







YOLOv8 是 Ultralytics 团队在 YOLOv5 基础上进一步优化的版本,它在模型架构、训练策略、任务扩展和性能效率等方面进行了多项改进。以下是 YOLOv8 相对于 YOLOv5 的主要改进和优化:
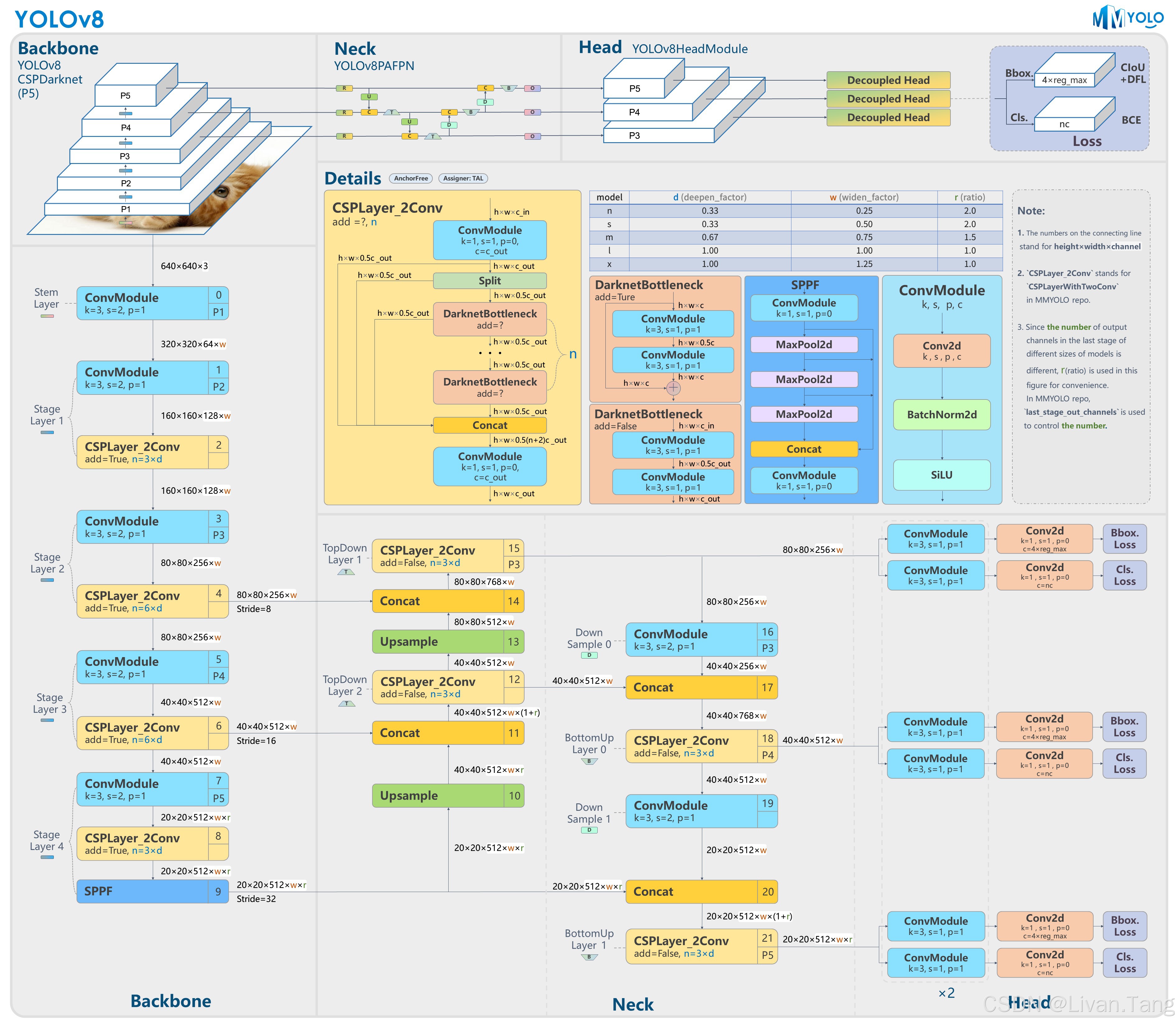
Yolov8网络架构图
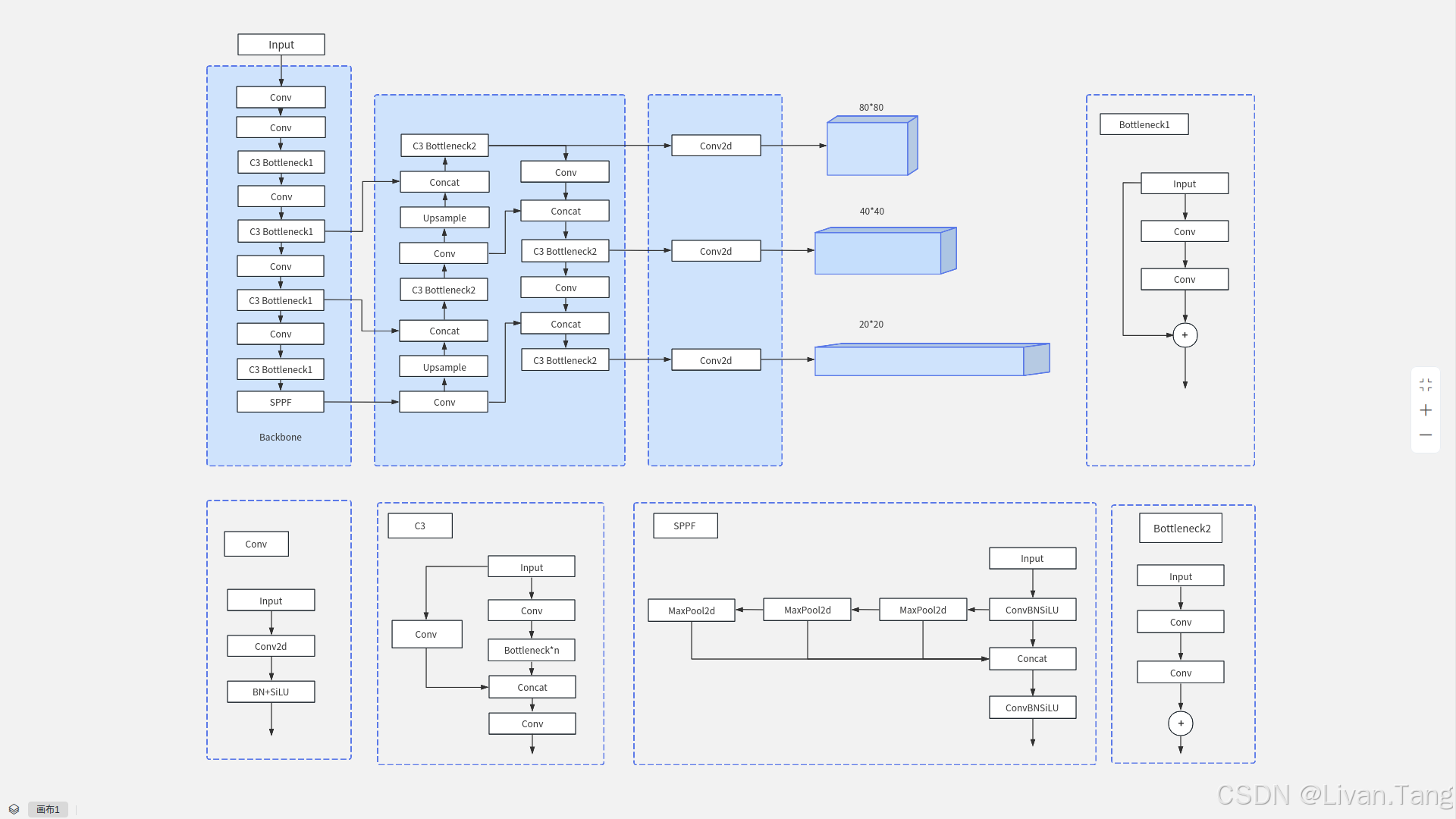
Yolov5网络架构图
1. 模型架构改进
(1) Backbone 和 Neck 的优化
-
C2f 模块:
YOLOv8 引入了 C2f(Cross Stage Partial with 2 convolutions)模块,替代了 YOLOv5 中的 C3 模块。C2f 通过增加跨层连接和更多的分支结构,提升了特征提取能力,同时减少了计算量。
计算量降低的核心原因
(1) 参数共享与计算复用
C3的冗余计算:
在C3的Bottleneck分支中,每个Bottleneck的输入是前一个Bottleneck的输出,导致特征需逐层重复计算。例如,第3个Bottleneck的输入依赖第2个Bottleneck的输出,而第2个又依赖第1个,形成链式依赖,无法并行。C2f的计算复用:
C2f通过Split操作将输入特征图分成多份,每个Bottleneck处理独立的子张量(部分实现中),避免链式计算依赖。例如:
若输入通道数为
C,Split为n份,则每个Bottleneck仅处理C/n通道,计算量显著降低。最终通过Concat合并所有Bottleneck的输出,恢复通道数,但总计算量低于C3的链式堆叠。
(2) Bottleneck的轻量化改进
C3的Bottleneck:
默认使用标准Bottleneck(1x1 Conv降维 + 3x3 Conv + 1x1 Conv升维),参数量较大。C2f的Bottleneck:
YOLOv8对Bottleneck进行了优化:
减少升维卷积:部分Bottleneck省略了最后的1x1升维卷积,直接拼接原始特征。
深度可分离卷积(DWConv):在部分分支中用DWConv替代标准3x3 Conv,减少计算量(例如3x3 DWConv的计算量是普通Conv的
1/通道数)。(3) 通道数的动态调整
C3的固定通道分配:
两条分支的通道数通常是均分的(例如各占50%),可能导致部分通道利用率不足。C2f的动态通道分配:
通过Split和Concat的灵活组合,可以按需分配通道数(例如浅层网络减少Bottleneck分支的通道比例),避免冗余计算。
-
更深的网络结构:
Backbone 和 Neck 的深度增加,通过更复杂的特征融合提升检测精度,尤其是在小目标和密集场景中。
(2) 解耦头(Decoupled Head)
YOLOv8 将分类头和回归头分离(解耦设计),而 YOLOv5 使用的是耦合头。这种设计能更专注地优化分类和定位任务,提升检测精度。
