1.在ARM处理器中,如何实现独占访问内存?
- 1.linux提供了atomic_t的原子变量结构在实现独占访问内存,不同架构有不同的实现。
- 2.ARM使用ldrex和strex指令来保证中间执行的指令的原子性,指令后缀ex表示exclusive(独家的),不考虑原子性ldrex与ldr是一致的。
- 3.ARM处理器核心有Local monitor和Global monitor来实现ldrex和strex指令的独占访问。
2.atomic_cmpxchg()和atomic_xchg()分别表示什么含义?
- 1.atomic_cmpxchg(ptr, o, n),原子比较交换,如果ptr与o一致,就把n赋值给ptr,并返回ptr的旧值。
- 2.atomic_xchg(ptr, v),原子交换,将v赋值给ptr,并返回ptr的旧值。
- 3.atomic_cmpxchg()和atomic_xchg()在mcs锁的实现中起到非常重要的作用。
3.为什么spinlock的临界区不能睡眠(不考虑RT-Linux的情况)?
- 1.spinlock持锁在临界区睡眠,将会导致死锁,因为唤醒它的前提是进去临界区,但是锁被持有了,只能不断的忙等待,这将浪费大量cpu资源。
4.Linux内核中经典spinlock的实现有什么缺点?
- 1.经典spinlock在很多cpu争用时,会导致严重的不公平性及性能下降。当该锁释放时,事实上有可能刚刚释放该锁的cpu马上又获得该锁的使用权,这是因为刚刚释放锁的cpu的L1 cache中存储了该锁,它比别的cpu更快获得该锁,这对忙等待很久的cpu时不公平的。
5.为什么 spinlock 临界区不允许发生抢占?
- 1.如果在spinlock临界区中主动睡眠让出cpu,就可能导致一个并发访问的bug,因为中断返回时会去检查抢占调度,这会带来两个问题。
- 2.一是抢占调度相当于持有锁的进程睡眠,这违背了spinlock锁不能睡眠和快速执行的原则。
- 3.二是抢占调度进程也有可能会申请spinlock锁,那么会导致发生死锁。
6. Ticket-based 的 spinlock机制是如何实现的?
- 1.我们知道经典spinlock使用slock来记录持锁的1表示未被持锁,0或负数表示持锁。
- 2.ticket-based在spinlock基础上将slock拆分为next和ower两个变量。next表示申请持锁时分配到的号牌,ower表示当前持锁者的号牌。
- 3.类似于银行排队拿号next就是排队号数,ower就是正在办理业务的号数。当没有人办理业务时,next,ower都为0。A客户拿了排队号next=0后,排队机自动加1(next++),因为ower为0,就开始办理业务(持锁)。此时B客户来到排队机拿到next=1,排队机自动加1(next++),而办理业务ower为0,说明锁被持有,开始等待。当A客户办理完业务后ower加1(ower++),此时B客户可以办理业务了(持锁)。
7.如果在 spin_lock()和spin_unlock()的临界区中发生了中断,并且中断处理程序也恰巧修改了该临界资源,那么会发生什么后果?该如何避免呢?
- 1.在spinlock的临界区发生中断:系统暂停进程转而去执行中断。
此时该临界区时持锁状态。 - 2.中断处理程序也恰巧修改了该临界资源:这时需要获取锁才能修改临界资源,而该临界区已经处于持锁状态,这将会导致中断出现忙等待或者睡眠wfe睡眠状态。而中断上下文出现忙等待和睡眠状态是致命的。
- 3.那么会发生什么后果?:锁的持有者因为被中断打断而无法及时释放锁。而中断处理程序一直处于忙等待,这将导致死锁的发生。
- 4.该如何避免呢?:linux内核提供了spinlock的变种spin_lock_irq()函数在获取spinlock时关闭本地cpu中断,来避免该问题。
- 5.只是关闭本地cpu中断,那别的cpu依旧会响应中断,那会不会导致死锁呢?答案是不会,因为cpu0关闭本地中断后,持有锁后会很快释放,而cpu1在响应中断后忙等待也会很快过去而获得锁。
8.与spinlock相比,信号量有哪些特点?
