







不需建模的策略评估
先复习需要建模的方法 动态programming:我们需要model,P,R
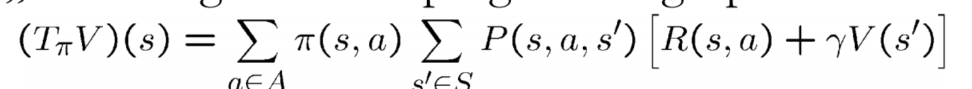
无需建模的:
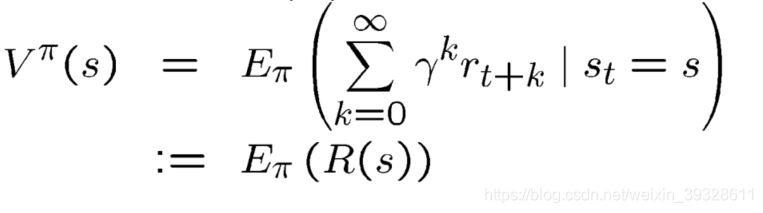
R(s)累计的瞬时reward 其期望为
V
π
(
s
)
V^{\pi}(s)
Vπ(s)
V π ( s ) V^{\pi}(s) Vπ(s)的估计
不用模型计算R(s)
采用从s开始的N trajectories有的reward:R1,R2,R3…
Monte Carlo 方法
V(s)的近似值为1/N Rk的和 ,近似期望
估计值收敛到实数期望,variance收敛到0,方差很大
通过迭代平均来完成 很浪费
- 有first-visit (现在研究的)是重复出现的state只记一次,
- every-visit 则不然
用MC估计最佳策略
估计Q 而不是V
通过MC评估,策略迭代选择better策略来改善,如果无限次还没完成评估则没有收敛
直接使用Q->用Q的贪婪action
对于非贪婪action则要用软策略
策略随时间改变,则没有收敛
优点:
- 无需建模
- 在非马尔科夫事件中变现更好
缺点: - 每个state需要遍历多次
- slow
- 未使用state之间的dependences
TD方法
Temporal Differences
改善MC方法的缺点:学习快速,可以证明收敛
无需模型学习
是本课程的首个真正的RL
采用Rk来估计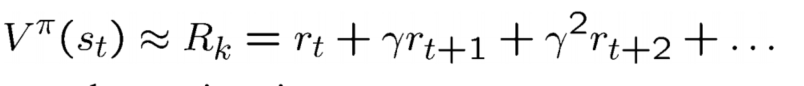
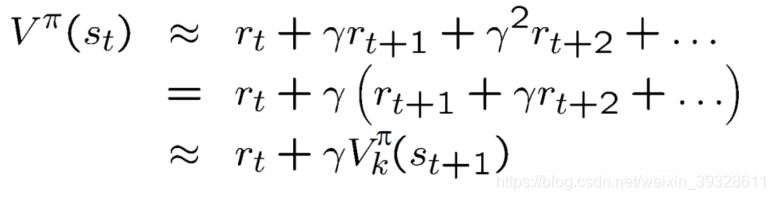
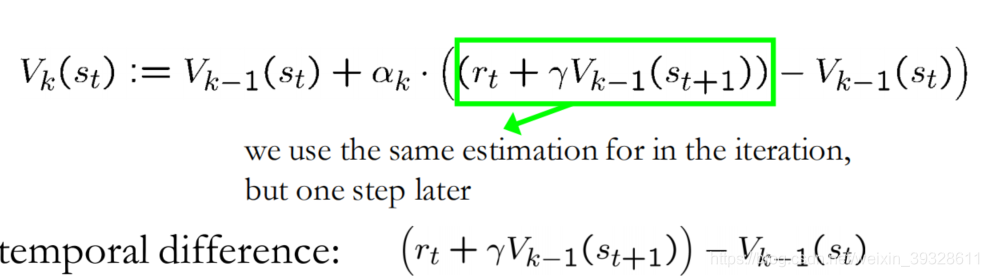
优点:无需建模,无需等到episode结尾,variance小
总结















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









