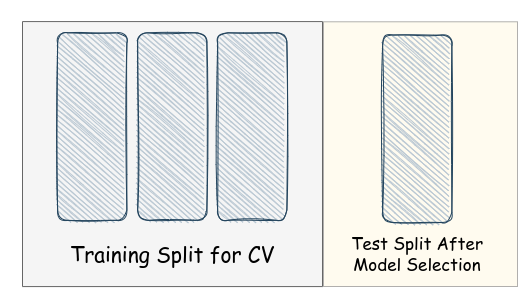
Finaly, we need to isolate a separate set, before using cross-validation for hyperparameter tuning, to test our model after selecting the best performing k k k for k k k-NN, so we further consider the following partitioning, which we will need to adhere with throughout the future notebooks and courseworks (i.e. in the problems when we need to use cross-validation for hyperparameter tuning then test on completely unseen data that are not involved in hyperparamter tuning):
Let’s consider a ratio 80:20 for training and test splits
# shuffling the rows in X and y
p = np.random.permutation(len(y))
X = X[p]
y = y[p]
# we split train to test as 80:20
split_rate = 0.8
X_train, X_test = np.split(X, [int(split_rate*(X.shape[0]))])
y_train, y_test = np.split(y, [int(split_rate*(y.shape[0]))])
Now let’s partition our training split into 5-folds. We could store the corresponding indices only:
# Now we have a list of five index arrays, each correspond to one of the five folds.
folds_indexes = np.split(np.arange(len(y_train)), 5)
folds_indexes
[array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]),
array([16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]),
array([32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]),
array([48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63]),
array([64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79])]
Let’s implement a function that evalutes the accuracy of model with a given k k k by running T T T experiments and returning the average evaluated accuracy.
# EDIT THIS FUNCTION
def cross_validation_score(X_train, y_train, folds, k):
scores = []
for i in range(len(folds)):
val_indexes = folds[i]
train_indexes = list(set(range(y_train.shape[0])) - set(val_indexes))
X_train_i = X_train[train_indexes, :]
y_train_i = y_train[train_indexes]
X_val_i = X_train[val_indexes, :] # <- SOLUTION
y_val_i = y_train[val_indexes] # <- SOLUTION
score_i = score(X_train_i, y_train_i, X_val_i, y_val_i, k=k) # <- SOLUTION
scores.append(score_i)
# Return the average score
return sum(scores) / len(scores) # <- SOLUTION
Let’s scan a range of k k k in [ 1 , 30 ] [1, 30] [1,30] and select the one with the best cross-validation accuracy.
def choose_best_k(X_train, y_train, folds, k_range):
k_scores = np.zeros((len(k_range),))
for i, k in enumerate(k_range):
k_scores[i] = cross_validation_score(X_train, y_train, folds, k)
print(f'CV_ACC@k={k}: {k_scores[i]:.3f}')
best_k_index = np.argmax(k_scores)
return k_range[best_k_index]
best_k = choose_best_k(X_train, y_train, folds_indexes, np.arange(1, 31))
print('best_k:', best_k)
<ipython-input-10-1ef50d68801b>:4: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.float(sum(y_pred==y_test))/ float(len(y_test))
CV_ACC@k=1: 0.762
CV_ACC@k=2: 0.787
CV_ACC@k=3: 0.825
CV_ACC@k=4: 0.825
CV_ACC@k=5: 0.812
CV_ACC@k=6: 0.825
CV_ACC@k=7: 0.825
CV_ACC@k=8: 0.875
CV_ACC@k=9: 0.838
CV_ACC@k=10: 0.875
CV_ACC@k=11: 0.863
CV_ACC@k=12: 0.863
CV_ACC@k=13: 0.850
CV_ACC@k=14: 0.863
CV_ACC@k=15: 0.838
CV_ACC@k=16: 0.838
CV_ACC@k=17: 0.838
CV_ACC@k=18: 0.787
CV_ACC@k=19: 0.800
CV_ACC@k=20: 0.812
CV_ACC@k=21: 0.812
CV_ACC@k=22: 0.787
CV_ACC@k=23: 0.812
CV_ACC@k=24: 0.800
CV_ACC@k=25: 0.775
CV_ACC@k=26: 0.762
CV_ACC@k=27: 0.787
CV_ACC@k=28: 0.750
CV_ACC@k=29: 0.750
CV_ACC@k=30: 0.762
best_k: 8
Finally, let’s evaluate the accuracy with the best k on on the unseen part, the test-split that we isolated earlier.
score(X_train, y_train, X_test, y_test, k=best_k)
<ipython-input-10-1ef50d68801b>:4: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
return np.float(sum(y_pred==y_test))/ float(len(y_test))
1.0
Section 4: Regression with kNN ^
The kNN algorithm is mostly used for classification, but we can also utilise it for (non-linear) regression. Here, we calculate the label of every point in the test set as the mean of the k nearest neighbours.