- 1.信号量相比于spinlock,可以允许有多个锁的持有者。
- 2.信号量相比于spinlock,可以允许待持锁进程进入睡眠,并用链表进行管理。
- 3.信号量相比于spinlock“短”,“快”,“加锁时间短的场景”,主要的应用场景适用于一些场景复杂,加锁时间长的应用场景,例如内核于用户空间复杂的交互行为等。
9.请简述信号量是如何实现的。
- 1.信号量实现使用了三个函数sema_init(struct semaphore *sem, int val),down_interruptible(struct semaphore *sem),up(struct semaphore *sem)
- 2.sema_init(struct semaphore *sem, int val)用于信号量结构体初始化,包括.lock初始化一个spinlock锁。.count允许进入临界区的内核执行路径个数,通常为1。.wait_list初始化链表用于存储信号量上睡眠的进程。
32 static inline void sema_init(struct semaphore *sem, int val)
33 {
34 static struct lock_class_key __key;
35 *sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val);
36 lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0);
37 }
75 int down_interruptible(struct semaphore *sem)
76 {
77 unsigned long flags;
78 int result = 0;
79
80 raw_spin_lock_irqsave(&sem->lock, flags);
81 if (likely(sem->count > 0))
82 sem->count--;
83 else
84 result = __down_interruptible(sem);
85 raw_spin_unlock_irqrestore(&sem->lock, flags);
86
87 return result;
88 }
89 EXPORT_SYMBOL(down_interruptible);
204 static inline int __sched __down_common(struct semaphore *sem, long state,
205 long timeout)
206 {
207 struct task_struct *task = current;
208 struct semaphore_waiter waiter;
209
210 list_add_tail(&waiter.list, &sem->wait_list);
211 waiter.task = task;
212 waiter.up = false;
213
214 for (;;) {
215 if (signal_pending_state(state, task))
216 goto interrupted;
217 if (unlikely(timeout <= 0))
218 goto timed_out;
219 __set_task_state(task, state);
220 raw_spin_unlock_irq(&sem->lock);
221 timeout = schedule_timeout(timeout);
222 raw_spin_lock_irq(&sem->lock);
223 if (waiter.up)
224 return 0;
225 }
226
227 timed_out:
228 list_del(&waiter.list);
229 return -ETIME;
230
231 interrupted:
232 list_del(&waiter.list);
233 return -EINTR;
234 }
- 4.在来看与down对应的up函数,如果第183行信号量链表为空则信号量计数sem->count直接加1。否则调用__up函数来唤醒在信号量链表中睡眠的进程。
178 void up(struct semaphore *sem)
179 {
180 unsigned long flags;
181
182 raw_spin_lock_irqsave(&sem->lock, flags);
183 if (likely(list_empty(&sem->wait_list)))
184 sem->count++;
185 else
186 __up(sem);
187 raw_spin_unlock_irqrestore(&sem->lock, flags);
188 }
189 EXPORT_SYMBOL(up);
256 static noinline void __sched __up(struct semaphore *sem)
257 {
258 struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list,
259 struct semaphore_waiter, list);
260 list_del(&waiter->list);
261 waiter->up = true;
262 wake_up_process(waiter->task);
263 }
10.Linux内核已经实现了信号量机制,为何要单独设置一个Mutex机制呢?
- 1.虽然信号量conut计数等于1可以实现类似mutex机制,但是mutex的语义相对信号量要简单轻便一些。
- 2.在锁争用激烈的测试场景下,Mutex比信号量执行速度更快,可扩展性更好。
- 3.Mutex数据结构的定义比信号量小。
11.请简述MCS锁机制的实现原理。
- 1.mcs锁为了解决锁争用恶劣环境下cpu频繁cacheline bouncing导致整体系统性能下降而设计的。
- 2.mcs锁的核心思想是每个锁的申请者只在本地cpu的变量上自旋,而不是全局的变量。
- 3.mcs锁本质上是一种基于链表结构的自旋锁,mcs机制在内核的具体实现是OSQ锁。
- 4.mcs锁核心原理是当发现持有锁者正在临界区执行并且没有其他优先级高的进程要被调度(need_resched)时,那么当前进程坚信锁持有者会很快离开临界区并释放锁,因此预期睡眠等待不如乐观地自旋等待,以减少睡眠唤醒的开销。
12.在编写内核代码时,该如何选择spinlock,信号量和 Mutex?
- 1.在中断上下文中毫不犹豫地使用spinlock
- 2.如果临界区有睡眠、隐含睡眠的动作及内核API,应避免选择spinlock。
- 3.在信号量和mutex中除非碰到以下mutex的约束中的某一条,否则都优先使用mutex。
13.什么时候使用读者信号量,什么时候使用写者信号量,由什么来判断?
- 1.由rw_semaphore结构的.count表示读写信号量的计数。kernel将count值分成两个域,bit[0-15]为低字段域,表示正在持有锁的读者或者写者的个数;bit[16-31]为高字段域,通常为负数,表示有一个正在持有或者pending状态的写者,以及睡眠等待队列中有人在睡眠等待。
- 2.count值含义介绍:
14.读写信号量使用的自旋等待机制(optimistic spinning)是如何实现的?
- 1.读写信号量目前只有写信号量使用了自旋等待机制。
- 2.读写信号量在rwsem_optimistic_spin来实现自旋等待机制,使用OSQ锁,不断的判断是否有写者锁释放,期待活跃写者尽快离开临界区。并且判断是否有更高优先级是进程要调度,如果则退出自旋等待机制,写者进入进入睡眠状态。
15.RCU相比读写锁有哪些优势?
