







scale-Transfer Object Detection阅读笔记@skiery
原文翻译
摘要
尺度问题一直存在与物体检测的核心部分。在本工作总中,我们开发了一个新颖的Scale-Transferrable Detectino Network(STDN) (尺度变换检测网络)用于检测图片中的多尺度物体。传统的方法只是简单将图片预测和来自不同网络深度的多特征图进行对比,本文不同,所推出的网络模型嵌入了super-resolution层(在本工作也叫做尺度变换层/模型),可以通过多次尺度检测清晰的看到尺度间的相关性。
介绍
尺度问题一直是物体检测的核心。为了检测不同尺度的物理,最基本的策略就是用图像金字塔在不同尺度下去获得目标的特征。然而, 这种做法会大量的增加内存的占用和计算的复杂度,进而会影响物体检测的实时性。
近年来,卷积神经网路在计算机视觉任务(如image claasification图片分类,semantic segmentation语义分割,和物体检测)中取得了很大的进展。手工设计的特征已经被卷积神经网络计算获得的特征取代,极大的提高了物体检测的能力。Faster R-CNN用某层计算得到卷积特征映射(convolutional feature maps)来预测不同尺度和长宽比的候选区域(candidate region proposals)。

(a)只用单尺度特征进行预测;(b)使用高层和低层特征映射
(c)从不同尺度的特征映射进行预测;(d)本文的模型,可以直接潜入DenseNet去获得不同尺度的特征映射信息。
因为感受野(receptive field)在每一层中是固定的,所以固定感受野与自然图像中的不同尺度物体之间存在不一致。这可能会损害物体检测的行能。如图C,SD和MS-CNN使用来自CNN内不同层的特征映射来预测不同尺度的物体。浅层特征映射有用来检测小物体的小感受,深层特征映射用来检测大物体的大感受野。然而浅层特征映射所带的语义信息更少,所以该方法影响小物体的检测。FPN,ZIP和DSSD交叉使用所有尺度的特征映射。如图b所示,一个从高级到低级的结构使高层特征映射信息和低层的结合起来,在所有尺度下产生了更多的语义特征映射。然而,为了提高检测效果,特征金字塔必须小心的建立,并且需要添加额外的层去计算因为建立金字塔而需额外计算的损失。