We start with defining a training set with sklearn’s California housing data set. Note that this data set has normally 8 features, but we only extract the first feature, which corresponds to the median income in the district. The label is the median house value in the district.
data = fetch_california_housing(return_X_y=True)
X = data[0][:,0].reshape((-1, 1))
y = data[1]
X_std = standardise(X)
As before, we first divide the data into training and test set:
# shuffling the rows in X and y
p = np.random.permutation(len(y))
X = X_std[p]
y = y[p]
# we split train to test as 70:30
split_rate = 0.7
X_train, X_test = np.split(X, [int(split_rate*(X.shape[0]))])
y_train, y_test = np.split(y, [int(split_rate*(y.shape[0]))])
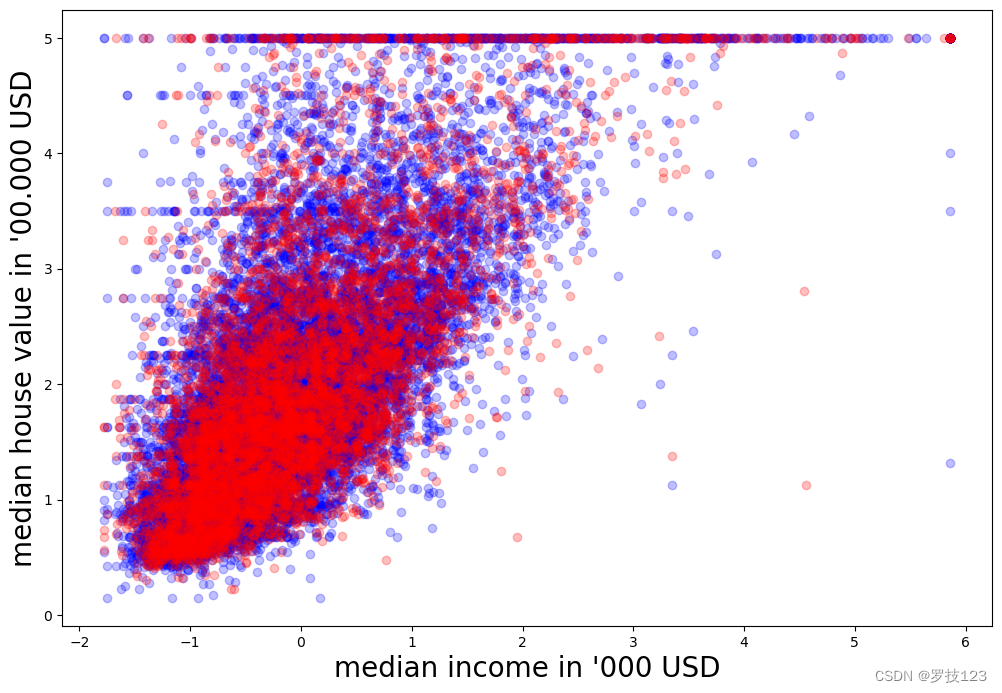
Let’s plot it to get a sense how we can proceed. This time, we plot training examples in blue and test examples in red.
# visual exploration
plt.figure(figsize=(12,8))
plt.xlabel(r"median income in '000 USD", size=20)
plt.ylabel(r"median house value in '00.000 USD", size=20)
plt.scatter(X_train, y_train, c='blue', alpha=0.25)
plt.scatter(X_test, y_test, c='red', alpha=0.25)
plt.show()
As before, we need to define a predicting function which we call reg_predict.
