






摘要
近年来,深度神经网络在视觉任务上取得了不错的发展,但是超高的计算量对内存和计算都带来了压力,尤其是要移植到移动设备上时。近年来模型压缩和加速也取得了很大的进展,我们主要分为四个方面:1.参数剪枝和量化;2.低阶分解;3.转移/压缩卷积滤波器(仅仅针对CNN);4.知识蒸馏,后面我们再叙述一些现在比较成功的方法,比如动态网络和随机深度网络。
简介
许多模型虽然有很好的性能,但是由上亿的参数组成,需要在GPU上训练好几天。
参数剪枝和量化是通过移除不重要的参数或者参数中不重要的位数,可以加速运算并防止过拟合,可以用于训练中,或者用于已经预训练好的模型,其中剪枝可以带来正则化的效果;
低阶分解是通过矩阵分解评估参数的信息丰富度;
转移/压缩卷积滤波器减少参数空间,节省参数存储和计算,仅适用于从头开始训练;
知识蒸馏是学习一个蒸馏模型,是一个模仿原输出的更紧凑的模型。
以上这些方案都是彼此独立的,某两种方案可以用于同一个模型。
下表是对以上四种方案的总结:
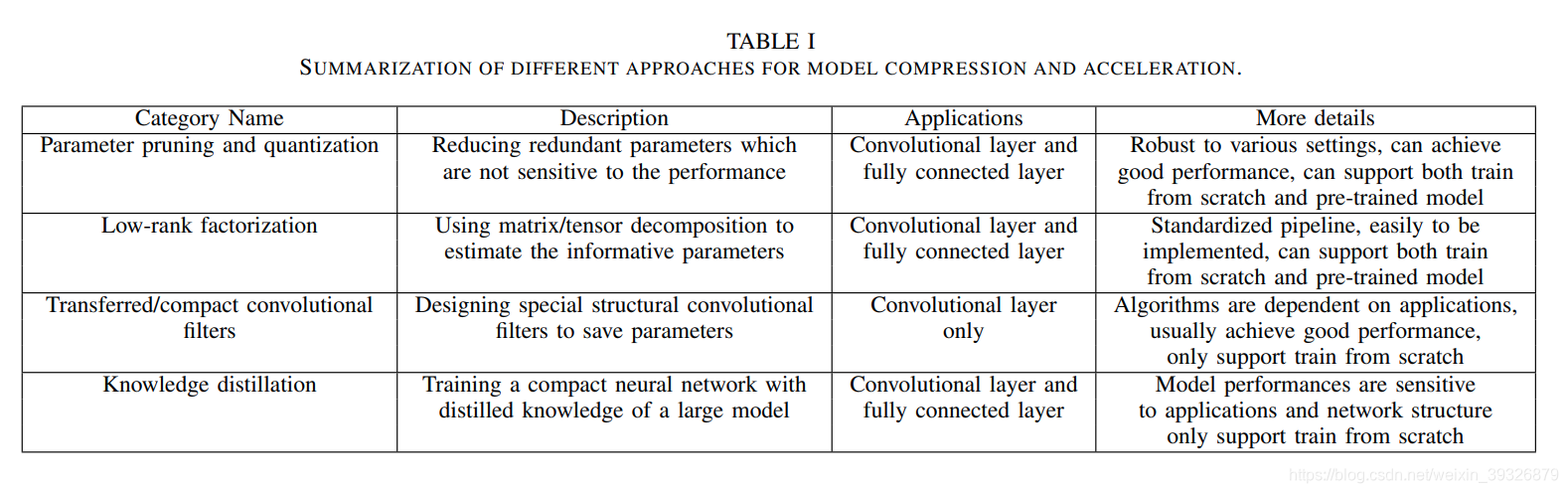
剪枝及量化
这类技术可以分为三小类:
量化和二值化
量化成8bit能够有效地加速,并且精度没有太大损失;
以下是使用剪枝、量化、霍夫曼编码三种不同方法的示意图:
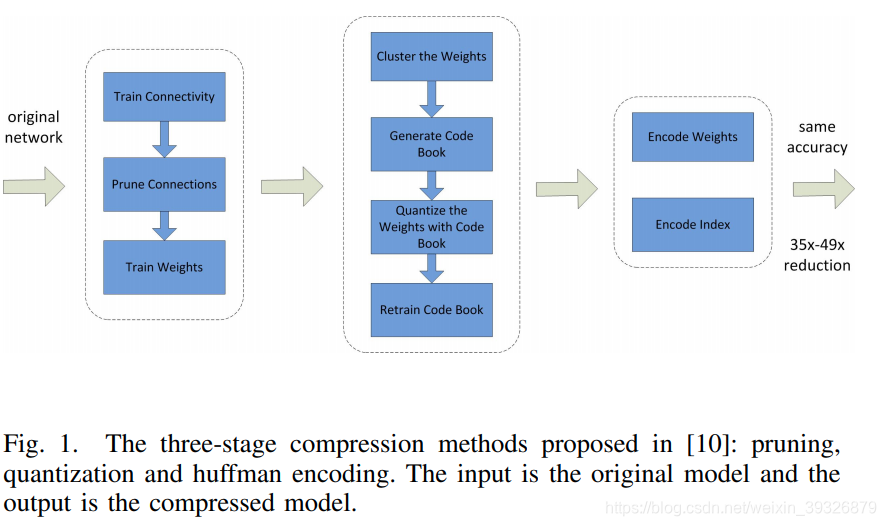
上图的工作比单独量化的效果还要更好,利用Hessian参数可以衡量网络参数的重要性。修剪减少了需要编码的权重数量,量化和霍夫曼编码减少了用于对每个权重编码的比特数。对于大部分元素为 0 的矩阵可以使用稀疏表示,进一步降低空间冗余,且这种压缩机制不会带来任何准确率损失。这篇论文获得了 ICLR 2016 的 Best Paper。
还有用单个位去表示参数的,就是二值化网络,比如BinaryConnect [12], BinaryNet, XNOR 。A systematic study in [15] showed networks trained with back propagation could be resilient to specific weight distortions, including binary weights.
