







every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
VOC数据集,简单梳理
1. 正文
1.1 简介
PASCAL VOC挑战赛主要有以下几类:
- Object Classification
- Object Detection
- Object Segmentation
- Human Layout
- Action Classification
数据集总共分4大类,20小类(加背景一共21类),预测时只输出图中黑色(即20类)

1.2 发展历程
颜色相同,为相同数据。
07年的中的test数据集部分进行了公开,所有12年不包含07年的,二者互斥,目前常用的实验用二者“排列组合”。

1.3 数据集数量
红色为没有公开,估计部分。

1.4 数据集下载
命令行
# Download the data.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
下载并解压:
.
├── Annotations 进行detection 任务时的 标签文件,xml文件形式
├── ImageSets 存放数据集的分割文件,比如train,val,test
├── JPEGImages 存放 .jpg格式的图片文件
├── SegmentationClass 存放 按照class 分割的图片
└── SegmentationObject 存放 按照 object 分割的图片
具体文件:
-
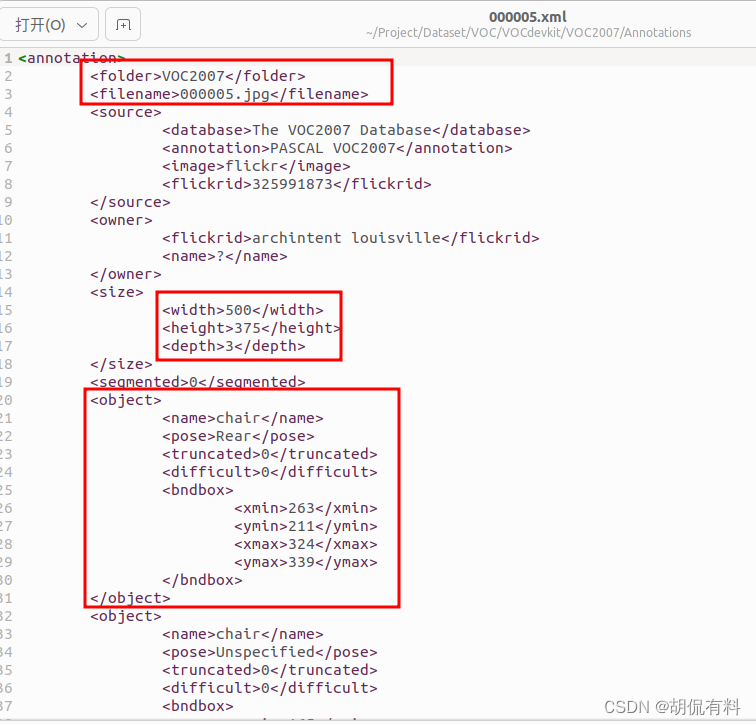
Annotations:
-
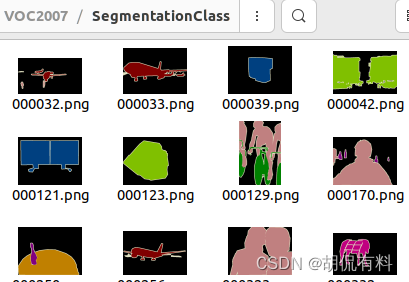
SegmentationClass:
-
SegmentationObject:
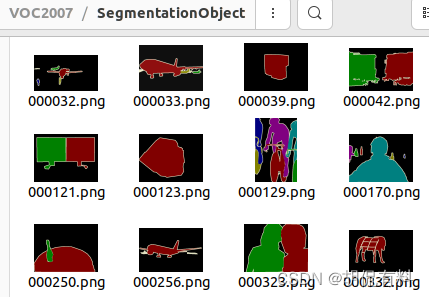
-
JPEGImages:
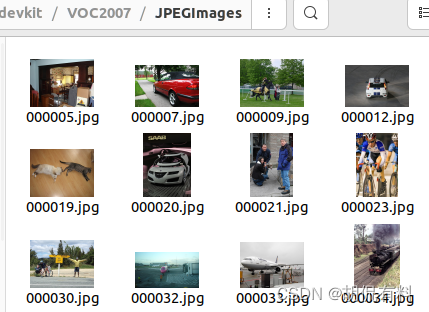
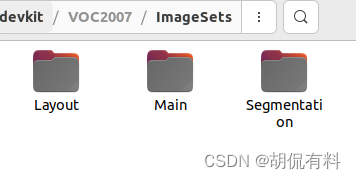
5. ImageSets:
- Main文件夹存放的是用于分类和检测的数据集分割文件,
- Layout文件夹用于 person layout任务,
- Segmentation用于分割任务
参考
[1] https://zhuanlan.zhihu.com/p/362044555
[2] https://blog.csdn.net/cengjing12/article/details/107820976
[3] https://blog.csdn.net/mzpmzk/article/details/88065416
[4] https://blog.csdn.net/qq_37541097/article/details/115787033
[5] https://www.cnblogs.com/gshang/p/12964606.html

















 8550
8550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











