







一、背景
大语言模型(LLMs)如DeepSeek R1,Qwen2.5,Chat-GPT和 Gemini 2.5 Pro,Claude等,正以前所未有的速度渗透到各行各业,展现出惊人的能力和潜力。然而,这股浪潮之下,是巨大的技术挑战:LLM 的训练动辄需要数周甚至数月,消耗海量的 GPU/TPU 资源;模型的推理服务则要求低延迟、高并发和极致的弹性。如何高效、可靠、可扩展地管理这整个复杂流程?云原生 Kubenretes 相关技术正在应对这些挑战。
二、Kubernetes 与 LLM
2.1 云原生与大模型的天然契合
Kubernetes 已成为容器编排领域的事实标准。它提供的不仅仅是容器运行环境,更是一套构建、部署和管理可扩展、高弹性应用的范式——这正是云原生理念的核心。而大模型的需求,恰好与 Kubernetes 的核心优势高度匹配:
资源抽象与异构管理:
LLM 依赖 GPU/TPU 等昂贵加速器。K8s 通过 Device Plugins 等机制,能将这些异构硬件资源纳入统一的资源池进行调度和管理,提高利用率。
极致的弹性伸缩:
训练: 分布式训练任务需要动态增减节点;K8s 可按需调度计算资源。
推理: 推理服务的负载波动极大,K8s 的 HPA (Horizontal Pod Autoscaler) 能根据实时负载(CPU/GPU 利用率、QPS 等)自动调整服务实例数量,从容应对峰值,并在低谷时节省成本。
高可用与自愈能力:
LLM 训练是长时间任务,推理服务要求 7x24 可用。K8s 能自动检测并替换失败的 Pod/节点,保证任务的连续性和服务的稳定性(需配合训练框架的 checkpointing)。
环境一致性与可移植性:
容器化(Docker/OCI)封装了所有依赖,确保了从开发、测试到训练、推理环境的一致性。K8s 则让这套环境可以轻松部署在任何主流云厂商或本地数据中心。
自动化与声明式配置:
通过 YAML 文件定义资源需求、部署策略和服务依赖,K8s 自动化地完成部署和管理,极大降低运维复杂度,并为 GitOps 实践奠定基础。
服务发现与负载均衡:
内建的服务机制简化了模型服务、数据处理服务等内部组件的通信和流量管理。
简而言之,Kubernetes 将管理大规模分布式系统的复杂性进行了抽象和自动化,使得 AI 团队能更专注于模型本身,而非底层基础设施的繁琐细节。云原生提供的弹性、敏捷和自动化能力,让 LLM 研发流程更加便捷 高效。