Scale-Transferrable Detection Network(STDN) for etecting multi-scale objects in images
本文使用了DenseNet-169作为网络的基础。该图显示了DenseNet-169最后一个密集区域中的几层。密集块中每层的输出具有相同的高度和宽度。本文使用尺度转移层来获取用于检测小物体的高分辨率特征图,并使用合并图层来获得具有大感受野的特征图以检测大物体。 这些层可以直接嵌入到基础网络中,而且计算开销很小。 标度传输模块保证了探测器的实时性能。
为了获得高级多尺度语义信息映射,并且不影响检测器的速度,本文提出了尺度变换模型Scale-Transfer Module(STM)并且直接将其嵌入了一个DenseNet。DenseNet让模型在不使用卷积神经网络的情况下,获取更有价值的低级和高级特征信息。由于网络结果密集,DenseNet的功能比普通卷积特征更强大。STM由池化层和尺度变换层组成。池化层用来获取小尺度特征映射,尺度变换层用来获取大尺度特征映射。尺度变换层具有简单有效的特点,最初提出来用来解决图像超分辨率的问题,也有一些人用它来做语义分割。本文中用该层有效的扩展了物体检测中特征图的分辨率。
本文使用scale-Transfeerable模型建立了一个单步物体检测器Scale-Transferrable-Detection-NetWork(STDN)。上图展示了本文所提出检测器的模型结构。因为DenseNet中最后一个密块的最后一层有数量最多的通道,scale-transfer层通过压缩通道的数量(如图1)扩展了特征图的宽度和高度。该操作可以有效地减少下一个卷积层参数的数量。
STM天然与基层网络相适应并且能实现端到端的训练。本文认为STM有两个直接明显的长处。首先,很自然的结合了DenseNet的特征图和我们自己的低层物体检测特征和高层语义特征。本文可以证明该方法能提高物体检测的准确度。其次, STM仅由池化层和高分辨率层组成,不需要额外的参数和计算。实验结果说明了文中提出的框架可以准确的检测物体并符合实时性的需求。
相关工作
最先进的物体检测方法大都基于卷积神经网络。如,SPPnet,Fast R-CNN,Faster R-CNN,Faster R-CNN,R-FCN,YOLO,都使用卷积神经网络最顶层的特征去检测不同尺度的物体。然而,每层卷积网络都有一个确定的感受野,只用单独一层的特征去预测不同尺度物体不是一最佳选择。
进一步提高多尺度物体检测准确率的方法基本有三类。其一是用多层特征结合去检测物体。其二使用不同曾的尺度特征在各层去判断检测目标。最后一种是结合以上两种方法。
对第一种类型的方法,ION使用跳过池化、在多层提取信息的方法,最终使用各层结合起来的信息检测物体。HyperNet结合图像深、中、浅层特征生成规则检测目标。YOLO_V2把低分辨率特征通过层间传递集中到高分辨率的特征中再在顶部运行这个扩展特征检测映射。这些方法的基本观点都是去增强底层特征和高层特征的比较。
对第二种方法而言,SSD,MS-CNN和DSOD比较了从多个特征映射得到的检测去处理不同尺度的多个物体。例如,对小物体而言,使用浅层特征,对于大物体而言,使用深层特征。但由于语意信息的丢失,浅层网络特征会影响小物体检测的性能。
最后一类方法是同时使用以上两种方法。使用许多曾去预测不同尺度的物体,同事每个预测层的特征包含了不同深度特征的比较。FPN和TDM使用一个从上到下的结构建立高层语意信息特征映射。DSSD使用一个沙漏结构传递预测使用的信息。这些方法都增加了额外获取多尺度特征的层,因此而引入的误差不可忽略。
我们提出的方法时分类中的第三种,我们使用DenseNet去比较不同层,并且使用不同尺度模块去获取不同分辨率的特征映射。我们的模块可以在误差很小的情况下直接嵌入DenseNet网络中
3.STDN
该部分,我们首先介绍了我们特征提取网络组件的基础网络。我们使用DenseNet作为我们的基础网络。在每一个dense模块中,其特征映射作为接下来所有层的输入。最后一个dense模块的最后一层输出有最多的通道并且很适合做我们Scale-Transfer尺度变换层的输入,该层通过压缩通道数目扩展特征映射的长度和宽度。接着我们描述了scale-transfer模块生成不同尺度的特征映射。接下来,我们定义了整个物体检测、定位预测网络结构和网络训练的诸多细节。
3.1基本网络:DenseNet
本文使用Dense-169座位我们的网络基础来做特征提取,在ILSVRC CLSLOC数据集上做预训练。DenseNet是一个深度学习监督网络。在DenseNet的每个dense模块中,每层的输出包含了所有前面层的输出,因此混合了输入图像的低分辨率和高分辨率特征,非常适合做物体检测。由DSOD得到了启发,我们使用一个33的convolution layer和一个22的 mean pooling layer取代之前的输入层(77convolution layer,stride = 2后跟一个33的max pooling layer)。第一个卷积层的步进是2,其他的为1。三个卷积层的输出分64路。我们称这些层为"stem block"。表1详细描述了我们的网络结构。实验证明这种简单的替换可以有效地提高物体检测的准确率(见表3)。其中一个解释可能是因为原来的DenseNet-169层的输入层就已经因为两次连续的下采样丢失了许多信息。这会影响物体检测,尤其是小物体的检测。
3.2高效的Scale-Transfer模块

尺度问题一直是物体检测的核心,比较不同分辨率下不同特征映射得到的预测对于多尺度物体检测是有益处的。然而,如图2,DenseNet中最后一个dense模块,出了输出的通道数目不同,所有的输出都有相同的宽和高。如,当输入图片是300300的时候,DenseNet-169的最后一个dense模块分布为99.最简单的方法是用低层的高分辨率的特征图直接进行预测,像SSD的做法。然而,低水平的特征图缺乏物体的语义信息,这可能使物体检测表现变差。简化测试表现表中可见。
受到super-resolution方法的启发,为获取不同分辨率的特征图,本文提出了一个模块被称为scale-transfer模块。scale-transfer模块非常有效并且可以直接嵌入DenseNet中的dense block模块。为了获得强健的语义信息特征图,本文使用了DenseNet的网络结构,通过一系列的操作,直接把低分辨率的特征转换为高分辨率的特征。网络顶层的特征图同时具有低分辨率细节信息和高分辨率的语义信息,因此可以提高物体定位和检测的行能。

