







一、概念理解
SAP目前有三种损耗率的说法,他们代表的含义分别如下:
只有理解的实际业务场景/生产场景中的意义,就可以至少50%理解系统设计,从而更高效率的去测试系统逻辑。
| 类型 | 概念说明 |
| 组件损耗率(Component Scrap) | 指材料自身的损耗,在生产工艺正常的损失范围内。如胶水的挥发,油漆等 |
| 装配报废(Assembly scrap) | 考虑产成品的不合格率,因此生产时会多生产。如果我想要生产出来100件产品,可能需要生产数量为110,这样子最终可用的最终产品就是110,其中10件是在生产过程中报废的 |
| 工序报废 (Operation scrap) | 工序加工成为半成品,FQC不合格报废,导致下道工序接收的数量减少,比如100个半成品经过此道工序后,有99个不合格品 |
问题:在什么样的场景下使用工序报废而不使用装配报废
答复:(官网回答,如下),虽然这个回答我好像暂时也没get到,但相信如果你后面有结合系统逻辑和实施项目的业务场景,会有更深的体验
Before an operation in which high-value components are built into an assembly, a quality inspection of the assembly may take place. Faulty materials that are covered by assembly scrap are taken out of the process before the next operation. This is why you enter an operation scrap instead of a general assembly scrap for high-value components.
The operation scrap is the quantity of one component to be processed in an operation. This value enables you to plan material requirements and determine excess consumption more precisely.
接下来一个个测试对应的损耗率在系统中的逻辑。
其实如果前面三种损耗量的概念如果理解,那基本上都可以理解到系统的逻辑了,不过上层的装配报废导致多出来的需求是可以控制的,通过净值标识字段。我们可以一起看下以下测试结果
二、组件损耗率
有两个地方维护:物料主数据和BOM中
主数据:MRP视图4

BOM:

如果此类原材料都有此类损耗,则可以直接在物料主数据上进行维护,在特定的Bom中损耗率不同可以再进行设置,MRP会优先取BOM主数据中的损耗率。
两个BOM,物料主数据维护组件报废:3%,其中一个BOM中组件报废为5%,一个维护为0%
数据模拟:

这次没有截图系统,直接以模拟给出,如果跟着此篇文章进行测试,就可以按照上面给出的BOM组成,先搭建物料,BOM,和工艺路线。再按照下面维护对应的损耗率数据
成品独立需求,代表我用MD61创建了A的独立需求90,然后运行整理的MPS(这个可以参考设置,运行MPS还是MRP)
运行了MPS/MRP后,就看跑出来的数量B1,B2,B1-C和B2-C的需求数量是不是和我们列出的一样,我们就是按照这个逻辑进行的。
| 料号 | 组件报废 | 成品独立需求 | 运行MRP后需求数量 | |
| 主数据 | BOM | |||
| A | / | / | 90 | 90 |
| B1 | / | 15% | / | 90*2*(1+15%)=207 |
| B2 | / | 15% | / | 90*2(1+15%)=207 |
| B1-C | 3% | 0 | / | 207*0.023(1+3%)=4.905 |
| B2-C | 3% | 5% | / | 207*0.036*(1+5%)=7.825 |
三、装配报废
装配报废只有物料主数据上维护
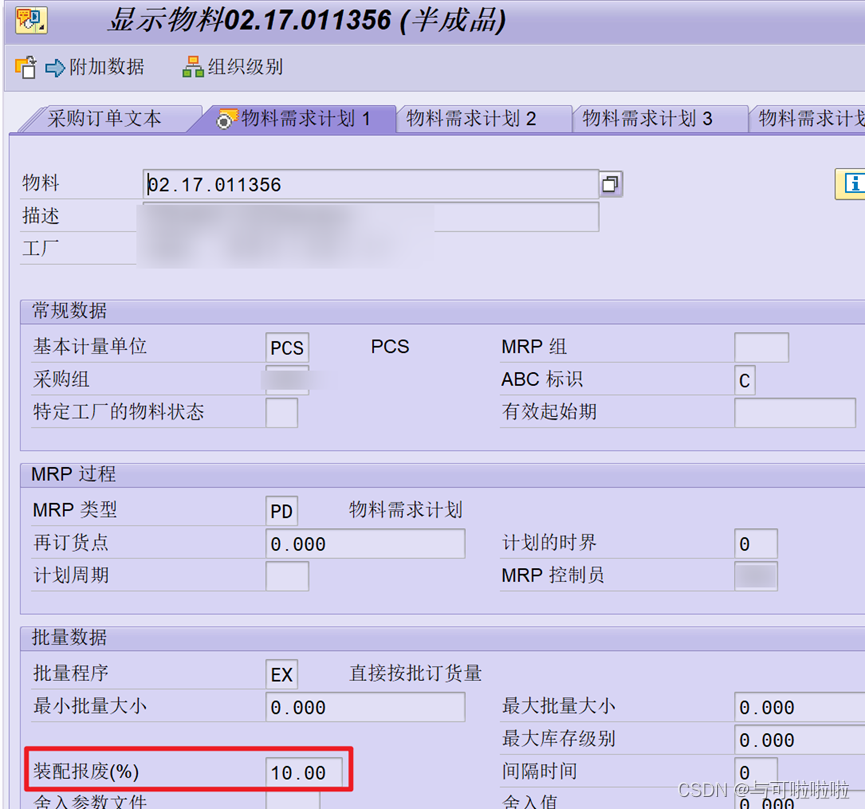
装配报废按照前面的概念理解是在成品层面的报废,因此如果成品需求数量增加,那么自然而然的组件需求数量也增加,如果在此基础上维护了组件损耗率,那么组件本身层面的需求数量又再次增加
数据模拟:

测试思路和前面保持一致,此次变动是在BOM的基础加上了装配报废的数据
| 料号 | 组件报废 | 装配 报废 | 成品独立需求 | 运行MRP后需求数量 | |
| 主数据 | BOM | ||||
| A | / | / | / | 90 | 90 |
| B1 | / | 15% | 10% | / | 90*2*(1+15%)(1+10%)=228 |
| B2 | / | 15% | / | / | 90*2(1+15%)=207 |
| B1-C | 3% | 0 | / | / | 228*0.023*(1+3%)=5.402 |
| B2-C | 3% | 5% | / | / | 207*0.036*(1+5%)=7.825 |
装配报废率维护后是以废品的形式体现
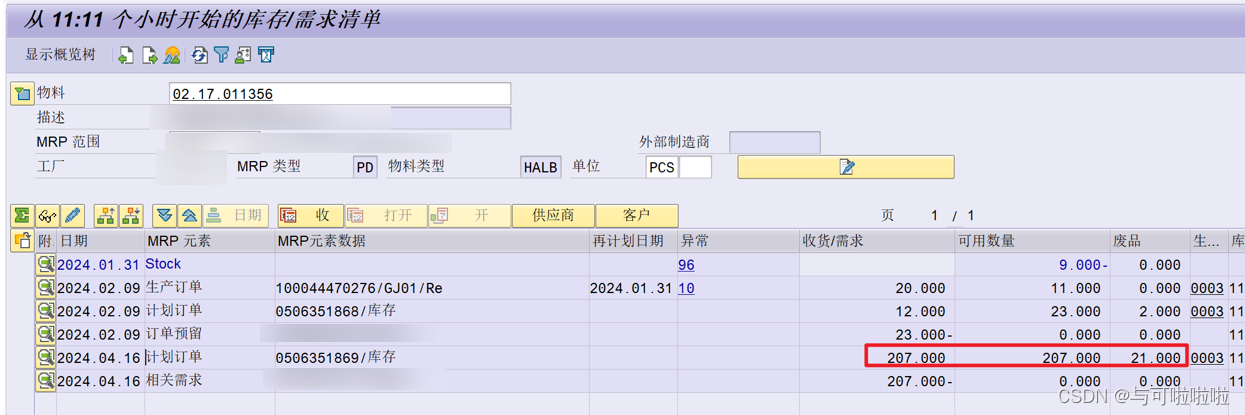

注意:如果BOM中的净值标识勾选了,则下层需求数量不受装配报废的影响。即我们计算组件的需求数量不考虑装配报废。这个测试在工序损耗(BOM)中体现
四、工序损耗
有两个地方维护:BOM和工艺路线工序
BOM中:

工艺路线工序中

由于工艺路线中的报废其实是不影响需求数量的,所以我把它列为了两个测试项
以下测试为了简洁,此次只测试B2和C这一层级,净值标识勾选。红圈圈起来的是此次测试数据

测试一:工序报废针对于原材料C在工艺路线和BOM中都维护了对应的数据。然后维护B2的独立需求,运行MRP,查看C的需求数量
此次测试C的净值标识打勾,可以看到B2(成品)的装配报废所需要的需求数量并没有影响到我们的原材料的需求。
| 料号 | 组件报废 | 装配 报废 | 工序报废 | 净值标识 | 独立需求 | 运行MRP后需求数量 | ||
| 主数据 | BOM | 工艺路线 | BOM | |||||
| B2 | / | 15% | 3% | 1000 | 1000*(1+3%)=1030 | |||
| B2-C | 3% | 5% | / | 6% | 8% | X | / | 1000*0.036*(1+5%)*(1+8%)=40.824 |
测试二“净值标识不勾选,其他数据保持一致。
| 料号 | 组件报废 | 装配 报废 | 工序报废 | 净值标识 | 独立需求 | 运行MRP后需求数量 | ||
| 主数据 | BOM | 工艺路线 | BOM | |||||
| B2 | / | 15% | 3% | 1000 | 1000*(1+3%)=1030 | |||
| B2-C | 3% | 5% | / | 6% | / | 1030*0.036*(1+5%)=38.934 | ||
- 从测试二中可以看到,工序报废只维护了工艺路线中的数据:6%,但是它并没有参与需求数量。
- 测试一和测试二对比,应该比较清晰的看出净值标识的系统逻辑,它影响是否上层的多余需求会不会传递到下层物料中
五、总结
装配报废:成品的损耗,净值标识关系到下层是否考虑装配报废的影响。
组件报废率优先取BOM,其次是物料主数据
工序报废取BOM
拿SAP官方数据解释汇总
成品A:需求数量100件,装配报废2%
下挂半成品/原材料:组件数量100
| B | 情况1 | 情况2 | 情况3 | 情况4 | 情况5 | 情况6 |
| 组件报废率 | 5% | - | 5% | 5% | - | - |
| 工序报废率(BOM) | 6% | 6% | - | - | - | - |
| 净值标识 | X | X | X | - | - | X |
| 计算逻辑 | 10000*(1+5%)*(1+6%) | 10000*(1+6%) | 10000*(1+5%) | 10000*(1+2%)*(1+5%) | 100*(1+2%) | 100*100 |
| 数量 | 11130 | 10600 | 10500 | 10710 | 10200 | 10000 |
以下是损耗率测试中还存在的问题或者需要继续待测试的地方,后续如果有使用或者测试继续补充
- 工序报废(工艺流程)实际上不影响需求数量,但是在上一道工序到下一道工序中,实际的生产数量是减少了的,因此报工的工时和产能都会相应减少,这在系统上是如何体现的待测试
- 我们理解了报废率在需求和供给上的逻辑,那么转为车间生产,废品需要报工吗?如何体现在成本中,系统是如何承载的。(这个是针对于装配报废和工序损耗)















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