- 1.RCU全称read-copy-update,是Linux内核中一种重要的同步机制。
- 2.RCU目标是使读者锁没有同步开销,不需要使用额外的锁,原子操作指令和内存屏障,即可畅通无阻地访问。
16. 请解释 Quiescent State 和 Grace Period。
- 1.Grace Period(宽限期)。GP有生命周期,有开始和结束之分。在GP开始那一刻算起,当所有处于读者临界区的CPU都离开了临界区,也就是都至少发生了一次Quiescent State(静止状态),那么认为一个GP可以结束了。GP结束后,RCU会调用注册的回调函数,例如销毁旧数据等。
- 2.Quiescent State(静止状态)。在RCU设计中,如果一个CPU处于RCU读者临界区中,说明它的状态是活跃的;相反,如果在时钟tick中检测到该CPU处于用户模式或idle模式,说明该CPU已经离开了读者临界区,那么它是静止状态。在不支持抢占的RCU实现中,只要检测到CPU有上下文切换,就可以知道离开了读者临界区。
17.请简述RCU实现的基本原理。
- RCU记录了所有指向共享数据的指针的使用者,当要修改该共享数据时,首先创建一个副本,在副本中修改。所有读访问线程都离开读临界区之后,指针指向新的修改后的副本的指针,并删除旧数据
18.在大型系统中,经典RCU遇到了什么问题?Tree RCU又是如何解决该问题的?
- 1.经典RCU在超大型系统中会遇到性能问题例如1024个CPU的系统中,经典RCU在判断是否完成一次GP时采用全局的cpumask位图,1024个CPU,cpumask就有1024个比特位。每个cpu在GP开始时要设置位图中对应的比特位,在GP结束时要清除位图对应的比特位,那么cpumask就需要spinlock锁来保护位图,这将导致该锁争用异常激烈。
- 2.Tree RCU针对该问题设计了一套树形的RCU机制,Tree RCU把两个CPU分成1个rcu_node节点,假设有4个cpu就有两个rcu_node节点,另外还有一个rcu_node节点来管理上述两个节点,我们称之为根节点或者0节点。每二个节点只需要两个比特位的位图就可以管理各自的cpu或者节点。每个节点都有各自的spinlock锁来保护相应的位图。
- 3.假设4个cpu都经历过一个QS状态,那么4个CPU首先在Level0层级的节点1和节点2上修改位图。对于节点1或者节点2来说,只有两个CPU来竞争锁,这比经典RCU上的锁争用要减少一半。当Level0上节点1和节点2上位图都被清除干净后,才会清除上一级节点的位图,并且只有最后清除节点的CPU才有机会去尝试清除上一级节点的位图。因此对于节点0来说,还是两个CPU来争用锁。整个过程都是只有两个CPU去争用一个锁,比经典RCU实现要减少一半。这类似于足球比赛,四强进入半决赛,始终是两支队伍竞争,只有赢的队伍才能进入决赛。
19.在RCU实现中,为什么要使用ULONG_CMP_GE()和 ULONG_CMP_LT()宏来比较两个数的大小,而不直接使用大于号或者小于号来比较?
- 1.ULONG_CMP_GE()和 ULONG_CMP_LT()宏原型如下:
#define ULONG_CMP_GE(a, b) (ULONG_MAX / 2 >= (a) - (b))
#define ULONG_CMP_LT(a, b) (ULONG_MAX / 2 < (a) - (b))