2.2 大模型研发流程中的Kubernetes
从数据准备到最终的模型服务,Kubernetes 在 LLM 工作流的每个阶段都扮演着关键角色:
1) 数据准备与处理:
利用 K8s Job 或 CronJob 运行数据清洗、标注、特征工程等批处理任务。
结合 Kubeflow Pipelines、Argo Workflows 等工作流引擎,编排复杂的数据处理流程。
通过 K8s 部署 Spark、Dask 等分布式计算框架,加速海量数据处理。
Persistent Volumes (PV) 和 Persistent Volume Claims (PVC) 提供了对数据集的持久化存储管理。
2) 模型训练 (尤其是分布式训练):
GPU 调度: NVIDIA Device Plugin 等让 K8s Pod 能请求并使用 GPU 资源。
简化分布式任务:
Kubeflow Training Operators (TFJob, PyTorchJob, MPIJob 等): 这些 CRD (Custom Resource Definitions) 极大地简化了在 K8s 上部署 TensorFlow、PyTorch、Horovod、DeepSpeed 等分布式训练任务的复杂度。开发者只需定义角色(如 worker, parameter server)、副本数和资源需求,Operator 会自动创建、管理对应的 Pod 和服务,处理 Pod 间通信设置。
Ray on K8s (KubeRay): Ray 是一个强大的分布式计算框架,KubeRay 项目使其能无缝运行在 K8s 上,为复杂的训练模式(如混合并行)和超参数优化提供了便利。
资源管理: K8s 的 Namespace、Resource Quotas 和 Priority Classes 可用于隔离团队资源、限制消耗,并确保关键训练任务的优先级。
3) 模型微调与评估:
与训练类似,K8s 能快速启动和管理多个并行的微调实验,每个实验环境隔离。
使用 K8s Job 运行模型评估脚本,产出性能指标。
结合 MLOps 平台(如 MLflow,通常也部署在 K8s 上)追踪实验参数、指标和产出的模型文件。
4) 模型服务与推理:
基础部署: 使用 K8s Deployment 管理推理服务的 Pod 副本,通过 Service 和 Ingress 暴露 API 并进行负载均衡。
