







四个阶段
自然语言是复杂的符号(词,短语,句子)系统 比ordinary符号更多的内部结构, 以下四层:
- phonological,individual sounds,书写语言,符号,字母;(最低)词素
- morphological,morphemes级别,最小意思语言单元,或者组成词;
- syntactic,词组成句子
- semantic,meaning级,(前三个都不涉及meaning,只是sign),例如语言符号的表示
以上四种linguistic sign不全面,
传统的语义不涉及非文字的,上下文依赖的意思成分,这都留给语用学(pragmatics);
discourse analysis(篇章分析):分析关系,在比句子大的单元(段落,整个对话等)。
例如,字母为phonological,字母组合为morphological,词组成句子为syntactic,最后是语义结构。
语法
依赖语言符号(sign),定义更重要的概念:
语言是一组符号,语法包含:一组signs,语言的词典(lexicon)和有限的操作使一个sign映射到另一个;
语法生成语言,当操作了一定数量次数的语法在他的词典上;
语法操作分为 上一章说的四个部分,同时进行;也有一些严格在morphology和syntax或者只是syntax。
描述语法
语言的中心目标是描述语法生成自然语言:
explicitly,通过描述字典和定义operation生成语言元素;
implicitly,通过提供已经由语法生成的例子表示集合(带有morphology,syntactic标签)。
解析和生成(语法相关的任务)
1 parsing 解析:
- 描述是否一系列手写字符属于给定语法生成的语言:是否包含语言词汇,well-formed和有意义;
- 定义音韵,语法,语义结构根据手写字符,由给定语法生成的语言。
使大部分的NLP task能通过解析text输入和根据特定的语法生成他们的表示结构;用结果分析作为特征为以后的处理;
传统的NLP pipeline就是解析pipeline for一个或多个语法。每个成分生成输入表示结构的一部分
2 生成 Generation:
- 无条件的:生成语法语言元素(实践上没用)
- 有条件的:生成满足一定条件的语法语言元素(有意义,chatbot)
传统pipeline的处理人任务
1 形态和语法:
句子层面:
- tokenization,得到word 边界
- 句子 splitting
子结构:
- 形态分析,uncover subword结构
语法结构层面:
- 部分标签
- 深浅语法解析
2 语义
- 定义 entity recognition
- word sense 去歧义
- coreference resolution/ entity linking
- 语义角色标签(浅语义解析)
- 深度语义解析
pipepline task
tokenization:
1
切分输入字符系列,给tokens分配类型,分成word-like 单元
不仅有词,还有标点,emoticons,不是词但时对分割有用的单元
表明这些分割是特定类型的实例组成vocabulary。(大小写属于同一个type)
什么算做一个token?
task and model-dependent(一些标点不相关,一些相关)
2 分配类型和归一化
tokenization确定token类型的过程中归一化,忽略大小写,
归一化方法:
- 改正typos,
- 标准化数字或日期表示方式
- 标点(!!->!)