(3) Anchor-Free 检测头
YOLOv8 放弃了 YOLOv5 的 Anchor-Based 设计,转向 Anchor-Free 检测头(类似 YOLOX),直接预测目标中心点和宽高。这简化了模型,减少了对预定义 Anchor 的依赖,更适合复杂场景。
| 特性 | Anchor-Based 偏移 | Meshgrid-Based 偏移(Anchor-Free) |
|---|---|---|
| 偏移参考 | 相对于 anchor 的尺寸和位置 | 相对于 feature map 上的网格中心 |
| Anchor 设计 | 需要设定多个尺度和比例的 anchor(如 3×3=9 个) | 无需手动设计 anchor |
| 匹配策略 | 使用 IOU 匹配 GT 与 anchor(正负样本) | 每个网格直接判断中心是否落在 GT 内 |
| 偏移目标 | (tx, ty, tw, th) 针对 anchor 进行偏移预测 | (l, t, r, b) 或 (cx, cy, w, h) 相对 meshgrid 偏移 |
| 网络输出维度 | 输出和 anchor 数量有关(3 anchors ⇒ 输出 ×3) | 输出仅与网格数量有关(简洁) |
| 超参数 | 多(anchor 尺寸、正负阈值、匹配策略) | 少(无需 anchor 配置) |
2. 训练策略改进
(1) 损失函数优化
-
分类损失:
使用 Distribution Focal Loss(DFL),替代 YOLOv5 的 BCE Loss,提升分类鲁棒性。

-
回归损失:
结合 CIoU(Complete IoU) 和 DFL,优化边界框回归的精度和稳定性。
1. 分类损失:Distribution Focal Loss (DFL)
(1) 背景
在目标检测中,分类任务的目标是预测每个目标的类别概率分布。传统的分类损失函数(如 YOLOv5 中的 BCE Loss,即二元交叉熵损失)在处理类别不平衡问题时表现不佳,尤其是在正负样本比例悬殊的情况下。
(2) Focal Loss 的引入
Focal Loss 是 Facebook AI 提出的一种改进损失函数,主要用于解决类别不平衡问题。它通过降低易分类样本的权重,使模型更关注难分类的样本。Focal Loss 的公式如下:
其中:
pt 是模型预测的概率。
αt是类别权重,用于平衡正负样本。
γ 是调节因子,用于降低易分类样本的权重。
(3) Distribution Focal Loss (DFL)
DFL 是 Focal Loss 的进一步扩展,主要用于处理分类任务中的概率分布。它的核心思想是:
将分类任务看作一个概率分布回归问题,而不是简单的二元分类。
通过优化概率分布的离散值,提升分类的鲁棒性。
DFL 的公式如下:
其中:
