







 本文概述了大模型的发展历程,从统计学习到Transformer的兴起,介绍了大语言模型如ChatGPT和国内模型如文心一言。文章讨论了大模型的涌现能力、应用领域、伦理安全问题,并列举了几个知名开源和闭源模型。
本文概述了大模型的发展历程,从统计学习到Transformer的兴起,介绍了大语言模型如ChatGPT和国内模型如文心一言。文章讨论了大模型的涌现能力、应用领域、伦理安全问题,并列举了几个知名开源和闭源模型。
Datawhale开源社区组织的11月《动手学大模型应用开发》课程笔记
项目地址:GitHub - datawhalechina/llm-universe:
在线阅读地址:https://datawhalechina.github.io/llm-universe/
文档链接:动手学大模型应用开发
(一)发展历程
- 20世纪90年代,统计学习方法,难以处理复杂的语言规则;
- 2003年,使用神经网络模型(Bengio)学习复杂的语言规则,堪称开山之作;
- 2017年,Transformer架构的神经网络模型(Attention is All You Need),如今已成为主流框架;
参数量越大,模型能力越强,俗称“涌现”能力,进入大模型时代;
(二)基本概念
大语言模型(Large Language Model,LLM),用于理解和生成人类的语言,参数量达到十亿甚至千亿。
- 国内大模型:ChatGLM、文心一言、通义千问、讯飞星火等;
- 国外大模型:ChatGPT、GPT-4、PaLM、LLaMA等;
(三)应用和影响
- 典型应用场景:写文章、写心得、写摘要、讲故事、做翻译、搞规划;
- 未来发展潜力:引发人们思考通用人工智能(AGI),让机器人像人一样思考,提供人们的工作效率;
(四)大模型的涌现能力(emergent abilities)
即量变引起质变,随着模型参数量的不断增长,直到突破某个临界值,模型的能力产生了飞跃,从而可以解决复杂问题,这个能力主要表现在以下三个方面:
(1)上下文学习:只需在给定任务时为模型添加少量的示例或者背景知识,模型即可理解上下文并给出相应的输出结果,这个过程不需要额外的训练或者参数更新,达到零样本或者少样本的目的;
(2)指令遵循:经过指令微调过的模型,具备很强的泛化能力,即使模型没有见过某些指令,一样可以完成特定的任务;
(3)逐步推理:大模型通过采用“思维链(CoT)”的推理策略,在提示词中添加处理任务的中间步骤,逐步得到最终的答案。普遍认为,这种能力可能是在训练数据集中增加了代码;
(五)大模型的地位
2021年,李飞飞等百名学者联名发布了200多页的综述文章 ,将大模型成为基础模型或者基座模型(foundation model)。在海量无标注数据上进行预训练,得到的模型可以适用于大量的下游任务。这种方式可以极大地提高开发效率,缩短开发周期,减少人力投入,值得大力推广。
(六)为什么大模型突然火了?
ChatGPT发布之后,第一次让人类感受到人工智能在互动交流、文案撰写方面达到了跟人类接近的水平,也因此吸引了大量的人进行尝试,2个月用户就破亿,成为全球用户最快破亿的产品,而且日活量也已突破1000万。任何人都可以通过对话交流的方式实现自己的需求,极大的降低了技术的门槛,人们也会更加相信钢铁侠中的“贾维斯”离自己不远了。
(七)大模型的特点
- 参数量大:数十亿甚至上千亿;
- 预训练和微调:大模型需要先在无标签数据上进行预训练,这个过程会使得大模型学会复杂的语言规则,具备通用的知识;然后在有标签数据上进行微调训练,使得大模型可以适应特定的任务,具备专业的知识;
- 上下文感知:使大模型具备了理解复杂指令的能力,在阅读理解、文本生成和情境理解等各个方面都表现出色;
- 多语言支持:训练数据中包括了多个语种的数据,也使得大模型具备了多语言的互译能力,可以实现跨文化和跨语言的应用;
- 多模态支持:一些大模型已经可以支持文本、图像、声音、视频等多个模态的学习,大模型的应用场景也会越来越丰富;
- 涌现能力:通常表现为参数量越大,能力越强,可以处理更复杂的任务;
- 多领域应用:某人说,所有的产品都值得用大模型重新做一遍,大模型应用已经在我们的生活中得到了广泛的应用;
- 伦理和安全:大模型存在“幻觉”现象,也就是一本正经的胡说八道,生成很多看起来没啥问题,但实际并不存在的信息;也可能会存在生成有偏见的、有害的信息;用户上传的数据也可能存在被窃取的风险,隐私得不到保障;
(八)常见的大模型
1. 闭源大模型(未公开源码)
(1)GPT系列(OpenAI公司发布,从GPT-3开始就不Open了)
ChatGPT:2022年11月,输入支持32K,知识截止日期未2021年9月,在插件的支持下,进一步扩展了应用能力;
