






 本文探讨了机器学习和神经网络在模式识别系统中的重要性,尤其是卷积神经网络(CNN)在手写字符识别中的优越性。LeNet-5作为CNN的一种,通过全局训练和图变网络(GTN)提高了识别准确性。文章比较了不同学习技术在手写数字识别任务中的表现,并展示了全局训练的优势。LeNet-5结构包含多层,通过特征提取和下采样层有效处理二维形状变化。CNN和GTN的应用已广泛用于商业领域,如银行支票识别系统。
本文探讨了机器学习和神经网络在模式识别系统中的重要性,尤其是卷积神经网络(CNN)在手写字符识别中的优越性。LeNet-5作为CNN的一种,通过全局训练和图变网络(GTN)提高了识别准确性。文章比较了不同学习技术在手写数字识别任务中的表现,并展示了全局训练的优势。LeNet-5结构包含多层,通过特征提取和下采样层有效处理二维形状变化。CNN和GTN的应用已广泛用于商业领域,如银行支票识别系统。
经典论文阅读 (一) Lenet

Abstract
Multilayer Neural Networks trained with the backpropagation algorithm constitute the best example of a successful Gradient-Based Learning technique. Given an appropriate network architecture, Gradient-Based Learning algorithms can be used to synthesize a complex decision surface that can classify high-dimensional patterns such as handwritten characters, with minimal preprocessing. This paper reviews various methods applied to handwritten character recognition and compares them on a standard handwritten digit recognition task. Convolutional Neural Networks, that are specifically designed to deal with the variability of 2D shapes, are shown to outperform all other techniques.
使用反向传播算法训练的多层神经网络是一种成功的基于梯度的学习技术的最好例子。在适当的网络架构下,基于梯度的学习算法可以用最少的预处理来合成复杂的决策面,从而对高维模式(如手写字符)进行分类。本文综述了用于手写体字符识别的各种方法,并对它们在标准手写体数字识别任务中的应用进行了比较。卷积神经网络,是专门设计来处理变化的二维形状,显示优于所有其他技术。
Real-life document recognition systems are composed of multiple modules including field extraction, segmentation, recognition, and language modeling. A new learning paradigm, called Graph Transformer Networks (GTN), allows such multi-module systems to be trained globally using Gradient-Based methods so as to minimize an overall performance measure.
Two systems for on-line handwriting recognition are described. Experiments demonstrate the advantage of global training, and the fexibility of Graph Transformer Networks.
现实生活中的文档识别系统由字段提取、分割、识别和语言建模等多个模块组成。
一种新的学习范式,称为图变网络(GTN),允许使用基于梯度的方法对这样的多模块系统进行全局训练,从而使整体性能度量最小化。
描述了两种在线手写识别系统。实验证明了全局训练的优点和图变网络的可靠性。
A Graph Transformer Network for reading bank check is also described. It uses Convolutional Neural Network character recognizers combined with global training techniques to provides record accuracy on business and personal checks It is deployed commercially and reads several million checks per day.
介绍了一种用于读取银行支票的图变网络。它使用卷积神经网络字符识别器,结合全局训练技术,提供商业和个人检查记录的准确性。它被用于商业用途,每天读取数百万张支票。
I. Introduction
Over the last several years, machine learning techniques, particularly when applied to neural networks, have played an increasingly important role in the design of pattern recognition systems.
In fact, it could be argued that the availability of learning techniques has been a crucial factor in the recent success of pattern recognition applications such as continuous speech recognition and handwriting recognition.
在过去的几年中,机器学习技术,特别是当应用到神经网络时,在模式识别系统的设计中发挥了越来越重要的作用。
事实上,学习技术的可用性是最近成功的模式识别应用的一个关键因素,如连续语音识别和笔迹识别。
The main message of this paper is that better pattern recognition systems can be built by relying more on automatic learning, and less on hand-designed heuristics.
This is made possible by recent progress in machine learning and computer technology.
Using character recognition as a case study, we show that hand-crafted feature extraction can be advantageously replaced by carefully designed learning machines that operate directly on pixel images.
Using document understanding as a case study, we show that the traditional way of building recognition systems by manually integrating individually designed modules can be replaced by a unified and well-principled design paradigm, called Graph Transformer Networks, that allows training all the modules to optimize a global performance criterion
这篇论文传递的是,更好的模式识别系统可以通过更多地依赖于自动学习而不是手工设计的启发式来建立。
这是由于最近机器学习和计算机技术的进步。
以字符识别为例,我们表明,精心设计的直接对像素图像操作的学习机可以很好地替代手工特征提取。
使用文档理解作为一个案例研究中,我们表明,传统的识别系统设计是通过手动积分单独设计模块,可以取而代之的是一个统一、有准则的设计范式,称为图变换网络,使训练的所有模块能够优化全局性能标准。
Since the early days of pattern recognition it has been known that the variability and richness of natural data, be it speech, glyphs, or other types of patterns, make it almost impossible to build an accurate recognition system entirely by hand.
Consequently, most pattern recognition systems are built using a combination of automatic learning techniques and hand-crafted algorithms.
The usual method of recognizing individual patterns consists in dividing the system into two main modules shown in figure 1.The first module, called the feature extractor, transforms the input patterns so that they can be represented by lowdimensional vectors or short strings of symbols that (a) can be easily matched or compared, and (b) are relatively invariant with respect to transformations and distortions of the input patterns that do not change their nature.
The feature extractor contains most of the prior knowledge and is rather specific to the task. It is also the focus of most of the design effort, because it is often entirely hand-crafted.
The classifier, on the other hand, is often general-purpose and trainable. One of the main problems with this approach is that the recognition accuracy is largely determined by the ability of the designer to come up with an ppropriate set of features.
This turns out to be a daunting task which, unfortunately, must be redone for each new problem. A large amount of the pattern recognition literature is devoted to describing and comparing the relative, merits of different featrue sets for particular tasks.
自早期的模式识别以来,人们已经知道,自然数据的可变性和丰富性,无论是语音、象形文字,还是其他类型的模式,几乎不可能完全靠手工建立一个准确的识别系统。
因此,大多数模式识别系统都是使用自动学习技术和手工制作算法的结合来建立的。
识别单个模式的通常方法是将系统划分为两个主要模块,如图1所示。
第一个模块,称为特征提取器,转换输入的方式,这样他们可以用低维向量或短字符串的符号(a)可以很容易地匹配或相比,和(b)是相对不变的对输入模式的转换和扭曲,不改变自己的本质。
特征提取器包含了大部分的先验知识,并且是特定于任务的,它也是大部分设计工作的重点,因为它通常是完全人工制作的。
另一方面,分类器通常是通用的和可训练的。这种方法的一个主要问题是识别的准确性很大程度上取决于设计者提出适当的特征集的能力。
这是一项艰巨的任务,不幸的是,每个新问题都必须重新执行。大量的模式识别文献致力于描述和比较不同特征集对特定任务的相对优点。