yi 是目标类别的真实分布。不是 one-hot 的 0/1,而是一个soft label 分布(比如 y=[0.3,0.7]y = [0.3, 0.7]y=[0.3,0.7],表示介于 class1 和 class2 之间);
pi 是模型预测的概率分布。
DFL 本质:带 soft target 的加权交叉熵。典型的 DFL 解码过程,DFL 在预测回归值时,不是直接输出一个数值,而是输出一个 概率分布(长度为 16 或其他),这个分布通过 softmax 得到每个 bin 的概率,然后用加权平均得到最终的值。
(4) DFL 的优势
更好的鲁棒性:DFL 能够更好地处理类别不平衡问题,尤其是在目标检测中,背景样本(负样本)通常远多于目标样本(正样本)。
更精确的概率分布:DFL 通过优化概率分布,使模型输出的分类分数更准确。
适用于 Anchor-Free 设计:DFL 特别适合 YOLOv8 的 Anchor-Free 检测头,因为它直接优化目标的中心点概率分布。
2. 回归损失:CIoU + DFL
(1) 背景
回归任务的目标是预测目标的边界框(Bounding Box),通常包括中心点坐标(x, y)和宽高(w, h)。传统的回归损失函数(如 L1/L2 Loss)只关注坐标的绝对误差,而忽略了边界框之间的几何关系。
(2) IoU 系列损失函数
为了优化边界框回归,YOLOv8 使用了 CIoU (Complete IoU) 损失函数。CIoU 是 IoU 系列损失函数的一种改进版本,它不仅考虑了重叠面积,还考虑了中心点距离和宽高比。
CIoU 的公式如下:
其中:
IoU 是预测框和真实框的交并比。
ρ2(b,bgt) 是预测框和真实框中心点的欧氏距离。
c 是最小包围框的对角线长度。
v 是宽高比的相似性度量。
α 是权重系数。
(3) DFL 在回归任务中的应用
在 YOLOv8 中,DFL 不仅用于分类任务,还被引入到回归任务中,用于优化边界框的中心点预测。具体来说:
回归任务不仅预测边界框的宽高,还预测中心点的概率分布。
DFL 通过优化中心点的概率分布,使边界框的定位更精确。
(4) CIoU + DFL 的优势
更精确的边界框回归:CIoU 考虑了重叠面积、中心点距离和宽高比,使边界框回归更准确。
更稳定的训练:DFL 通过优化中心点的概率分布,提升了回归任务的稳定性。
更好的小目标检测:CIoU 和 DFL 的结合特别适合小目标检测,因为小目标的边界框定位通常更难。
3. 损失函数的总和
YOLOv8 的总损失函数由分类损失和回归损失组成,具体形式如下:
其中:
λcls、λreg、λDFL 是各损失项的权重系数。
DFLcls 是分类任务的 DFL 损失。
CIoUreg 是回归任务的 CIoU 损失。
DFLreg 是回归任务的 DFL 损失。
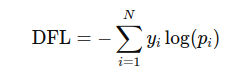
