







注:拉到最后有视频版~
论文链接:https://arxiv.org/abs/1910.11626v1
文字版
今天我给大家讲两篇论文,一篇是关于 GAN 的模式崩溃可视化的,一篇是关于如何用用 pix2pix 做人脸编辑的
先来看第一篇论文,这是 iccv2019 的论文,作者是 MIT 和港中文的

我会从以下三个方面来进行本次的讲述

背景
首先是背景,我先简单解释下什么叫模式崩溃,简单来说就是比如我训练集有猫和狗,理论上来说 GAN 会学到猫特征和狗特征,然后生成时候就会生成猫图片和狗图片,如果发生了模式崩溃,就会发生生成的只有狗图片,猫特征被丢掉了
背景呢就是说对这个问题在 gan 中是很常见也是很严重的
动机
第二是动机,因为有这个问题,我们就很想知道,GAN 到底不能生成什么东西,现在的一些工作提供的解释方法比较少,就算是 GAN 中常用的评价指标 fid 和 is,也只是在特征的层面评价了训练分布和生成分布之间的一个距离,我们就想拿到一个更具象的,分析出来 GAN 到底不能生成什么

研究目标
研究的目标呢,就是模式崩溃的一个可视化

方法
对于研究的方法,作者在分布的层面和实际例子的层面进行了模式崩溃的可视化
先讲分布层面,为了对比训练分布和生成分布,作者提出了用分割统计的方法,用一个别人训好的分割网络,这个网络能分割出 300 多类不同的类别,比如土地,教堂,人,树,天空等等,然后把分割出来的每一列的面积记下来

具体来说,作者在 LSUN
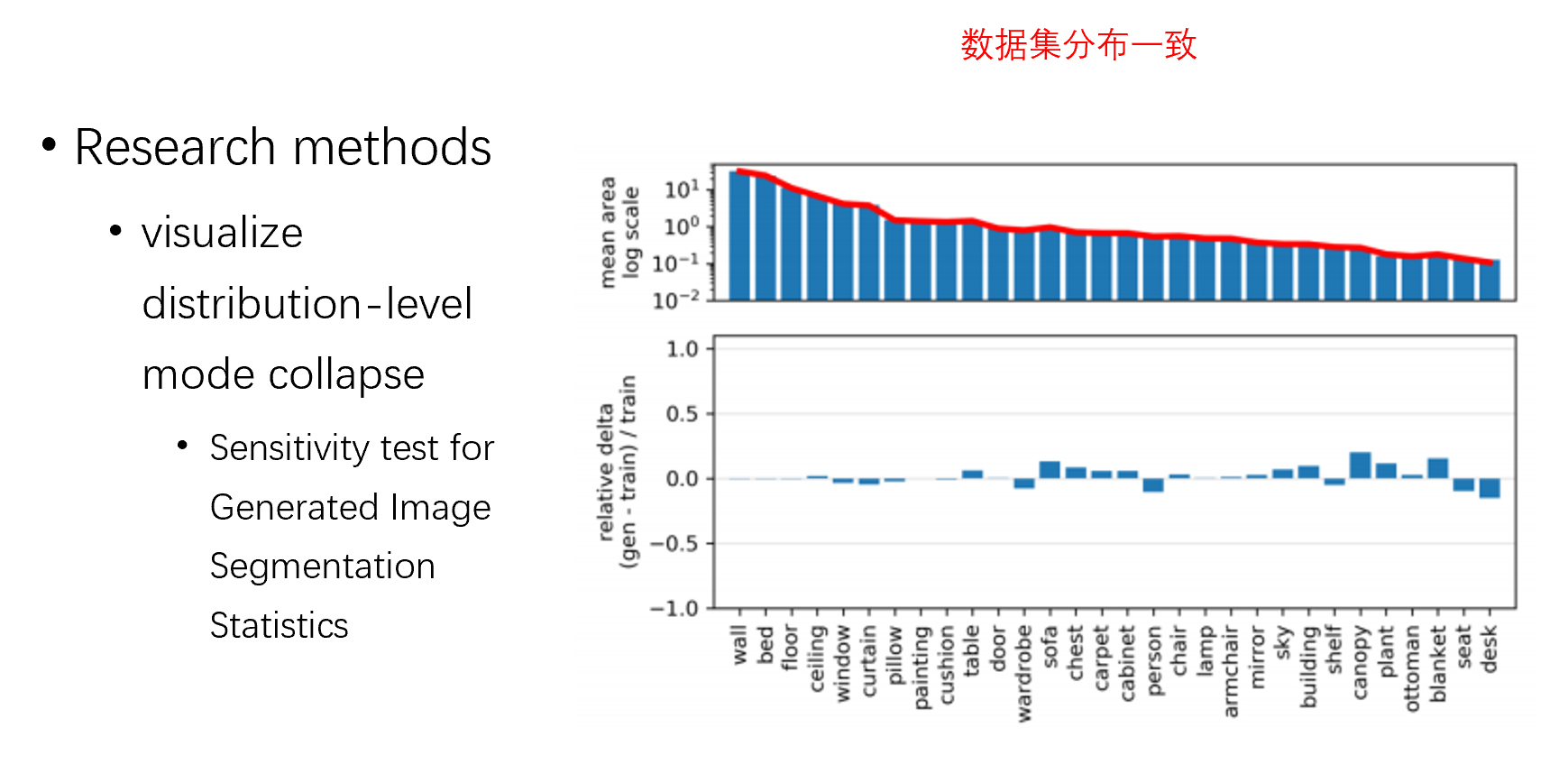