Historically, the need for appropriate feature extractors was due to the fact that the learning techniques used by the classifiers were limited to low-dimensional spaces with easily separable classes[1].
A combination of three factors have changed this vision over the last decade.
First, the availability of low-cost machines with fast arithmetic units allows to rely more on brute-force “numerical” methods than on algorithmic refinements. Second, the availability of large databases for problems with a large market and wide interest, such as handwriting recognition, has enabled designers to rely more on real data and less on hand-crafted feature extraction to build recognition systems. The third and very important factor is the availability ofpowerful machine learning techniques that can handle high-dimensional inputs and can generate intricate decision functions when fed with these large data sets. It can be argued that the recent progress in the accuracy of speech and handwriting recognition systems can be attributed in large part to an increased reliance on learning techniques and largetraining data sets. As evidence to this fact, a large proportion of modern commercial OCR systems use some form of multi-layer Neural Network trained with back-propagation.
之前,需要合适的特征提取是由于:分类器使用的学习技术仅限于具有易于分离类的低维空间[1]。
在过去的十年里,三个因素的结合改变了这一愿景。
首先,具有快速运算单元的低成本机器的可用性,使人们更多地依赖于蛮力的“数值”方法,而不是算法的改进。
其次,大型数据库的可用性和巨大的市场和广泛的兴趣,如手写识别,使设计师可以更多地依赖真实的数据,而不是手工特征提取来建立识别系统。
第三个也是非常重要的因素是强大的机器学习技术的可用性,它可以处理高维的输入,当输入这些大数据集时,可以生成复杂的决策函数。
可以说,最近语音和笔迹识别系统在准确性方面的进步很大程度上归功于对学习技术和大量训练数据集的日益依赖,依据是大部分现代商业OCR系统都使用某种形式的使用反向传播训练的多层神经网络。
In this study, we consider the tasks of handwritten character recognition (Sections I and II) and compare the performance of several learning techniques on a benchmark data set for handwritten digit recognition (Section II1).While more automatic learning is beneficial, no learning technique can succeed without a minimal amount of prior knowledge about the task.
In the case of multi-layer neural networks, a good way to incorporate knowledge is to tailor its architecture to the task. Convolutional Neural Networks [2] introduced in Section II are an example of specialized neural network architectures which incorporate knowledge about the invariances of 2D shapes by using local connection patterns, and by imposing constraints on the weights. A comparison of several methods for isolated handwritten digit recognition is presented in section III. To go from the recognition of individual characters to the recognition of words and sentences in documents, the idea of combining multiple modules trained to reduce the overall error is introduced in Section IV. Recognizing variable-length objects such as handwritten words using multi-module systems is best done if manipulate directed graphs.
在本研究中,我们考虑了手写体字符识别的任务**(第一节和第二节),并比较了几种学习技术在手写体数字识别基准数据集上的性能(第一节)。虽然更多的自动学习是有益的,但是如果没有关于任务的最小的先验知识,任何学习技术都不能成功。
对于多层神经网络,整合知识的一个好方法是根据任务定制其架构。
在第二节**中介绍的卷积神经网络[2]是一个专门的神经网络架构的例子,它通过使用局部连接模式,并通过对权重施加约束,将二维形状不变量的知识纳入其中。
第三节对几种独立手写数字识别方法进行了比较。
