







本文借鉴引用1的知乎文章,进行了细节的补充,根据后期硬件实现需要做了重新介绍与排版,感谢知乎博主。阅读本文建议先阅读引用1的知乎文章。
Transformer硬件实现第一篇算法结构分析,作为数字电路领域的学生,后期会不断更新,最终利用Verilog语言设计一个Transformer加速器。
前言
Transformer是全连接层+Attention的结合体。任意单词之间的距离是1,解决了NLP的长期依赖问题。并行性好,应用不局限在nlp。
彻底摒弃了rnn和cnn,丧失了局步特征捕捉能力,三者结合带来更好结果。模型无法捕捉位置信息,Position Embedding只是权宜之计。
实现Transformer硬件加速器,首先需要理解算法的各个计算单元。
零、顶层结构
Transformer本质是一个Encoder和Decoder模型。Encoder和Decoder各包含6个block。对1个block,结构如下:
1.数据送入self-attention模块,得到加权的特征向量Z,即
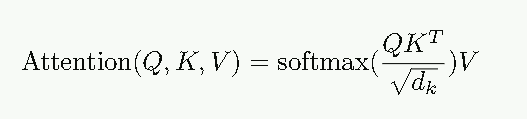
2.得到的结果Z送入二层前馈网络层,第一层为ReLU,第二层为全连接层。
一与二步骤完成Encoder的计算,现在将得到的结果送入Decoder。Decoder由Self-attention + Encoder-decoder attention + 前馈网络组成。
3.Self-attention:上下文的关系,即当前句子与之
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