卧室的数据集上训了一个模型,然后让他随机生成 1w 的图片,同时在训练集中选 1w 的图片,分别做分割,统计出如墙,床,地板等不同类别的面积,上面的图代表不同类别在总面积中的比例,下面的表代表训练图片和生成图片的面积对比,正值代表生成的面积大于训练集面积,负值代表生成的面积小于训练集面积,也就是模式崩溃
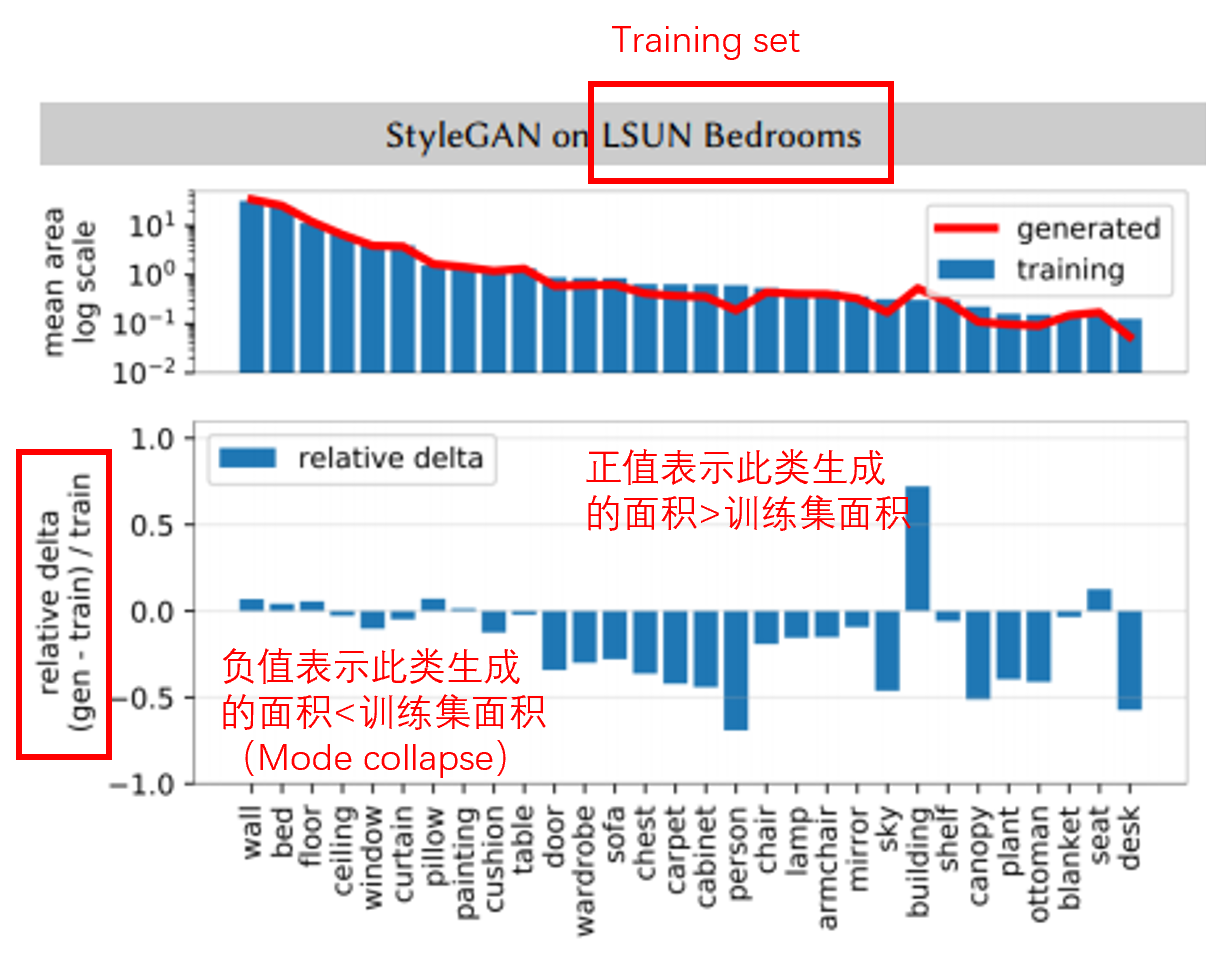
此时可能有人要问了,是不是训练集中分布就是不均衡的,导致 GAN 没有办法好好学习,我们从训练集中随机采样,然后做上面相同的实验,发现分布几乎是没有差别的
然后,对现在比较流行的一些 gan 做对比,发现 stylegan 是最不容易出现模式崩溃的,其他的 gan 都崩溃得很严重
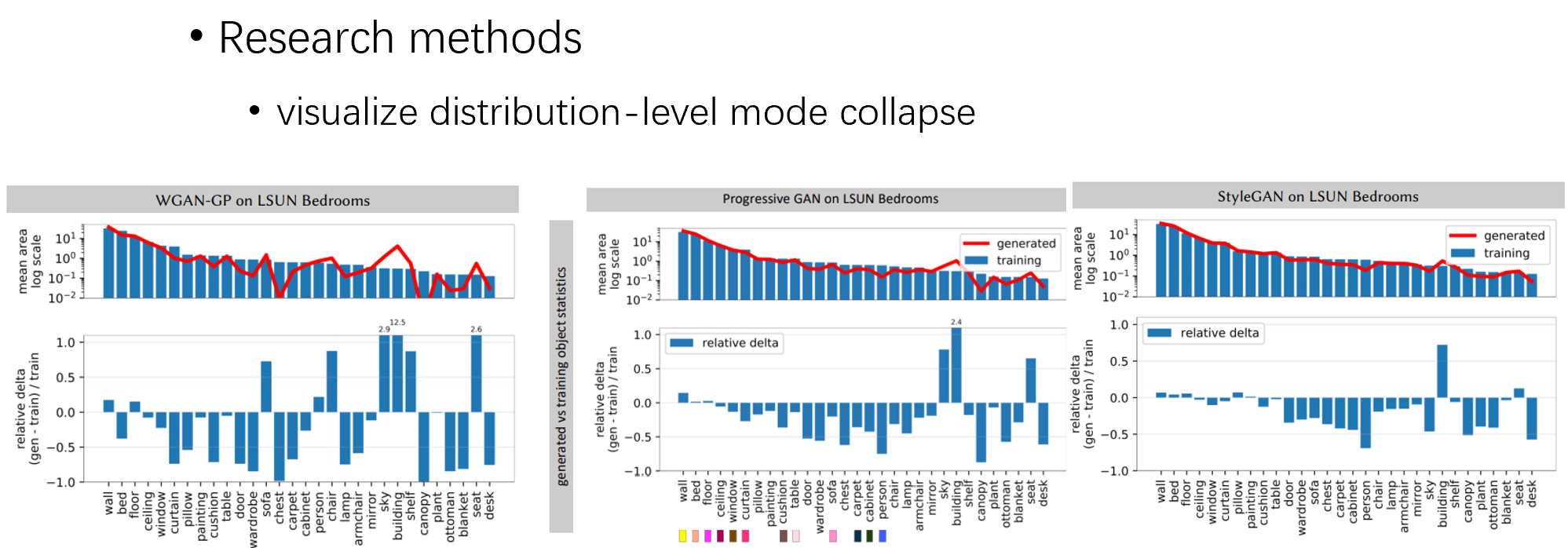