二值化网络的精度比较低,尤其是对大型的CNN网络,比如Googlenet.二值化仅仅基于简单的矩阵近似值,没有考虑到网络的精度损失。
为了解决这个问题,“Loss-aware binarization of deep network中的工作提出了一个近端对角Hessian近似的牛顿算法直接降低了二进制权重的损失。 “Neural networks with few multiplications,” “Deep learning with low precision by half-wave gaussian quantization,”这两篇论文对二值化的精度损失有了很大的改善;
剪枝
早期所应用的剪枝方法称为偏差权重衰减(Biased Weight Decay),其中最优脑损伤(Optimal Brain Damage)和最优脑手术(Optimal Brain Surgeon)方法,是基于损失函数的 Hessian 矩阵来减少连接的数量。他们的研究表明这种剪枝方法的精确度比基于重要性的剪枝方法(比如 Weight Decay 方法)更高。这个方向最近的一个趋势是在预先训练的 CNN 模型中修剪冗余的、非信息量的权重。
加正则化让网络更稀疏。可以在每层卷积、甚至通道数上加上正则项(l1 or l2),构成group-sparse regularizer,然后按照l1 or l2的排序去掉不重要的参数。
作者说修剪需要迭代的次数很多,而且需要人为设置一些参数,而且作者说剪枝后只能减小所占内存,并不能加速太多。
结构化矩阵
该方法的原理很简单:如果一个 m×n 阶矩阵只需要少于 m×n 个参数来描述,就是一个结构化矩阵(structured matrix)。通常这样的结构不仅能减少内存消耗,还能通过快速的矩阵-向量乘法和梯度计算显著加快推理和训练的速度。
这种方法的一个潜在的问题是结构约束会导致精确度的损失,因为约束可能会给模型带来偏差。另一方面,如何找到一个合适的结构矩阵是困难的。没有理论的方法来推导出来。因而该方法没有广泛推广。
很奇怪,结构化矩阵网上并没有找到相关资料。
低秩分解(low rank factorization)
所谓的低秩分解,就是将卷积核进行分解,也是用更少的参数来描述,采用两个K1的卷积核替换掉一个KK的卷积核(decompose the K convolutions into two separable convolutions of size 1 × K and K × 1),从这个角度来说的话,深度可分离卷积也是低秩分解。,但是,其也存在以下不足:
1.若卷积核没有更低的秩,则无法进行分解;
2.即使是低秩的,压缩之后精度受损,需要re-training
卷积核分解一般使用SVD进行分解,可以加速计算,同时精度不会有太大损失。
关于低秩分解具体一点的内容,参照:https://blog.csdn.net/weixin_39326879/article/details/107800238
迁移/压缩卷积滤波器
这里太晦涩,没有搞懂。
知识蒸馏