自动伸缩: HPA 是实现弹性推理的关键,能根据实时指标动态调整服务实例数。
高级模型服务框架 (构建于 K8s 之上):
KServe (原 KFServing): 领先的开源模型推理平台,提供标准化的 V2 推理协议、Serverless 推理(可缩容至零)、Canary 部署、特征转换、模型可解释性集成等。支持 TensorFlow, PyTorch, ONNX, TensorRT 等多种框架。
Seldon Core: 另一个强大的 MLOps 平台,侧重于复杂的部署策略(如 A/B 测试、多臂老虎机)、推理图(Inference Graphs)和高级监控。
BentoML / Ray Serve: 提供更友好的模型打包和部署体验,并能部署到 K8s 以利用其编排能力。
NVIDIA Triton Inference Server: 高性能推理服务器,支持模型集成和多种后端优化,可以作为 Pod 高效运行在 K8s 上。
2.3 主流框架与技术栈生态
在 Kubernetes 上构建 LLM 应用,通常会用到以下技术栈组合:
-
核心平台: Kubernetes (EKS, GKE, AKS, OpenShift, Rancher, 或自建)
-
MLOps/AI 平台 (on K8s): Kubeflow, Ray/KubeRay, Flyte
-
分布式训练 (Operators/Integrations): Kubeflow Training Operators (TFJob, PyTorchJob, MPIJob), KubeRay
-
模型服务 (on K8s): KServe, Seldon Core, BentoML, Ray Serve, NVIDIA Triton
-
工作流编排: Kubeflow Pipelines, Argo Workflows, Airflow (on K8s Executor)
-
硬件加速: NVIDIA Device Plugin (及其他厂商插件)
-
监控与日志: Prometheus, Grafana, ELK/Loki Stack
这个生态仍在快速发展,但核心是利用 K8s 作为统一的资源管理和应用编排层。
三、实战Kubernetes 基础环境搭建
3.1 服务器资源准备
测试用两台 ECS 带 A10 显卡即可,极限一点一台也成,两台主要是为了验证多节点情况。
请参考:
3.2 基础配置