这里,我们对不同 gan 分割的面积做一个统计量,文章提出了 FSD 评价指标,g 是生成的数据,t 是训练数据,统计他们分割面积的均值和总数
也是发现 stylegan 的效果最好

到这里,分布层面的可视化就做完了,下面讲实际例子的模式崩溃可视化
为了解决这个问题,我们需要拿到一对数据,即真实的图片和 GAN 空间生成的图片,但是问题来了,gan 生成是随机的,没法保证生成的图片一定和我手里这张真实的图片一致,所以我们在这里要定义一个可逆问题
一般来说,gan 是不可逆模型,所以为了找到由生成器生成的图片,且与真实图片的保持尽可能近的距离,用数学语言来说就是,
但是问题来了,对于很深的网络,这样的逆推问题是很难处理的,作者在这里把逆推问题分解了,分解为处理一个较浅的网络逆推问题

具体来说,首先,我们需要学习一个逆推网络,我们把他成为 encoder,注意,这里的 E 和 G 是完全对称的结构。同时,我们把生成器 G,encoder E 都分解为小 g,和小 e。同时前面说了,我们先处理一个浅网络逆推问题,所以我们其实先是在 r 上处理
然后我说一下训浅网络 encoder 时候的 loss,文中定义了左 loss 和右 loss,左 loss 是先逆推一层,再推理一层,得到一个 L1 范数。右 loss 是先推理一层,再逆推一层的 L1 范数,目的是在网络的每一层减少损失。这样训练好之后,得到了浅层的 encoder,然后通过 finetune,得到整个的 encoder
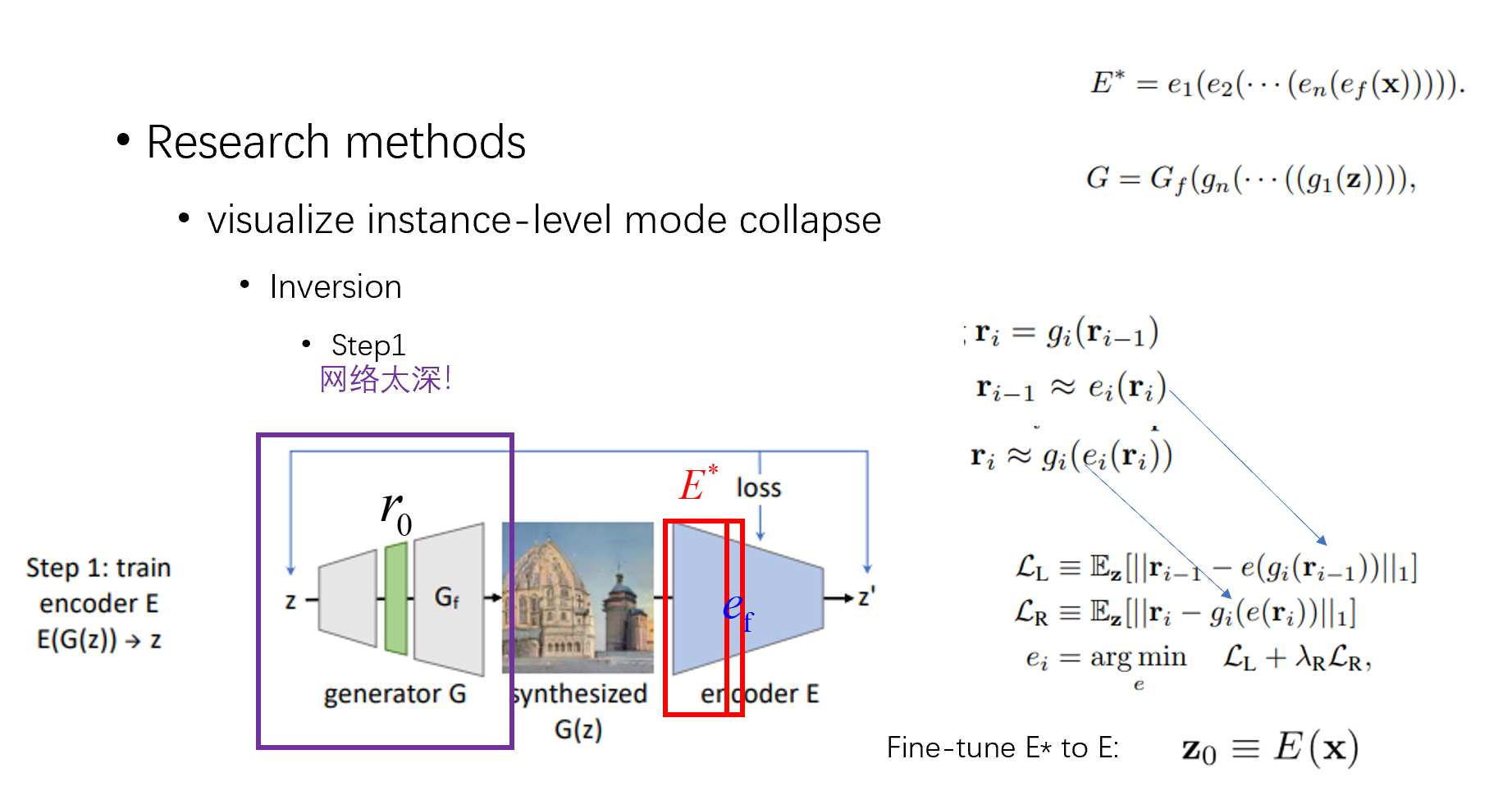
对于第二步,需要做一个推理,比如我要逆推这张图片,我通过 encoder,然后再经过一个浅层生成器,得到 r0
