







贪婪策略
某一策略是贪婪的for 状态值方程V,if $\pi(s,a)=1 $ ifa等于估计状态动作值方程最大值,否则为0;
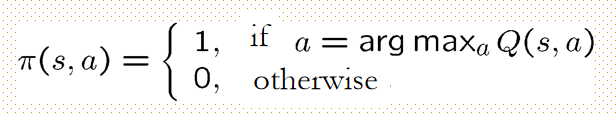
最优策略(最大的状态值方程)
V
∗
(
s
)
=
m
a
x
π
V
π
(
s
)
V^{*}(s)=max_{\pi} V^{\pi}(s)
V∗(s)=maxπVπ(s)
V的贪婪策略是最优的,V的贪婪策略可能不止一个,但所有的
V
π
∗
V^{\pi ^{*}}
Vπ∗都等于V*;
如何计算最优策略?(期望)
计算最优状态值方程,写出Bellman equation,从各部分加到一起
V*(s)是从s开始收集的最多的reward
Q*(s,a)是从s开始收集的第一次使用action a的最多reward
最优值方程
 将Q带入V,得到最优状态值方程的bellman等式
将Q带入V,得到最优状态值方程的bellman等式
非线性,有解且唯一,排除长期规划问题
解
线性编程太多方程,太多矩阵,这里我们可以采用动态编程(DP):
- 策略迭代
- 值迭代
- 已知P(s,a,s’)和R(s,a)
如果不知道这些量 则用Monte Carlo或者temporal difference方法
1 策略迭代:已知value fuction的话我们可以improve the stategy(先evaluate 该策略然后改善,直到收敛)
迭代 stategy evaluation-用Bellman operator
T
π
T_{\pi}
Tπ是value function(mapping),告诉我们当使用
π
\pi
π时state的value,是贝尔曼operator,V->
T
π
T_{\pi}
Tπ
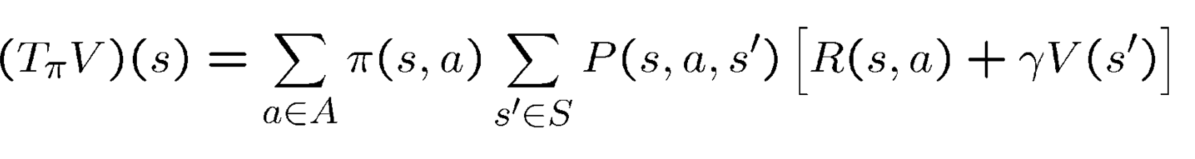
然后我们应用V
V
π
V_{\pi}
Vπ是贝尔曼operator的fixed point 方程的解:
V
V
V=
T
π
V
T_{\pi}V
TπV;
过程:V_{0}任意, V k + 1 = T π V k , V k − > V π V_{k+1}=T_{\pi}V_{k},V_{k}->V^{\pi} Vk+1=TπVk,Vk−>Vπ
改进策略:给定
π
,
V
π
\pi,V^{\pi}
π,Vπ, 如果存在
π
′
\pi^{'}
π′,对于所有s,使


improve一步相当于整体improve
收敛性:T这个operator作用于收敛的值方程,任意U,V满足:(系数小于1)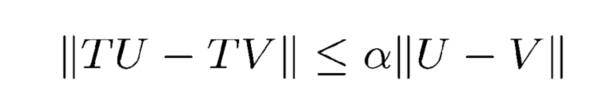
Banach-fixed point 理论:收敛的operator有唯一的fixed point
整个策略迭代过程:
2 值迭代
直接迭代V*,使用贪婪operator (收敛)

V是
V
=
T
∗
V
V=T^{*}V
V=T∗V的解
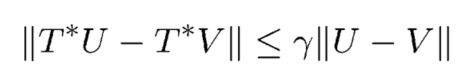
过程:V0 任意,
V
t
+
1
=
T
∗
V
t
V_{t+1}=T^{*}V_{t}
Vt+1=T∗Vt,收敛时停止,fixed point:V
两种迭代比较:
策略迭代巫妖少量迭代次数,但是耗时长
值迭代在多项式时间收敛到最优值
策略迭代收敛但不知道limit
取决于实际example
DP 方法
收敛,但是,慢,需啊哟建模,严格的马尔科夫assumption
这些在RL方法中改进















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