1) Ubuntu 系统环境配置
# 更新系统并安装基础工具
sudo apt-get update && sudo apt-get upgrade -y
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
sudo hostnamectl set-hostname --static "te1"
ip addr show | grep 'inet ' | grep -v '127.0.0.1' | awk '{print $2}' | cut -d/ -f1 | head -n 1
echo $ip "te1" >> /etc/hosts
#########################################
sudo apt-get update
sudo apt-get install -y curl gpg
# 禁用交换分区(Kubernetes 要求)
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab # 永久禁用
# 配置内核参数,允许iptables检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
ip_tables
iptable_nat
nf_nat
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
sudo modprobe ip_tables
sudo modprobe iptable_nat
sudo modprobe nf_nat
### 设置内核参数
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system2) 容器环境配置(containerd)
### 安装容器运行时(Containerd) 安装依赖项
sudo apt install -y apt-transport-https ca-certificates curl gnupg lsb-release
# 添加 containerd 官方 GPG 密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 添加 containerd 仓库
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 安装 containerd
sudo apt-get update
#sudo apt-get install -y docker-ce docker-ce-cli containerd.io
sudo apt-get install -y docker-ce-cli containerd.io
### 配置 Containerd
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml > /dev/null
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
sudo systemctl enable containerd
sudo systemctl restart containerd
# 添加 NVIDIA 仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=containerd
sudo systemctl restart containerd
# 验证 GPU 支持
# docker run --rm --gpus all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
配置检查项(确保的容器runtime 运行在 nvidia):
cat /etc/containerd/config.toml | grep default_runtime_name
cat /etc/containerd/config.toml | grep -A 1 'containerd.runtimes.nvidia.options'
docker run --rm --gpus all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi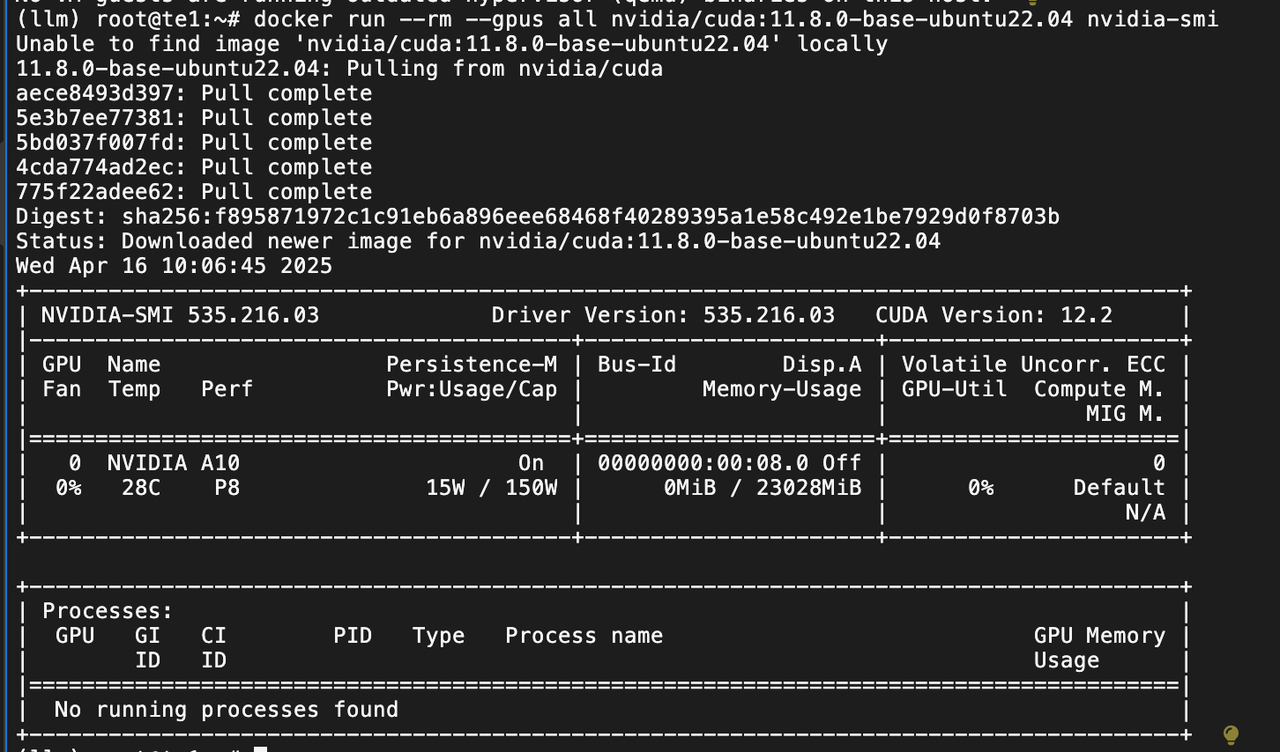
3) Kubernetes基础环境配置
sudo mkdir -p /etc/apt/keyrings
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.31/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