更radical 的策略包含分配所有的数字表述或者字典没有的都为一个type. 对于tokenization的挑战,不仅依赖方法,还依赖输入的书写,语言,domain,noise(typos)欧洲语言的缩写,数字表示,一词多义
句子分割
分割输入字符为一些句子
- 挑战是句子的interdependence和token segmentation
- 不正确的或者缺失的标点
形态学
1
最小的有意义单元,word包含一些morphemes(词素)
- bound/affixes->affixes可被替换,bound词素(前后缀)只能和其他词素一起组词;
- free/roots-> free词素可以独立作为word,root是词最有意义的内容,大部分的root都是free的。
affixes可以分为词尾的(ing)和派生的(able)
2 词干和lemma
次干包含主要部分(太粗鲁),在所有变形的词中的base部分,有时候不是有意义的词(produc)
lemma相反,是个完整的词,是在所有的变形词中不发生变形的词(produce)
3 形态学分析任务
- 确定一个str 是不是well-formed word
- stemming-确定stem
- lemmatization-确定lamma
- 形态学tagging-给输入贴标签根据变形的语法信息(apples-plural)
- 形态学分割-分割输入词到不同的词素
- 完整形态学分析-分割到不同的词素并归类(根据类型和语法信息),通常包含lemmentization
4 形态学分析挑战
- 歧义/上下文依赖
- 复合词(两三个简单词组成)
- 形态丰富的语言(相似的)
PoS tagging
- part of speech 根据基本的语法角色归类(名词动词…)
- PoS类别是上下文依赖的
open和closed PoS 类别:
- closed:不变的那些词,语义不强,通常为没有独立意义的功能词
- open:例如动词,经常有更新和新的词加入,通常open类别的都是内容词(有语义内容特点)
Syntactic parsing 句法分析
- 描述well-formed sequences of words,最重要的是句子 重要的句法分析任务就是找到描述语言well-formed 句子的结构原理规则
- 输入的是sequence of words(句子),输出的是二值化输出,well or not
- well-formed 意味着他有满足syntactic 条件的结构描述或者syntactic 约束
- well-formdness并不保证有意义或者coherence
1 Constituency(aka phrase 结构)和dependency based syntactic 理论对NLP很重要
2 constituent是一个词或者一组consecutive·连续的词形成了一个自然单元
- 可以放到多种句子中
- 可以是问句的答案
- 可以用代词代替
3 constituency-based syntax语法
- 分类constituent
- 形成规则根据哪些constituent能放在一起变成更大的词,eventually形成一整个句子
句法结构的好坏取决于它的constituency结构 - 其树结构(有向图)几个fragment
4 dependency-based 语法(有向关系 词词依赖)
treat 词之间的dependency 关系作为基础
通常是d word 依赖 h word (h head d)在一个句子,if
- d改变了h的含义,使其更具体,eat->eat bread(吃?具体吃什么?)
- 省略的非对称关系 d省略,h保持它的含义;但反过来就不同了
5 什么时候dependency?
- exactly一个独立的词(root)
- all其他的词都依赖这个词,
- 结果是有向依赖graph of 句子是个树
大部分的依赖语法work with typed邮箱依赖(有限的list of邮箱依赖types 带有特定约束)
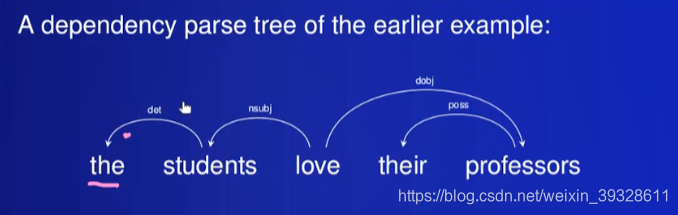
和constituency树相比,node更少(每个word一个点) 但是边被带上相应的依赖类型标签
NER(named entity recognition)
任务是找到输入text的表达中的那些naming 实体,再给这些实体贴上标签。name一些typical 的词,分出类别。
通常这些实体是person,组织,地点,也有一些是data,event,…
coreference resolution 消除指代
决定实体命名的指代,确定referring表达的边界范围,包含常见名词代词,cluster 他们,根据谁的成员都属于一个实体来分组。
实体联系linking
也与实体reference 相关,但从以下两方面不同:
- as NER,局限于name-like 表达
- 通过外部知识base连接名字和实体记录,来确定实体的身份
WSD(所有content词)
word sense disambiguation
连接表达与meanings/senses 在外部inventory
- 主要是关于常见名词和其他content word 的其他类型,动词,adj。 adv.
- sense collections是主要目标,建立lexical 词汇资源
WSD系统可以分出一词多义,例如mouse
semantic role labelling(SRL)
identify predicate 和 argument 表达(谓语和宾语)
- predicate:表达event或者situation
- argument 指的是这些event 的参与者
role标签是确定participant的类别和角色,根据宾语在时间表达的角色,参考所用谓语
I give you a present
semantic 解析
full or deep 语义解析,不仅包括coreference resolution,WSD he 谓语宾语结构,还打算提供完整的formal 语义表示
- 正式结构表示输入文字的含义
- 表示词义
- 去歧义
- canonical inthe sense ,text有独自的表示
- 有很多有效的算法可以找到逻辑和语义关系 与其他语义和知识表示














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