所谓的迁移学习,就是指现在一个大的数据集上训练好的模型,作为预训练的模型加入小数据集的训练。知识蒸馏就是指先学习一个大规模的网络,然后让大规模的网络教小网络,所谓的教,就是将大网络的输出也一定程度上作为小网络的输出目标。
知识蒸馏的概念最早的提出在Hinton发表的《[Distilling the Knowledge in a Neural Network],作者认为开发时和部署时的模型应该是不一样的,开发时的模型应该大网络,精度高,部署时应该是运行速度快、节约资源的小网络。一个普遍的认为模型学习到的东西存储在模型的参数当中,这些参数不容易轻易删减,从另外一个角度考虑,VGG 学习出来的分类网络,作为网络的输出,作为真值的那一类自然概率很高,但是其他分类的概率虽然很低,但也不是为0,譬如输入货车的图片,分类为垃圾车的概率肯定要比苹果高,也就是网络可以学习到物体之间的相似度。
算法示意图如下:
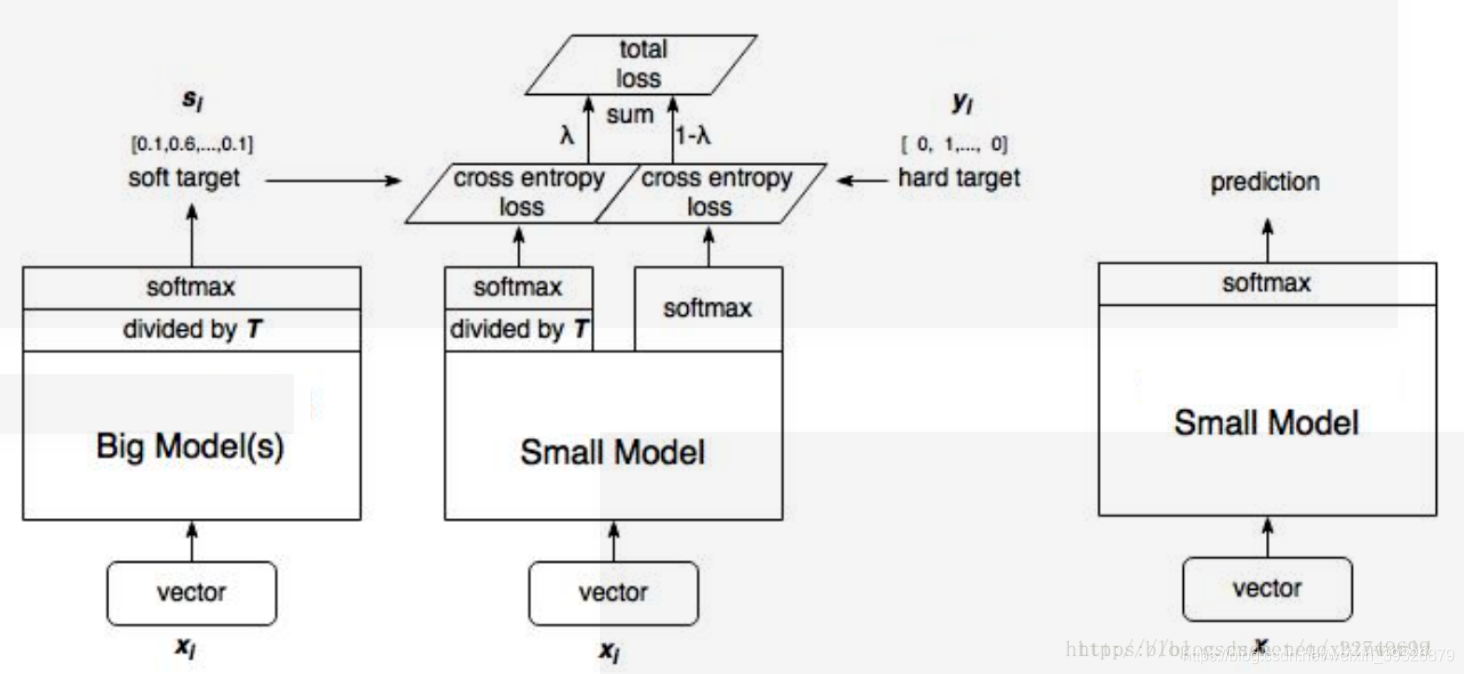
1、训练大模型:先用hard target,也就是正常的label训练大模型。
2、计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
3、训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
4、预测时,将训练好的小模型按常规方式(右图)使用。
我们希望模型在真实环境的效果能够达到我们的预期。也就是模型的泛化能力要好。也就是对于没有看到过的情况也能够预测。这些泛化能力就隐藏在非真值的预测概率中。怎样让小模型学习大模型的泛化能力呢?非真值的概率很小,怎样放大其影响呢,运用以下公式将非真值的影响扩大。:
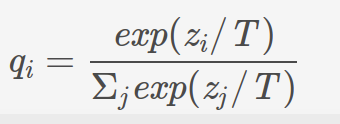
原始的label为hard target,soft target是大模型的预测输出,hard target 包含的信息量(信息熵)很低,soft target包含的信息量大,拥有不同类之间关系的信息
我们可以先训练好一个teacher网络,然后将teacher的网络的输出结果q作为student网络的目标,训练student网络,使得student网络的结果p接近q,因此,我们可以将损失函数写成 :
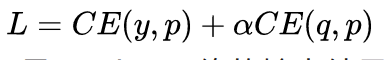
这里CE是交叉熵(Cross Entropy),y是真实标签的onehot编码,q是teacher网络的输出结果,p是student网络的输出结果。
其实也就是:
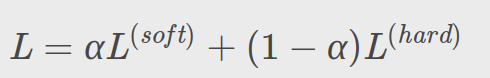
基于知识蒸馏的方法能令更深的模型变得更加浅而显著地降低计算成本。但是也有一些缺点,例如只能用于具有 Softmax 损失函数分类任务,这阻碍了其应用。另一个缺点是模型的假设有时太严格,其性能有时比不上其它方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