sudo systemctl enable --now kubelet3.3 Kubernetes 部署(单机版)
1) 基础组件安装
## 如果网络不同可以换成阿里云的镜像地址
sudo kubeadm init --kubernetes-version=1.31.7 \
--pod-network-cidr=10.244.64.0/20
# 配置 kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
## 由于是测试,要放开主节点也要允许调度
kubectl taint nodes --all node-role.kubernetes.io/control-plane-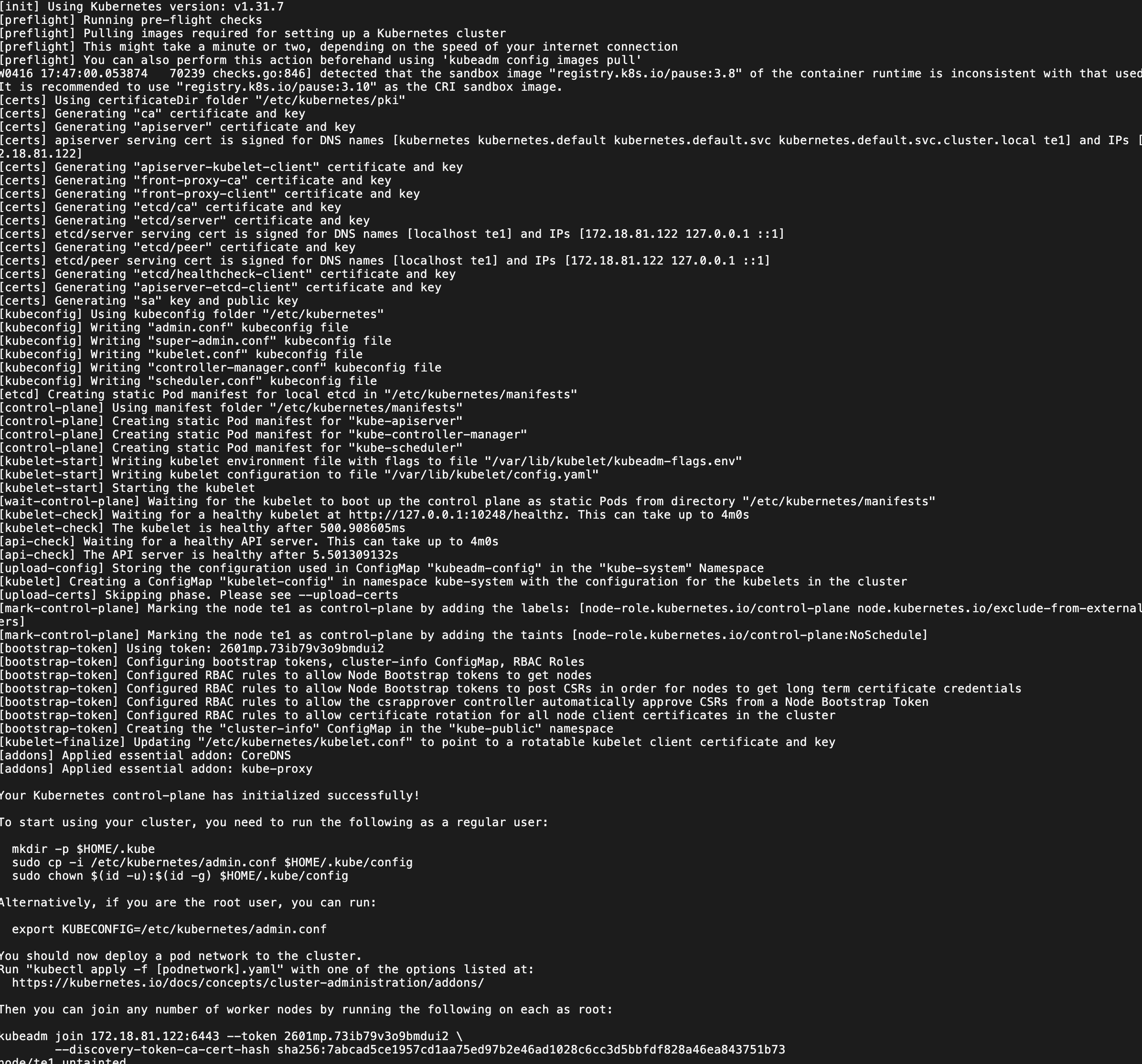
3.4 Calico 网络CNI 插件安装
# # 安装 Calico 网络插件
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/tigera-operator.yaml
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/custom-resources.yaml
cat <<EOF | kubectl apply -f -
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
calicoNetwork:
ipPools:
- blockSize: 26
cidr: 10.244.64.0/20
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
---
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
EOF
3.5 nvidia-device-plugin 插件安装
1) containerd 默认配置 runtime : nvidia
直接安装就行了
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.yml2) containerd 未配置默认runtime : nvidia
可以在k8s里面配置,安装RuntimeClass:
这一步很关键 安装k8s 插件无法识别 GPU 资源
cat <<EOF | kubectl apply -f -
