







文章目录
多层索引
此前处理的数据均为单层索引,即熟知的数学矩阵的样式,多层索引即为高维数据的处理
何为多层索引,一个轴上有多层的索引,例如书中所举例子,各个班级作为索引,班级又可分为男女学生
多层索引概述
- 多层索引数据展示
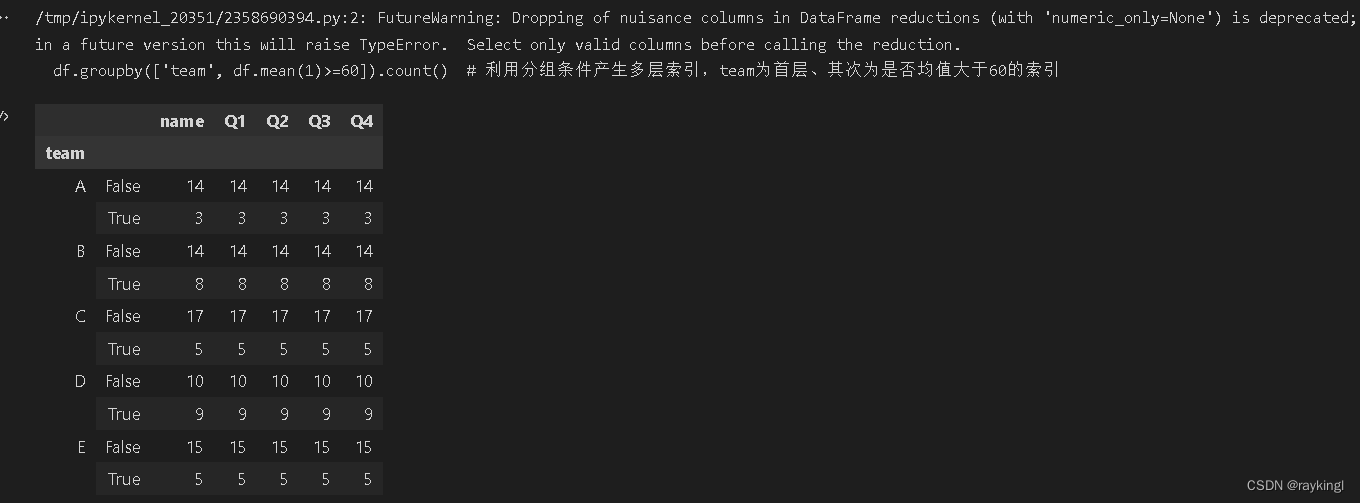
df.groupby(['team', df.mean(1)>=60]).count() # 利用分组条件产生多层索引,team为首层、其次为是否均值大于60的索引
# 出现告警:Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
# 这是由于mean计算的DataFrame中出现了非数值列, 如下优化:
df.groupby(['team', df.select_dtypes('number').mean(1)>=60]).count()
2.列表构建多层索引并使用
arrays = [[1,1,2,2],['A','B','A','B']]
index = pd.MultiIndex.from_arrays(arrays, names=('class', 'team')) # 自定义二层索引
tf = pd.DataFrame([{'Q1':60, 'Q2':70}], index=index)
tf

3.元组构建多层索引并使用
arrays = [[1,1,2,2],['A','B','A','B']]
tuples = list(zip(*arrays))
index = pd.MultiIndex.from_tuples(tuples, names=('class', 'team')) # 自定义二层索引
tf = pd.DataFrame([{'Q1':60, 'Q2':70}], index=index)
tf
- 笛卡尔积构建多层索引
_calss = [1, 2]
team = ['A', 'B']
index = pd.MultiIndex.from_product([_calss, team], names=['class', 'team'])
tf = pd.DataFrame([{'Q1':60, 'Q2':70}], index=index)
tf
5.将DataFrame转换成多层索引
df = pd.DataFrame([['1', 'A'], ['1', 'B'], ['2', 'B'], ['2', 'B']], columns=['class', 'team'])
index = pd.MultiIndex.from_frame(df) #
import numpy as np
pd.Series(np.random.randn(4), index=index)
多层索引操作
多层索引操作和普通索引【单层索引】操作的基本是一致的,下面是一些示例
利用df生成一个多索引数据
mf = df.drop(columns=['name', 'team'])[:10]
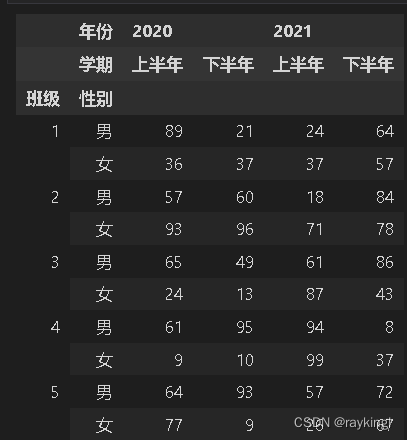
index = pd.MultiIndex.from_product([[i+1 for i in range(5)], ['男',' 女']], names=['班级', '性别']) # 多层行索引
columns = pd.MultiIndex.from_product([['2020', '2021'], ['上半年', '下半年']], names=['年份', '学期']) # 多层列索引
mf.columns = columns
mf.index = index
mf
索引信息查看
mf.index # 行索引
mf.columns # 列索引
mf.index.names # 行索引名称
mf.columns.names # 列索引名称
查看索引的层级及内容
mf.index.levels # 行的层级
mf.index.nlevels # 行的层级数
mf.columns.levels # 列的层级
mf.columns.nlevels # 列的层级数
mf.index.get_level_values(1) # 查看行索引第二层索引的内容
mf.index.get_level_values('班级') # 按索引名称获取索引内容
排序
mf.sort_values('性别')