本文从最后一个Dense层获得不同大小的特征图。在scale-transfer模块中,我们使用平均池化层获得低分辨率的特征图。对于高分辨率的特征图而言,我们使用一个成为scale-transfer层的技术。
假设scale-transfer层输入向量的分布为H x W x C · R(平方),r是上采样参数。scale-transfer层中进行着一种元素周期性的重排。如图三所示,scale-transfer层通过压缩特征图所含通道数扩展了特征图的长度和宽度。
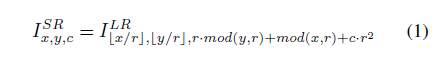
其中,I SR是高分辨率特征图,I LR是低分辨率特征图。与使用反卷积层时需要在卷积前先填0不同,scale-transfer层没有额外的参数和计算开销。我们将一个平均池化层和transfer-scale层合成为一个scale-transfer模块。将scale-transfer模块直接嵌入DenseNet可以获得六个不同尺度的特征图。接着使用这些特征图构建一个称为scale-transfer检测网络(STDN)的单步(one-stage)物体检测器。图二显示了输入为300*300时不同大小的六个特征图的尺度。
scale-transfer层可以有效地减少DenseNet中dense的最后一层通道数目,也可以减少参数和下一个卷积预测层的计算消耗。这可以提高检测器的速度。
利用DenseNet的优势,特征图可以同时具有低层次细节信息和高层次的语义信息。实验结果显示scale-transferrable检测器在准确率和检测速度上表现均很好。
3.3物体定位模块
STDN由基础网络和两个任务子网组成。其中基础网络主要做特征提取。第一个子网做物体分类,第二个子网做边框定位和回归。在前文中已经对基础网络的细节有所描述。接下来细化两个预测子网和训练对象。
3.3.1Anchor Boxes
本文将一系列定义好的anchor boxes通过scale-transfer模块和每个特征图相连接。anchor boxes的尺寸和SSD一样(金字塔状的特征图)。和DSSD一样,在每个预测曾我们使用[1.6,2.0,3.0]的层比例。Anchors对IoU大于门限0.5的区域进行匹配。剩下的的anchors视为背景。在匹配后,大部分预置的anchors时未匹配到东西的。我们使用负样本排除的方法保证正负样本的比例在3:1左右。
3.3.2分类子网
分类子网用来预测每个anchor属于某一类的可能性。它包含了一个11的卷积层和两个33的卷积层。每个卷积层前加一个batchnorm层和一个relu层。最后一个卷积层有K A个过滤器,其中K是物体的种类,A是每个预测区域中anchor的数量。分类的损失函数是softmax层基于多个种类置信度的softmax损失。
3.3.3边框回归子网
该子网用于回归抵消每个anchor box,使之可以更匹配真实的物体。边框回归子网和分类子网的大体结构相同,除了其中最后一个卷积层有4A个过滤器(并非K A个)。平滑L1损失函数用于定位的损失函数,边框损失函数仅用于正样本。
3.3.4训练目标
训练目标是将一个分类损失和定位损失混合的损失函数最小化:
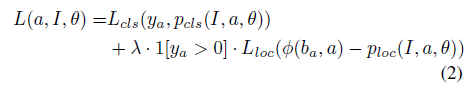
其中a是anchor,I是图片,theta是我们优化的参数。L cls是分类损失函数,L loc是定位损失函数,y a是类标签,等于0时没有相应的匹配类。p loc(I,a,theta)和p cls(I,a,theta)用来预测边框的编码和对应类。fai(b a,a)是一个对应anchor a的真实边框的编码。lambda是一个权衡系数。
3.3.5训练设置
我们的检测器是基于MXNet框架的。所有模型均使用SGD solver在NVIDIA TITAN Xp GPU上进行训练。我们使用了近似SSD的训练策略,包含了一个随机数据扩展和旋转,对于小物体的检测有很大的帮助。
实验
(略)(等做实验需要的时候再去翻阅~就翻译到这里吧)















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