apiVersion: node.k8s.io/v1
handler: nvidia
kind: RuntimeClass
metadata:
name: nvidia
EOF识别不到资源是这样的

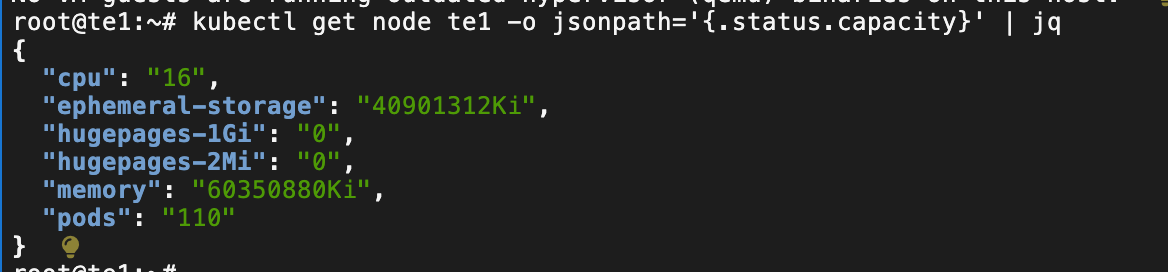
日志显示 无论如何也识别不到 GPU 资源
修改runtimeClassName: "nvidia"
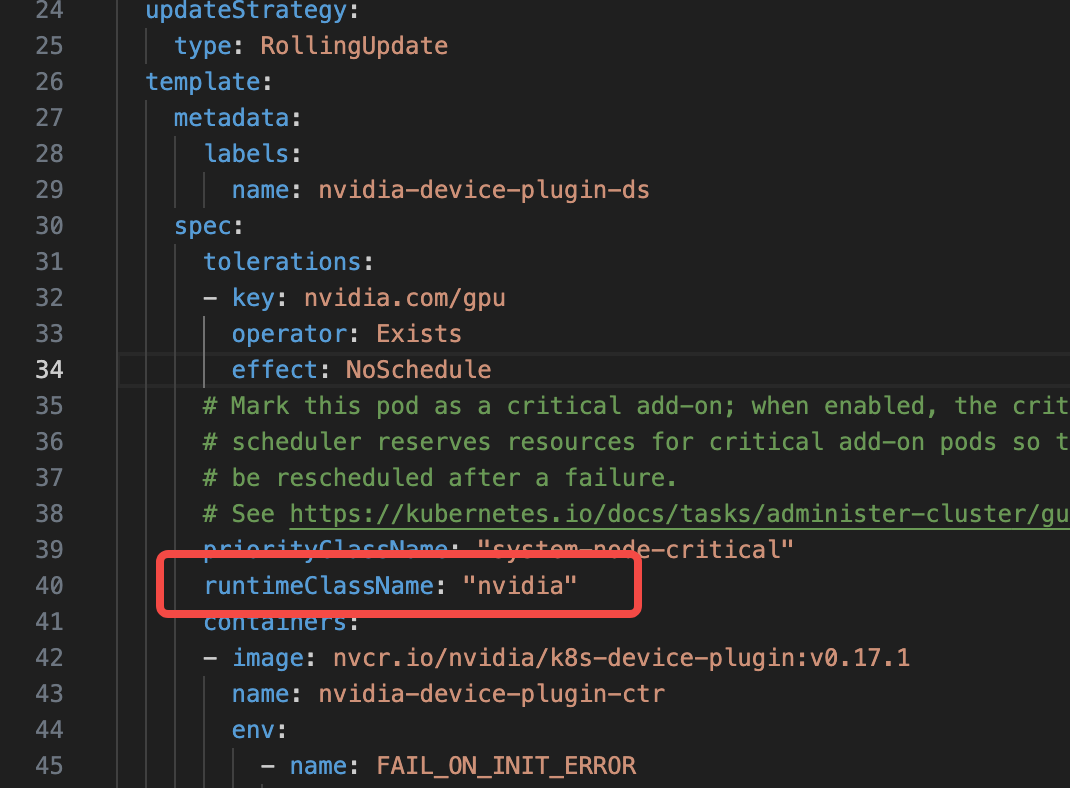
正确识别到资源的情况是这样的:
kubectl logs -f -n kube-system nvidia-device-plugin-daemonset-qxndp
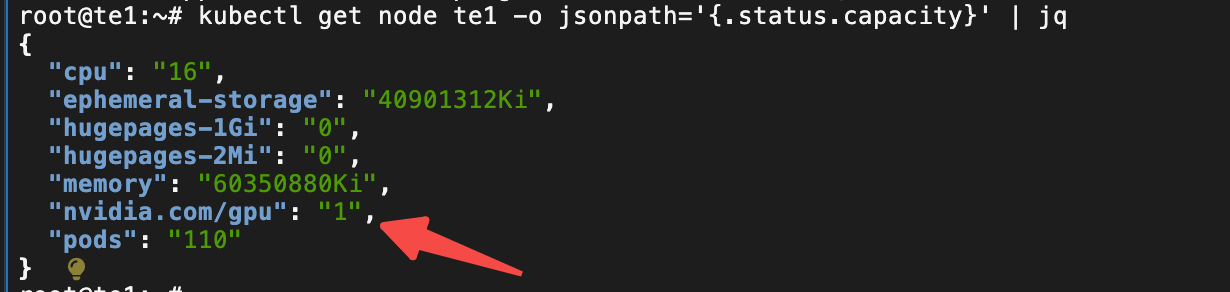
能识别到资源独占单卡模式 1 张GPU 显卡
3.6 添加 worker 节点
## 在不同的节点执行
kubeadm join 172.18.81.122:6443 --token 2601mp.73ib79v3o9bmdui2\
--discovery-token-ca-cert-hash sha256:7abcad5ce1957cd1aa75ed97b2e46ad1028c6cc3d5bbfdf828a46ea843751b73 \
--node-name te2
## 在不同的节点执行
kubeadm join 172.18.81.122:6443 --token 2601mp.73ib79v3o9bmdui2\
--discovery-token-ca-cert-hash sha256:7abcad5ce1957cd1aa75ed97b2e46ad1028c6cc3d5bbfdf828a46ea843751b73 \
--node-name te3
## 在不同的节点执行
kubeadm join 172.18.81.122:6443 --token 2601mp.73ib79v3o9bmdui2\
--discovery-token-ca-cert-hash sha256:7abcad5ce1957cd1aa75ed97b2e46ad1028c6cc3d5bbfdf828a46ea843751b73 \
--node-name te4
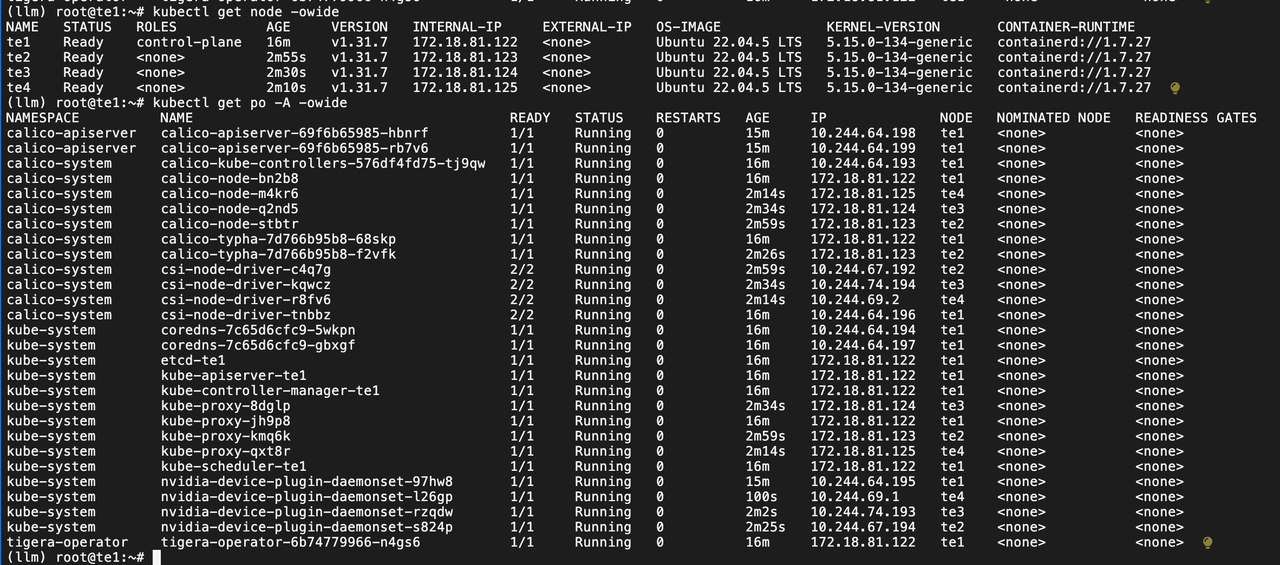