从单个字符的识别到文档中的单词和句子的识别,第四节介绍了将训练过的多个模块结合起来以减少整体错误的想法。如果要处理有向图,最好使用多模块系统来识别可变长度的对象(比如手写的单词)。
This leads to the concept of trainable Graph Transformer Network (GTN) also introduced in Section IV. Section V describes the now classical method of heuristic over-segmentation for recognizing words or other character strings. Discriminative and non-discriminative gradient-based techniques for training a recognizer at the word level without requiring manual segmentation and labeling are presented in Section VI. Section VII presents the promising Space-Displacement Neural Network approach that eliminates the need for segmentation heuristics by scanning a recognizer at all possible locations on the input. In section VIII, it is shown that trainable Graph Transformer Networks can be formulated as multiple generalized transductions, based on a general graph composition algorithm. The connections between GTNs and Hidden Markov Models, commonly used in speech recognition is also treated. Section IX describes a globally trained GTN system for recognizing handwriting entered in a pen computer. This problem is known as “on-line” handwriting recognition, since the machine must produce immediate feedback as the user writes. The core of the system is a Convolutional Neural Network.The results clearly demonstrate the advantages of training a recognizer at the word level, ratherthantrainingit on pre-segmented, hand-labeled, isolated characters. Section X describes a complete GTN-based system for reading handwritten and machine-printed bank checks. The core of the system is the Convolutional Neural Network called LeNet-5 described in Section II. This system is in commercial use in the NCR Corporation line of checkrecognition systems for the banking industry. It is reading millions of checks per month in several banks across the United States.
这就引出了可训练图变网络(GTN)的概念,GTN也在第四节中被引入。第五节描述了目前用于识别单词或其他字符串的经典启发式过分割方法。
歧视和基于歧视性梯度技术培训一个识别器在单词层面而不需要手动分割和标签是在第六节。第七部分给出了承诺Space-Displacement神经网络的方法,不需要细分启发式扫描识别器在所有可能的输入位置。
在第VIII节中,我们展示了可训练的图变网络可以根据一般的图构成算法,被表述为多重广义变换。
文中还讨论了语音识别中常用的GTNs与隐马尔科夫模型之间的联系。
第IX节描述了一个全球训练的GTN系统识别手写输入钢笔计算机。
这个问题被称为“在线”手写识别,因为机器必须在用户写字时立即产生反馈。
系统的核心是卷积神经网络。
结果清楚地表明,在单词层面上训练识别器比在预分割的、手标记的、孤立的字符上训练识别器更有优势。
第X节描述了一个完整的基于gtn的系统,用于读取手写和机器打印的银行支票。
系统的核心是第二节中描述的卷积神经网络LeNet-5。
该系统在商业上应用于NCR公司的银行业支票识别系统。
它每月在美国的几家银行读取数百万张支票。
A Learn from Data
这部分首先说明了一些函数以及变量:
分类函数
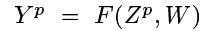
Zp, W
where
ZPis the p-th input pattern, andWrepresents the ollection of adjustable parameters in the system.
Yp
In a pattern recognition setting, the output
YPmay be interpreted as the recognized class label of patternZP, or as scores or probabilities associated with each class.
误差函数
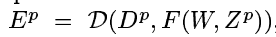
Dp
DP, the “correct” or desired output for patnZP, and the output produced by the system
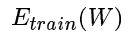
是整个数据集的误差函数的均值
然后说明了一个简单情况下的策略:寻找使Etrain最小的W。
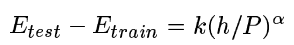
测试集和训练集的差值,由这些值决定:
P是训练的样本数,h是计算的有效能力或者机器的复杂程度,α是在0.5到1之间的数,k是常数。
当训练的样本数P增多时这个差值就会下降。
当容量h增大时,
II CNN for Isolated Character Recognition
B LeNet-5