## EDIT THIS FUNCTION
def reg_predict(X_train, y_train, X_test, k=20):
# each of the k neighbours contributes equally to the classification of any data point in X_test
neighbours = k_neighbours(X_train, X_test, k=k)
# compute mean over neighbours labels (hint: use python's list comprehension)
y_pred = np.array([np.mean(y_train[neighbour]) for neighbour in neighbours]) ## <-- SOLUTION
return y_pred
# computing predictions... (takes a few minutes due to the high sample size)
k = 20
y_pred = reg_predict(X_train, y_train, X_test, k=k)
# ... and plotting them
plt.figure(figsize=(12,8))
plt.xlabel(r"median income (standardised)", size=20)
plt.ylabel(r"median house value in '00.000 USD", size=20)
#plt.scatter(X_train, y_train, c='blue', alpha=0.25)
plt.scatter(X_test, y_test, c='red', alpha=0.25)
plt.scatter(X_test, y_pred, c='yellow', alpha=0.25)
plt.show()
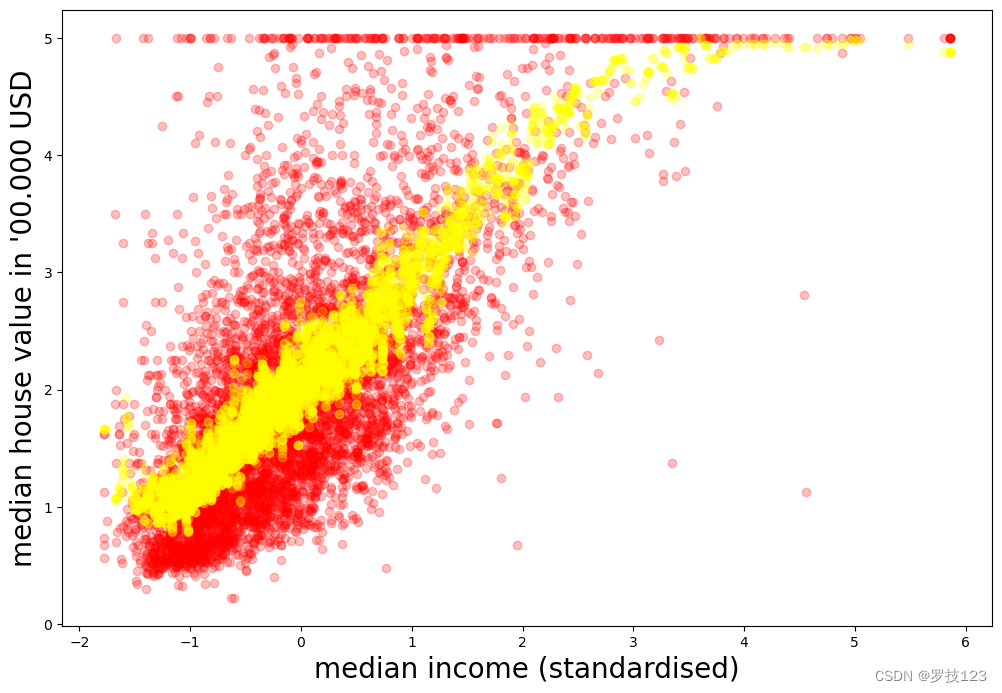
To determine how well the prediction was, let us determine the
R
2
R^2
R2 score. The labels of the test set will be called
y
y
y and the predictions on the test data
y
^
\hat{y}
y^.
R
2
(
y
,
y
^
)
=
1
−
∑
i
=
1
n
(
y
i
−
y
^
i
)
2
∑
i
=
1
n
(
y
i
−
y
ˉ
)
2
,
R^2(y, \hat{y}) = 1 - \frac{\sum_{i=1}^n (y_i - \hat{y}_i)^2}{\sum_{i=1}^n (y_i - \bar{y})^2} \, ,
R2(y,y^)=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2,
where
y
ˉ
=
1
n
∑
i
=
1
n
y
i
\bar{y} = \frac{1}{n} \sum_{i=1}^n y_i
yˉ=n1∑i=1nyi.
## EDIT THIS FUNCTION
def r2_score(y_test, y_pred):
numerator = np.sum((y_test - y_pred)**2) ## <-- SOLUTION
y_avg = np.mean(y_test) ## <-- SOLUTION
denominator = np.sum((y_test - y_avg)**2) ## <-- SOLUTION
return 1 - numerator/denominator
print(r'R2 score:', r2_score(y_test, y_pred))
R2 score: 0.44745758748846054
Questions
- Does the solution above look reasonable? What does your R 2 R^2 R2 value tell you?
- Play around with different values for k. How does it influence the regression?
- Like we did in classification, excercise with implementing cross-validation to find the best performing k on the regression task.
- Compare the training and test set accuracy. Is there a difference? If so, what does the difference tell you?
- Choose different ratios for the split between training and test set, and re-run the entire algorithm. What can you learn from different ratios?
- Can you replicate your results using sklearn?
- Based on sklearn’s documentation, can you see any differences in the algorithms that are implemented in sklearn?















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