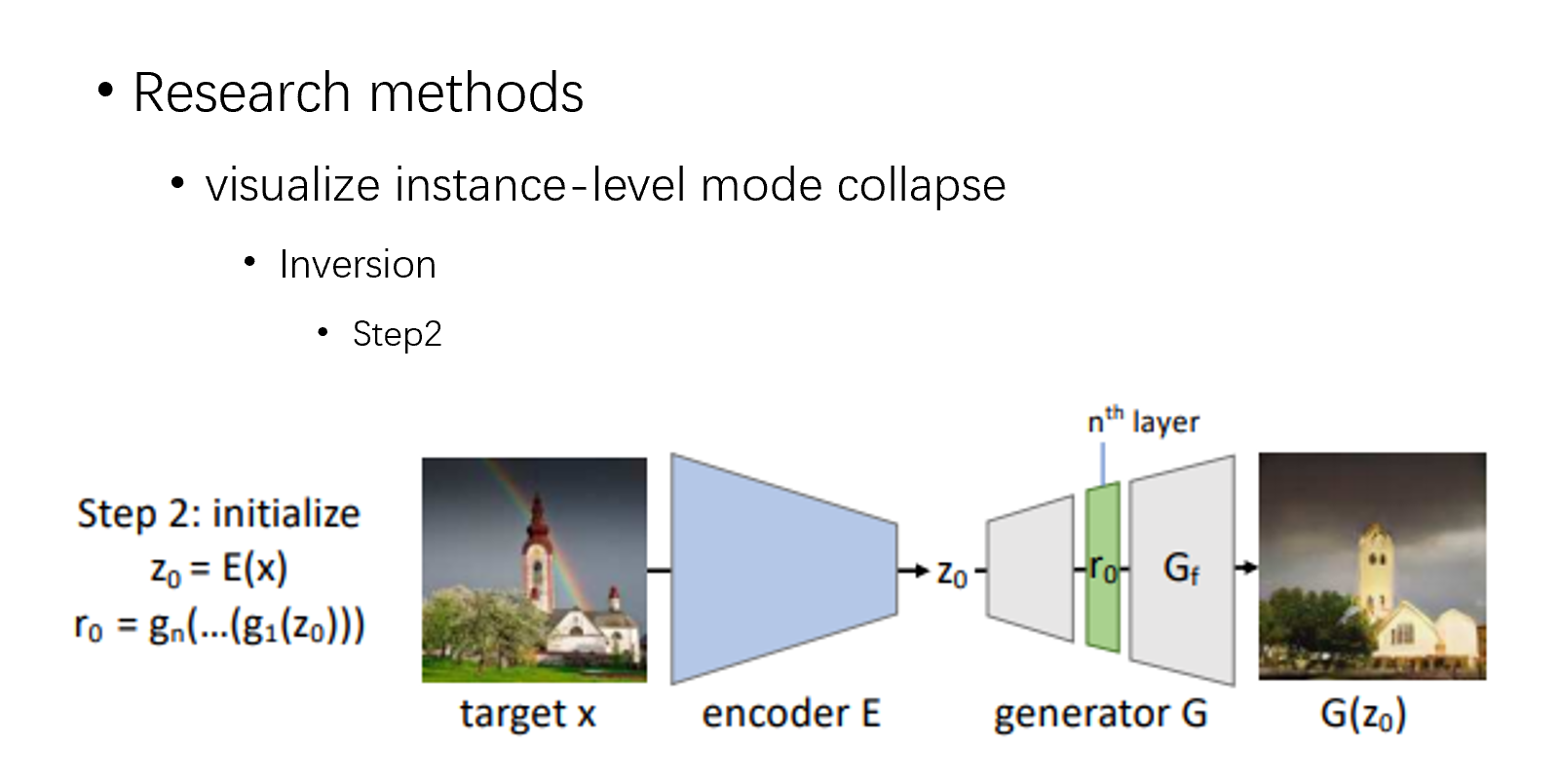
此时,最老的办法是是通过梯度下降去调 r 本身,但是网络是非凸的,很容易陷入到局部最优值,所以这并不是一个好办法,文章在这里提出,不更新网络参数,也不更新 r 本身,在推理的每一层结构上加一个小扰动,学习这个扰动的参数,这样能有效避免局部最优

实验
然后呢,是一些具体的实验
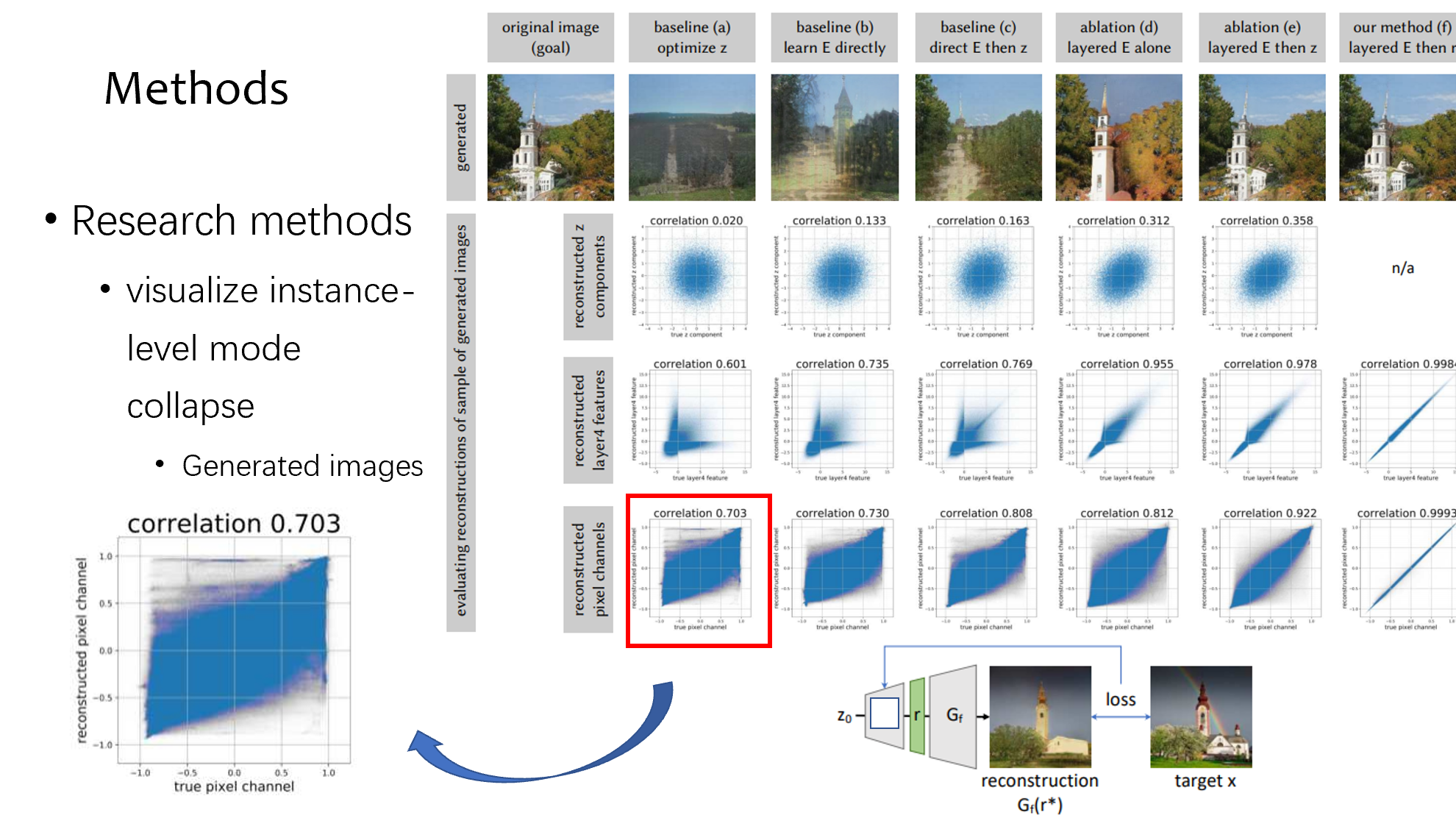
我先介绍下对比的方法,a 的意思就是直接用梯度下降暴力调 z,b 的意思是训一个 encoder 做图像的逆推,c 是先用 encoder 做图像逆推,然后梯度下降调 z,d 是用上面说的左 loss 右 loss 的方式训 encoder,e 是用上面说的左 loss 右 loss 训 encoder 后再用梯度下降调 z,f 是就是全部的方法加在一起,训浅层的 encoder,然后不调 z,学扰动参数