数据查询
多层索引的数据查询相对单层索引要复杂些,在查询前要确定需求,确定所属的具体层级
# 使用之前的数据
mf = df.drop(columns=['name', 'team'])[:10]
index = pd.MultiIndex.from_product([[i+1 for i in range(5)], ['男',' 女']], names=['班级', '性别']) # 多层行索引
columns = pd.MultiIndex.from_product([['2020', '2021'], ['上半年', '下半年']], names=['年份', '学期']) # 多层列索引
mf.columns = columns
mf.index = index
基本查询
mf.loc[2] # 2班数据
mf.loc[2, '男'] # 2班男生数据
mf['2020'] # 列:2020年数据
mf['2020','上半年'] # 列:2020年上半年数据
mf.loc[2,'男']['2020'] # 2班男生2020年数据
mf.loc[(2,'男'),'2020'] # 同上
条件查询
mf[mf[('2020','上半年')]> 80] # 和单层条件查询一致,仅多了一个索引
# 使用pd.IndexSlice切片索引数据
idx = pd.IndexSlice
mf.loc[idx[[1,2],['男']],idx[['2020'],:]] # 利用idx切片行索引、列索引
# 同理,使用mf.xs()方法,传入索引元组
mf.xs((1,'男')) # 1班男生
mf.xs((1,'男')).xs(('2020','上半年')) # 先行后列筛选
mf.xs('2020', level=0, axis=1) # 利用level指定索引层级,axis指定行或列索引
数据重塑与透视
之前介绍所有内容的都是数据的查看、操作、分组、聚合、多层索引等操作,是对数据的检索和整理。
数据重塑与透视,是数据表达的升华,抓住数据表现之外的所表达的内涵,从数据表达的一个逻辑到另外一个逻辑。
数据透视【pivot】
透视数据的能力,找出(大量复杂无关的)数据的内在关系,将数据转化为有意义、有价值的信息,从而发现其所代表的事务规律和本质。
# 构造例子数据
df = pd.DataFrame({
'A':['a1', 'a1', 'a2', 'a2', 'a3', 'a3'],
'B':['b1', 'b2', 'b3', 'b1', 'b2', 'b3'],
'C':['c1', 'c2', 'c3', 'c4', 'c5', 'c6'],
'D':[1, 2, 3, 4, 5, 6],
})
# 透视A和B列组合对应的数据,C作为值
df.pivot(index='A', columns='B', values=None)
# 聚合透视,aggfun支持单个或多种聚合函数
df.pivot_table(index=['A', 'B'], columns='C', values='D', aggfunc=[sum], fill_value=0, margins=True)
数据堆叠【stack/unstack】
数据的展开和收缩问题
堆叠:将多列数据转为一列的操作,具体为将这些数据列的所有数据表全部旋转到行上
解堆:堆叠的逆过程,将行上的索引旋转到列上
df = pd.DataFrame({
'A':['a1', 'a1', 'a2', 'a2'],
'B':['b1', 'b2', 'b1', 'b2'],
'C':[1, 2, 3, 4],
'D':[5, 6, 7, 8],
'E':[5, 6, 7, 8]
})
df.set_index(['A', 'B'], inplace=True)
s = df.stack() # 堆叠
s.unstack() # 解堆
交叉表 【crosstab】
用于统计分组频率的特殊透视表。将两列或多列中不重复的元素组成新的DataFrame,新数据的行和列交叉部分的值为其组合在原数据中的数量
df = pd.DataFrame({
'A':['a1', 'a1', 'a2', 'a2', 'a1'],
'B':['b2', 'b1', 'b2', 'b2', 'b1'],
'C':[1, 2, 3, 4, 5],
})
pd.crosstab(df['A'], df['B'])