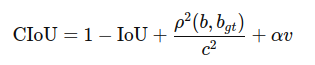
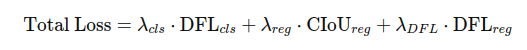
(2) 数据增强增强
在 Mosaic、MixUp 等传统增强基础上,引入了更灵活的 随机缩放比例 和 自适应图片填充策略,减少信息丢失。
(3) 标签分配策略
采用 Task-Aligned Assigner(任务对齐分配器),动态分配正负样本,替代 YOLOv5 的静态分配策略,提升训练效率。
3. 任务扩展与多任务支持
-
支持实例分割:
YOLOv8 扩展了任务范围,除了目标检测,还支持 实例分割(通过分割头实现),而 YOLOv5 仅专注于检测。 -
姿态估计支持:
通过扩展模型结构,YOLOv8 可以支持人体关键点检测(姿态估计),适用场景更广泛。
4. 性能与效率优化
-
速度与精度平衡:
在相同计算量下,YOLOv8 的精度(mAP)比 YOLOv5 提升约 5-10%,同时保持相近的推理速度。 -
更灵活的模型缩放:
提供从轻量级(YOLOv8n)到超大模型(YOLOv8x)的多尺寸版本,且缩放策略更高效。 -
部署优化:
对 TensorRT、ONNX 等推理框架的支持更完善,量化后的模型精度损失更小。
5. 其他改进
-
更简洁的代码结构:
YOLOv8 的代码库进一步模块化,易于定制和扩展。 -
自监督预训练支持:
支持基于无标签数据的预训练(如 DETR 风格的预训练),提升小数据集上的表现。 -
更丰富的文档和社区支持:
Ultralytics 提供了更详细的文档和预训练模型,覆盖更多应用场景。
总结对比表
| 改进方向 | YOLOv5 | YOLOv8 |
|---|---|---|
| 检测头设计 | Anchor-Based + 耦合头 | Anchor-Free + 解耦头 |
| Backbone 模块 | C3 模块 | C2f 模块 |
| 损失函数 | BCE Loss + CIoU Loss | DFL + CIoU Loss |
| 任务支持 | 目标检测 | 检测、实例分割、姿态估计 |
| 标签分配 | 静态分配(基于 Anchor) | 动态分配(Task-Aligned Assigner) |
| 模型效率 | 高速度,中等精度 | 高速度,更高精度 |
适用场景建议
-
YOLOv5:适合对速度要求极高、硬件资源有限的场景(如嵌入式设备)。
-
YOLOv8:适合需要更高精度、多任务支持(检测+分割)的场景(如工业检测、自动驾驶)。
YOLOv8 通过架构创新和训练策略优化,显著提升了模型性能,同时保持了 YOLO 系列的高效率特性,是目前更推荐的主流选择。

















 1865
1865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