这部分重点介绍LeNet-5.LeNet包含7层(不算输入层),每一层都包含可训练的参数(权重)。输入为32×32像素的图像,(这比数据库中最大的图像还要大,因此足够大了)
layer C1

六个feature map的一个单元对应输入的5×5的元素。feature map的尺寸为28×28,可以防止输入的连接脱离边界。C1包含156个可训练参数,与输入之间共有156* 28* 28个连接。
layer S2

下采样层(池化层),有6个feature maps,每个14×14,其中每个单元与C1的2×2相连,池化方法是C1的这四个元素相加,然后与一个可训练的参数相乘再加一个可训练的偏置,再将结果通过sigmoidal function。这2×2的区域是不重叠的,因此S2的行、列数是C1的一半。S2有4×3个可训练参数,141430个连接。
layer C3


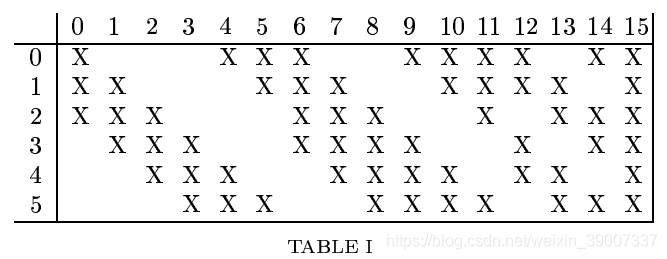
C3有16个feature maps,每个单元与S2有5×5个连接,
通过这样的连接,可以将连接的数量控制在合理的范围内;并且破坏了网络的对称性,不同特征图被迫提取不同的特征。这个表的连接方案的原理如下:前六个feature map从S2的三个feature map的每个相邻子集中获取输入,接下来的6个通过从每个连续的四个子集中获取输入,然后三个从不连续的4个子集中获取输入,最后一个从S2的所有子集获取输入,因此需要的参数数量为:
6 *(3 *5 *5+1)+6 * (4 *5 *5+1)+3 * (4 * 5 * 5 +1)+1 * (6 * 5 * 5 + 1 ) = 1516
每个卷积核的一个单元都要与S2中的10 * 10个单元连接,则总共需要151600个连接
layer S4