# 分类数据交叉表,这里属实有点不懂了,据说后续章节会介绍......
one = pd.Categorical(['a', 'b'], categories=['a', 'b', 'c'])
two = pd.Categorical(['d', 'e'], categories=['d', 'e', 'f'])
pd.crosstab(one, two)
# 归一化
pd.crosstab(df['A'], df['B'], normalize=True)
#指定聚合方法
pd.crosstab(df['A'], df['B'], values=df['C'], aggfunc=sum)
数据转置【.T】
数据的转置为行变成列,列变成行数据,改变了数据的性质和逻辑
# 转置
df.T
# 轴交换,暂未体会到该函数意义,和df.T重合
df.swapaxes("index", "columns") # 同df.T
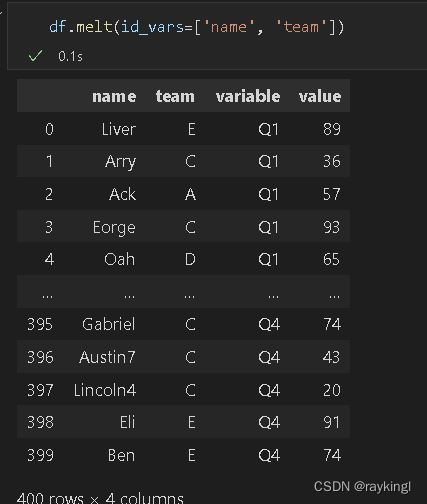
数据融合【melt】
数据融合是数据透视的逆操作[有个没get到],将指定的列铺开【同列属性的列变成一列?】,看个例子
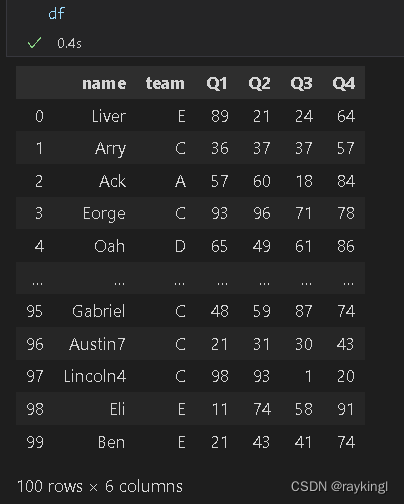
原本df
数据融合后,name和team作为标识
其余的列均作为融合的属性虚拟变量【get_dummies】
虚设变量、名义变量或哑变量,是一个用来反映质的属性的人工变量,是量化了的自变量,通常取值为0或1,被用于one-hot特征提取。
虚变量是将一列或多列的去重值作为新报的列,每列的值由0或1组成:如果原来位置的值与列名相同,则在新表中该位置的值为1,否则为0.
看一个例子
直接传入DataFrame,会将所有非数字列生成虚拟变量
df = pd.DataFrame({'a':list('abcd'),
'b':list('fehg'),
'a1':range(4),
'b1':range(4,8)})
pd.get_dummies(df)
pd.get_dummies(df, columns=['a'])
pd.get_dummies(df.a1, prefix='prefix')
因子化【factorize】
存在大量重复值的一维数据解析成枚举值的过程。【一是数据编码,二是数据】
datas = ['b', 'b', 'a', 'c', 'b']
codes, uniques = pd.factorize(datas)
codes, uniques
codes, uniques = pd.factorize(datas, sort=True) # 排序
codes, uniques = pd.factorize(['b', None, 'a', 'c', 'b']) # 缺失值为-1
cat = pd.Categorical(['a', 'a', 'c'], categories=['a', 'b', 'c']) # 枚举数据因子化
pd.factorize(cat, sort=True)
爆炸列表【explode】
# >爆炸:指将类似列表的每个元素转换为一行,索引值是相同的
## Series爆炸
s = pd.Series([[1, 2, 3], 'foo', [], [3, 4]])
s.explode() # 爆炸列
## DataFrame爆炸
df = pd.DataFrame({"A":[[1, 2, 3], 'foo', [], [3, 4]], "B":range(4)})
df.explode('A') # 爆炸指定列
## 非列表数据的爆炸
df = pd.DataFrame([{"var1":'a,b,c', 'var2':1}, {'var1':'d,e,f', 'var2':2}])
df.assign(var1=df.var1.str.split(',')).explode('var1') # 先转换为列表再爆炸

















 1242
1242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