下面的数据对比的是逆推前的图片和逆推后的图片在 z,特征和重建的 pixel 方面的相关性,可以看到 f 的效果是最好的,相关性最强
同时这个也证明了,encoder 已经效果非常好,接近于能完美无损逆推
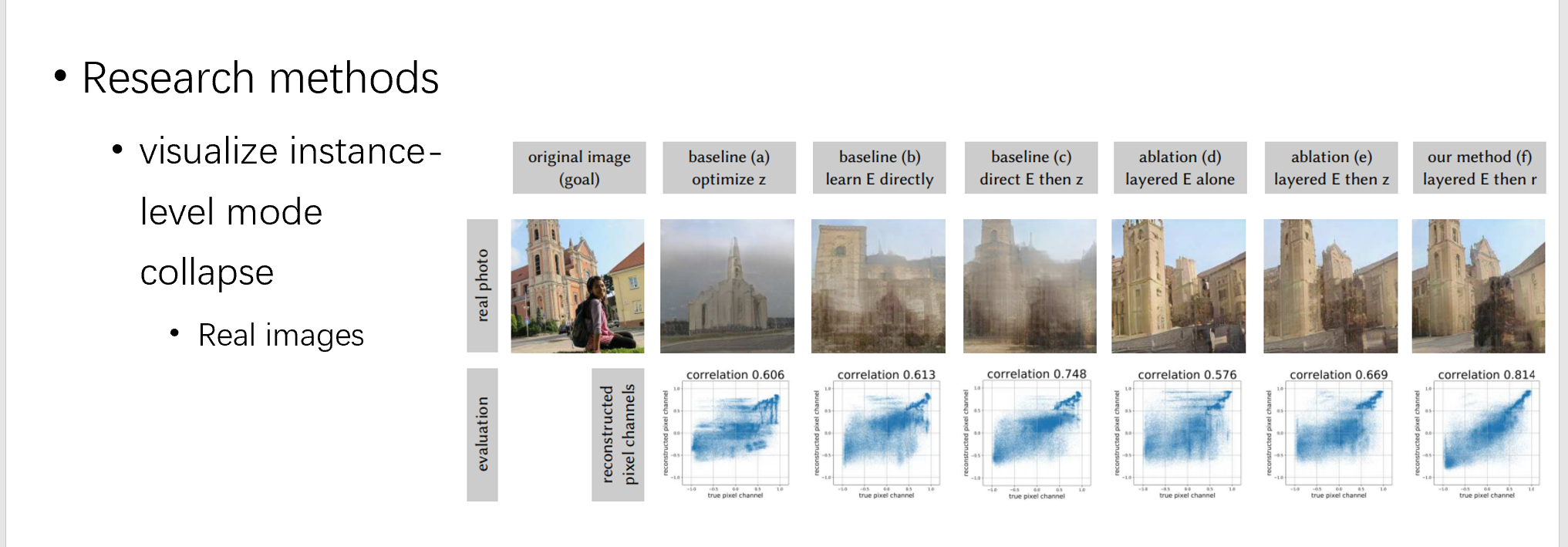
然后在真实的图片上测试,因为真实的图片没有 z 和特征的 gt,故只对 pixel 做比较
我们在这里可以看到,对于真实的图片,pixel 的差距还是比较大的,同时又因为上面的实验已经证明 encoder 已经效果非常好,所以可以说明这个模式崩溃是 gan 本身导致的,比如在教堂数据集上训练的模型,就不能生成人
再多看一些实验,可以发现,在教堂数据集上训出来的模型,在训练集中和其他数据中都能很好的生成大部分的教堂属性,但是人、牌子等无法生成,说明 gan 在这些类别发生了模式崩溃

结论
然后是文章的结论,结论就是文章提出了一个可视化模式崩溃的方法,同时也证明了的确 gan 在学习时候的确会丢掉一些类别

不足
最后的是一些不足,第一,对于 gan 为什么拒绝学习某些特征,仍然无法解释,第二,如何强迫 gan 去学习这些他原本拒绝学习的特征,第三是为什么不同的网络会导致不同的模式崩溃

视频版
Seeing What A GAN Cannot Generate论文分享(ICCV2019)
















 2147
2147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