GPT-4:2023年3月,支持多模态输入,预计参数量达到1.8万亿,是GPT-3(1750亿)的10倍以上;
GPT-4 Turbo:2023年11月7日,进阶版的GPT-4,输入扩展到128K,相当于300页的书,知识更新到2023年4月;
最新研究:红队评估(red teaming)和可预测扩展(predictable scaling),前者为了缓解幻觉现象,后者可以仅用少量参数完成结果预测从而减少计算量;
(2)Claude系列
由 OpenAI 离职人员创建的 Anthropic 公司开发,包括 Claude 和 Claude-Instant 两个版本,输入长度未9000个token,参数量预计860.1亿;
Claude 的上下文窗口从 9K token 扩展到了 100K token(Claude 2 支持200K,但是还未发布);
Claude 2 可以生成 4000 个 token 的连贯文档,相当于大约 3000 个单词;
Claude 通常用于将长而复杂的自然语言文档转换为结构化数据格式,例如 JSON、XML、YAML、代码和 Markdown 等格式;
(3)PaLM系列
- 谷歌在2022年4月发布,基于Pathways机器学习系统搭建,在780B字符数据集上训练而来,包含8B、62B、540B三种参数规模,以及Med-PaLM医疗大模型和PaLM-E多模态大模型;
- 2023年5月发布了PaLM 2,参数量为340B,训练数据是PaLM的5倍左右,可以处理100多种语言任务,包含Gecko、Otter、Bison和Unicorn等多个系列,不同系列的模型参数量不一样,适用场景也不一样,Bard是基于PaLM 2开发的对话应用;
突出贡献: - 训练数据大小/模型参数量最优的缩放比例为1:1,可以达到最佳性能,过于任务3:1更佳
- 训练数据非纯英文语料,包含百种语言的文档、书籍、代码,在多语言任务上表现更佳;
(4)文心一言
基于百度文心大模型的知识增强的大语言模型,2023年3月开启内测,参数量达到2600亿,算法与框架的优化使得效果和效率提升明显,训练速度优化了3倍,推理速度优化了30多倍;
(5)讯飞星火
科大讯飞与2023年5月6如发布,6月9日升级为V1.5版本,8月15日升级为V2.0版本,10月24日发布了V3.0,最新版本具备多模态能力,可以实现图像描述、图像立即、虚拟人合成等功能,具备1700亿参数;
2. 开源大模型(已公开源码)
(1)LLaMA:Meta开源,参数量从7B到70B,LLaMA 65B与PaLM-540B相媲美,使用与GPT相同的decoder-only架构,从Pre-normalization、SwiGLU 激活函数、RoPE 位置编码三个方面进行了升级,提升了模型的收敛速度和性能,减少参数量和计算量,使模型具备更强的泛化能力。
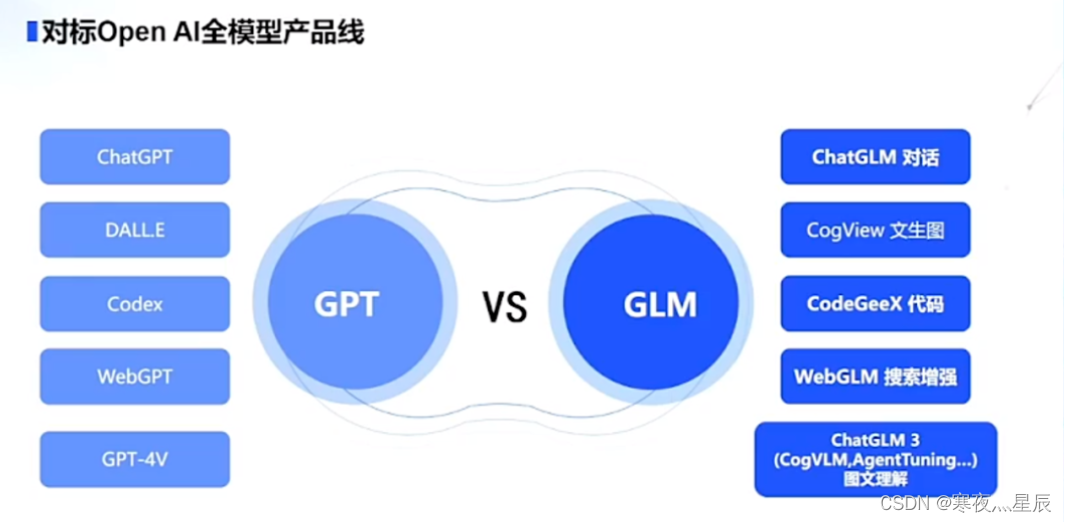
(2)GLM:由清华大学和智谱AI合作研发。2023年6月发布ChatGLM 2,2023年发布了ChatGLM 3,支持工具调用(Function Call)、代码执行(Code Interpreter)和Agent任务等复杂场景;通过使用FlashAttention和Multi-Query Attention等技术,提升了上下文长度(32K)和推理速度,减小对显存的占用。
(3)通义千问,阿里巴巴在2023年4月发布,包括7B和14B两个版本。
(4)Baichuan,百川智能发布,包括7B和13B两个版本,支持4096输入长度,采用rotary-embedding的位置编码方案。Baichuan 2是新一代开源的大模型,10月30日发布了Baichuan2-192K,可以一次处理35万个汉字。
(九)什么是LangChain
- 为各种大模型提供通用接口,简化使用大模型开发程序的流程,实现数据感知和环境互动。
- 作者是 Harrison Chase,2022年10月开源备受关注,2023年完成了1000万美元的种子轮融资,在此之后获得了红衫领投的2000万至2500万美元融资,估值达到2亿美元。

- 核心组件
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。
- 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;

















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