- 2.在RCU结构体中有一些无符号类型的变量,例如gpnum和completed是一直增长的,因此这里要很小心地处理溢出问题。假如直接使用大于,小于的方式比较,若a=0,b=0xffff_ffff,用普通的方法比较应该是b>a,但是a应该是0xffff_ffff+1得到的即a是溢出才等于0的,所以a>b才符合预期。
- 3.我们在来看ULONG_CMP_GE(),ULONG_MAX / 2相当于最大的无符号数右移一位成最大有符号数即0x7fff_ffff,此时如果a-b为正数则返回true,a-b为负数则返回false。此时a=0,b=0xffff_ffff代入式子是符合预期的。
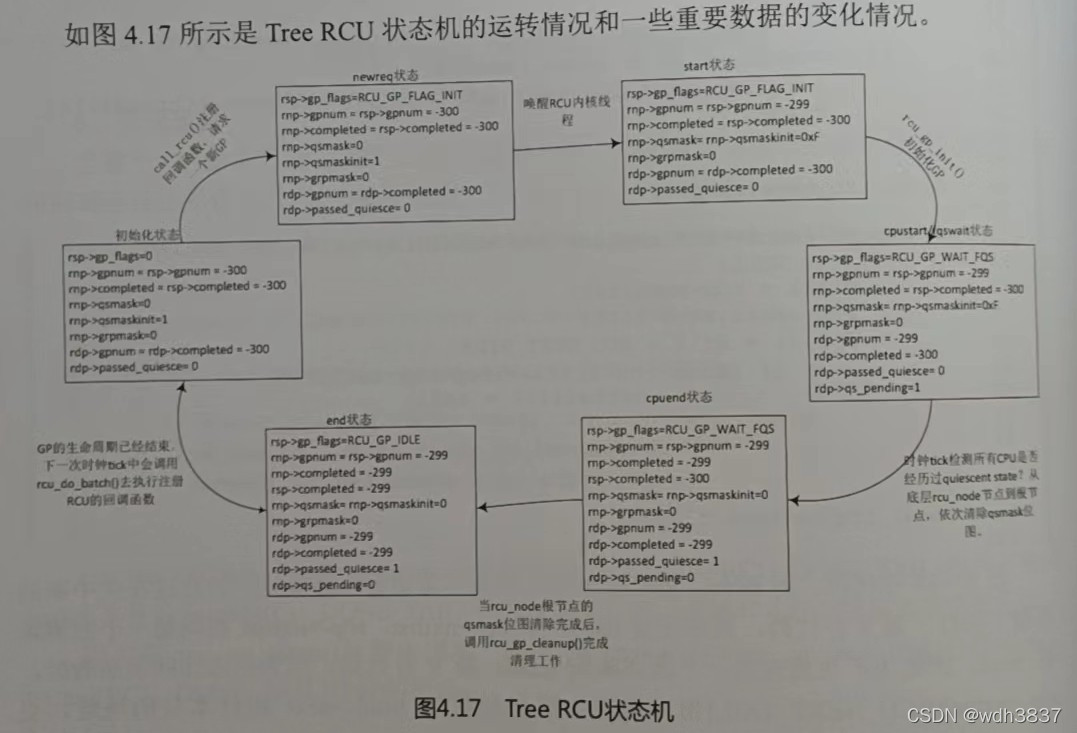
20.请简述一个Grace Period的生命周期及其状态机的变化。
- 1.初始化状态-》newreq状态:call_rcu()注册回调函数,请求一个新GP。
- 2.newreq状态-》start状态:唤醒RCU内核线程rcu_gp_kthread。
- 3.start状态-》cpustart/fqswait状态:rcu_gp_init()初始化GP。
- 4.cpustart/fqswait状态-》cpuend状态:时钟tick检测所有CPU是否经历过quiescent stats?从底层rcu_node节点到根节点,依次清除qsmask位图。
- 5.cpuend状态-》end状态:当rcu_node根节点的qsmask位图清除完成后,调用rcu_gp_cleanup()完成清理工作。
- 6.end状态-》初始化状态:GP的生命周期已经结束,下一次时钟tick中会调用rcu_do_batch()去执行注册RCU的回调函数。
21.请总结原子操作、spinlock、信号量、读写信号量、Mutex和 RCU等Linux内核常用锁的特点和使用规则。
| 锁 | 特点 | 使用规则 |
|---|
| 原子操作 | 使用处理器的原子指令,开销小 | 临界区数据是变量、比特位等简单的数据结构 |
| 内存屏障 | 使用处理器内存屏障指令或GCC的屏障指令 | 读写指令时序的调整 |
| spinlock | 自旋等待 | 中断上下文,短期持有锁,不可递归,临界区不可睡眠 |
| 信号量 | 可睡眠的锁 | 可长时间持有锁 |
| 读写信号量 | 可睡眠的锁,可以多个读者同时持有锁,同一时刻只能有一个写者, 读者和写者不能同时存在 | 程序员必须界定出临界区时读/写属性才有用 |
| mutex | 可睡眠的互斥锁,比信号量快速和简洁,实现自旋等待机制 | 同一时刻只有一个线程可以持有mutex,由持有锁着负责解锁,即同一个上下文中解锁,不能递归持有锁,不适合内核和用户空间复杂的同步场景 |
| RCU | 读者持有锁没有开销,多个读者和写者可以同时共存,写者必须等待所有读者离开临界区才能销毁相关数据 | 受保护资源必须通过指针访问,例如链表 |
22.在KSM中扫描某个VMA寻找有效的匿名页面,假设此VMA恰巧被其他CPU销毁了,会不会有问题呢?
23.请简述页锁PG_locked的常用使用方法。
24.mm/map.c文件中的page_get_anon_vma()函数中,为什么要使用rcu_read_lock()? 什么时候注册RCU回调函数呢?
25.在mm/oom_kill.c的select_bad_process()函数中,为什么要使用rcu_read_lock()?什么时候注册RCU回调函数呢?























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









