







Efficient Sparse Pose Adjustment for 2D Mapping
摘要
位姿图是解决SLAM问题的一种常用表示方法。位姿图是一组机器人位姿的几何,这些位姿由特征观测得到的非线性约束连接到附近的位姿。大型位姿图的优化一直是移动机器人的一个瓶颈,因为直接非线性优化的计算时间会随着图的大小呈立方增长。本文提出了一种构造和求解线性子问题的有效方法,这是这些直接方法的瓶颈。我们比较了稀疏位姿调整(SPA)方法和其他间接方法,结果展示我们的方法的收敛速度和精度都大大超过了其他方法。我们在一组大的室内真实地图和一个非常大的仿真数据集上展示了它的有效性。C++中的开源实现和数据集是公开可用的。
引言
最近有关机器人建图的文献表明,对基于图的SLAM方法的兴趣越来越大。在最常见的形式中,图中有表示机器人位姿态和世界特征的节点,测量值作为约束将它们连接起来。所有方法的目标都是联合优化节点的姿态,以最小化约束带来的误差。这个问题的一个经典变体来自计算机视觉,被称为BA,它通常用Levenberg-Marquardt(LM)非线性优化器的一个特殊变体来求解。
由于特征的数量往往超过机器人的位姿的数鲁昂,可以通过将特征观测转换为机器人位姿之间的直接约束(通过边缘化或者直接匹配)、来创建更多的紧凑系统。在典型的机器人建图应用中,位姿约束系统表现出了稀疏的连接结构,因为传感器的范围通常限制在机器人附近。
有效地求解位姿图(即寻找节点的最优位置)是这些方法的关键问题,特别是在在线建图问题中。一个 100 m × 100 m 100m \times 100m 100m×100m办公空间的典型二维激光地图可能有几千个节点和更多的约束。此外,向该地图添加闭环约束可以影响系统中几乎所有的位姿。
LM方法的核心在于解决一个大的稀疏线性问题。本文提出了一种从约束图中高效计算稀疏矩阵的方法,并用直接稀疏线性方法求解。类似于计算机视觉文献中提到的稀疏BA,我们称这种方法为稀疏位姿调整(SPA),因为它处理的是位姿和位姿之间的约束。将SBA/GraphSLAM优化器与求解线性子问题的有效方法相结合具有以下优点
- 它考虑了约束中的协方差信息,从而得到更精确的解。
- SPA对初始化具有鲁棒性和容错性,对于增量和批处理都具有很低的故障率(陷入局部极小值)。
- 收敛速度非常快,因为它只需要对LM方法进行几次迭代。
- 与EKF和信息滤波器不同,SPA是完全非线性的:每次迭代时,它都会将当前位姿周围的所有约束线性化。
- SPA在批处理和增量模式下都是有效的。
我们在“实验结果”部分中记录了该方法的这些和其他特性,并将我们的方法与其他LM和非LM最先进的优化器进行了比较。
SPA的一个好处是建图系统可以连续不断地优化它,提供所有节点的最佳全局估计,而且只需很少的计算开销。在增量模式下,在添加每个节点后对图进行优化,添加任何节点后进行优化所需的时间都不超过15毫秒。
虽然SPA可以用于三维位姿参数化,但本文将其局限于二维建图,这是一个发展良好的领域,具有多种具有竞争性的优化技术。我们的目的是表明,如果使用SPA作为其优化引擎,即使在带有大尺度闭环的大规模环境中,基于二维位姿的建图系统也可以在线运行。而不需要使用子图来进行储存或使用复杂的切分方案
系统形成
解决SLAM问题的流行方法是所谓的“基于图的”或“基于网络的”方法。这种思想是用一个图来表示机器人的历史测量,图中的每个节点都表示一个传感器测量值或者一个局部地图,并在节点上标记测量被获取的位置。两个节点之间的边表示由连接测量的对齐产生的空间信息,可以视为两个节点之间的空间约束。
在基于图的SLAM的上下文中,通常会考虑两个不同的问题。第一种是基于传感器数据的约束识别。由于环境中潜在的模糊性或对称性,这种所谓的数据关联问题通常很难解决。这个问题的解决方案通常被称为SLAM前端,它直接处理传感器数据。第二个问题是修正机器人的姿态,以获得给定约束条件下环境的一致地图。这部分方法被称为优化器或SLAM后端。它的任务是寻找一个节点的配置,使约束中编码的测量的似然最大化。物理学中的弹簧-质量模型给出了这个问题的另一种观点。在这个视图中,节点被视为质量,约束被视为与质量相连的弹簧,弹簧和质量的最小能量配置描述了建图问题的解决方案。
如下图所示,在其操作过程中,基于图形的SLAM系统交错执行前端和后端。这是必需的,因为前端需要在部分优化的地图上操作,以限制对潜在约束的搜索。当前的估计越精确,前端产生的约束就越鲁棒,运算速度也就越快。因此,以估计精度和执行时间衡量的优化算法的性能对整个建图系统有很大影响。
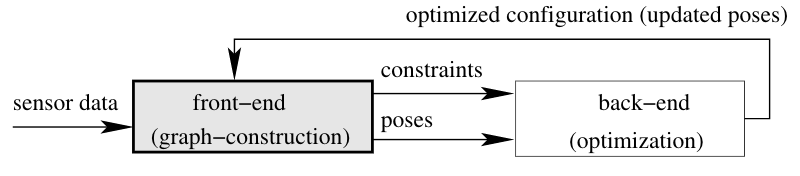
本文详细描述了一种高效、紧凑的二维图优化方法。我们的算法可以与处理不同类型传感器的任意前端耦合。为了表达的清晰,我们简要地描述了激光数据的前端。然而,提到的概念可以直接应用于不同的传感器。
稀疏位姿调整
为了优化一组姿势和约束,我们使用著名的Levenberg-Marquardt(LM)方法作为一个框架,通过特定的实现,可以有效地处理二维地图构建中遇到的稀疏系统。类似于计算机视觉中的稀疏BA,它是一个类似于LM的有效实现,用于相机和特征,我们称之为稀疏位姿调整(SPA)
A.误差公式
系统变量是机器人的全局位姿的集合 c c c,由平移和角度参数化: c i = [ t i , θ i ] = [ x i , y i , θ i ] T c_i = [t_i,\theta_i] = [x_i,y_i,\theta_i]^T ci=[ti,θi]=[xi,yi,θi]T. 约束是从其他节点 c j c_j cj的位置对节点 c i c_i ci的测量。在 c i c_i ci的坐标系下, c i c_i ci和 c j c_j cj之间的测量偏移为̄ z ˉ i j \bar{z}_{ij} zˉij,精度矩阵 ∧ i j ∧_{ij} ∧ij(协方差矩阵的逆)。对于任何 c i c_i ci和 c j c_j cj的实际姿态,其偏移量可计算为
h ( c i , c j ) = { R i T ( t j − t i ) θ i − θ i (1) h(c_i,c_j) = \{ \begin{matrix} R_i^T(t_j - t_i) \\ \theta_i - \theta_i\end{matrix} \tag{1} h(ci,cj)={
RiT(tj−ti)θi−θi(1)
其中 R i R_i Ri是代表 θ i \theta_i θi的 2 × 2 2 \times 2 2×2的旋转矩阵, h ( c i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