S4为第二个下采样层,与S2算法类似,由C3与2*2卷积核卷积而得(no overlapping)。则需要16 * 2 = 32 个可训练参数,有16 * (2 * 2 + 1 ) * 5 * 5 = 2000个连接
layer C5

C5是第三个卷积层,有120个feature map,还是5 * 5 卷积核,因为S4也是5 * 5,所以每个feature map 是1 * 1,与S4全连接,之所以C5不被称为全连接层,是因为,如果输入更大,那这里C5的大小可能不是1 * 1。可训练的参数为120 * (16 * 5 * 5 + 1) = 120 * 401 = 48120个连接
layer F6

有84个units,与C5是全连接层,需要可训练参数84 * (120+1) = 10164
这个84是因为,96个ASCII码,有84个是表示字符的。



在一个传统的神经网络中,从C1到F6的每一个单元,都是由输入向量与权重向量相乘然后再加一个偏移量得到的,这个加权和ai再通过一个sigmoid squashing 函数,用其结果表示单元ii的状态。
squashing函数如文献中的公式(6)所示,公式中的A为函数幅度,S决定了原点处的斜率。这个函数是奇函数,有两条水平渐近线±A,这里的A被选为1.7159
output layer


最后,输出层由一个Euclidean Radial Basis Function units(欧式径向基函数,RBF)组成,每类组成一个单元,每个单元有84个输入。这个公式在几何上可以理解为计算输入矢量与其参数矢量的欧式距离。
对于一些较容易混淆的字符,就要依赖语言后处理来提高准确性了

这里没有看懂,而且估计也没人会读到这里甚至读吧…
C 损失函数

最简单的输出损失函数是最大似然估计准则(Maximum Likelihood Estimation criterion,MSE)这个准则对于一个训练集是很简单的:
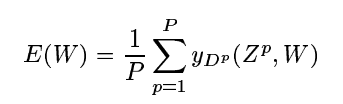


yDp是第Dp个RBF单元的输出,亦即对应于输入Zp正确分类的输出。这种损失函数适用于大多数情况,但是缺少三个重要的特性:
1)如果我们使RBF的参数有适应性,E(W)有一个微不足道的,但完全不可接受的解,在这个解中,所有的RBF参数向量都相等,且F6的状态为常数,等于该参数向量。这样所有的RBF输出都为0,如果不允许RBF权值适应,则不会发生这种坍缩现象。(我的理解是,如果有适应性,就会产生一个通解,这个解造成RBF的输出都是0)
2)类与类之间没有竞争,可以通过一个更有区别的训练准则来实现,即最大后验估计(maximum a posteriori,MAP),类似于有时用来训练HMMs的最大互信息准则(Maximum Mutual Information,MMH)假设输入图像来自一个类,或者哪个类都不属于(即rubbish),那么它就相当于将正确类的后验概率最大化(或者最小化正确类概率的对数)在惩罚方面,它既可以像MSE那样将正确分类pushing down,也可以将错误结果pulls up
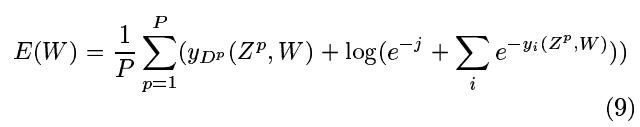
第二项为一个负值,起着MSE没有的竞争的作用。常数j是正的,用来防止将分类的惩罚进一步推高。垃圾类的后验概率是e-j与第二项中求和项的比值。这个判别标准防止了前面提到的“坍缩效应”,因为它使RBF中心彼此分开

损失函数相对于卷积网络所有层中所有权值的梯度是通过反向传播来计算的。标准算法必须稍加修改,以考虑到权值的共享。一个简单的实现方法是首先计算损失函数对每个连接的偏导数,就好像网络是一个传统的没有权值共享的多层网络。然后将具有相同参数的所有连接的偏导数相加,形成对该参数的导数。
可以非常有效地培训这样一个大型体系结构,但是这样做需要使用附录中描述的一些技术。附录的A部分描述了一些细节,比如使用的特定的sigmoid和权重初始化。B节和C节描述了所使用的最小化过程,它是Levenberg-Marquardt过程对角逼近的随机版本。

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