整体 Pod 和 Node 运行情况:
3.7 Dashboard 安装
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 443
protocol: TCP
targetPort: 8443
nodePort: 31000
selector:
k8s-app: kubernetes-dashboard
sessionAffinity: None
type: NodePort
EOF
#kubectl -n kubernetes-dashboard edit service kubernetes-dashboard
### token 密钥登录要用到
kubectl -n kubernetes-dashboard create token admin-user --duration=24h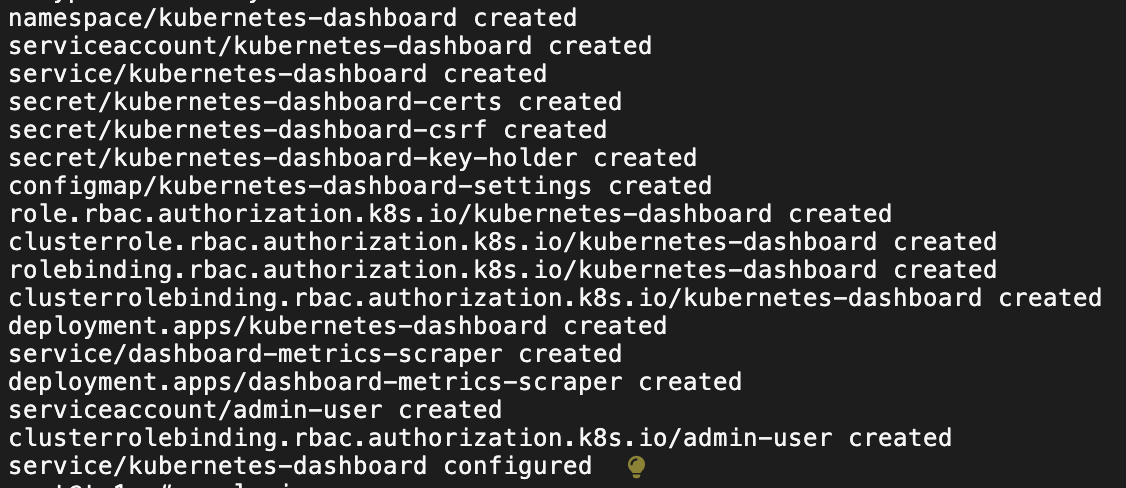
kubectl get svc,po -n kubernetes-dashboard
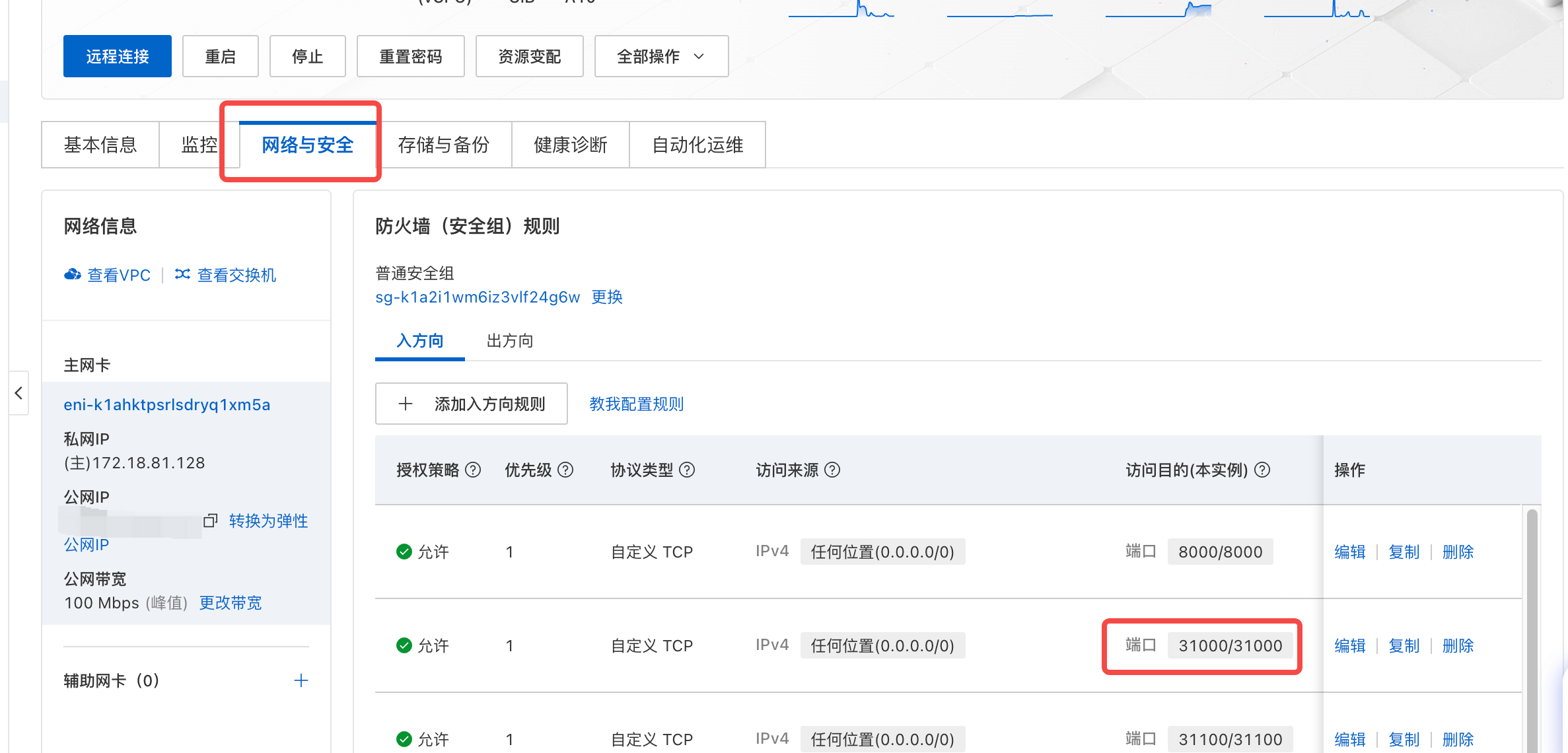
采用 NodePort 方式暴露服务,需要阿里云打开 ECS 的安全组才能正常访问。
## 获取密钥
kubectl -n kubernetes-dashboard create token admin-user --duration=24h
## 获取公网IP
curl cip.cc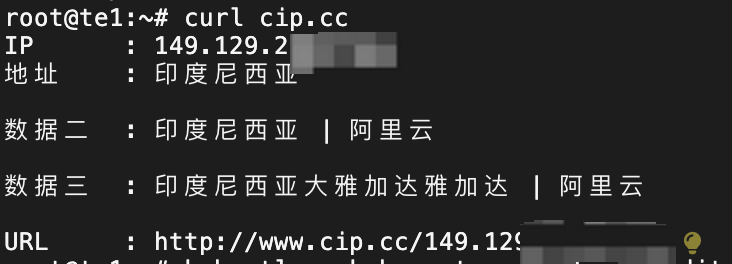
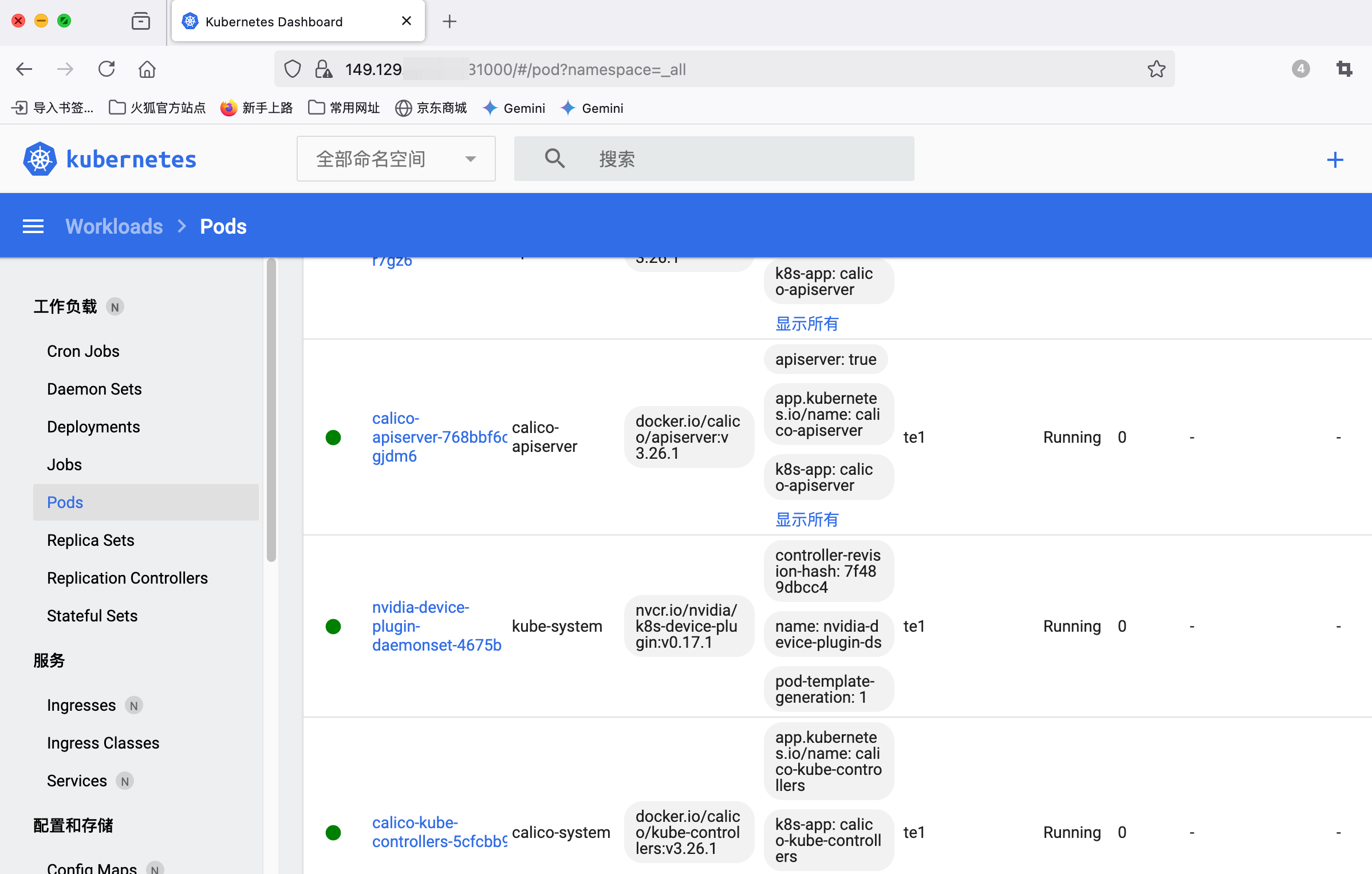
打开安全组31000:
四、测试 验证
4.1 Pod GPU 调度
当前 GPU 资源采用单卡形式提供,还可以分时复用感兴趣的话可以多尝试尝试 不同的 GPU 资源调度使用策略
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-test1
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0
command: ["/bin/sh", "-c"]
args: ["echo '----- 等待 ----'; while true; do sleep 3600; done"]
resources:
limits:
nvidia.com/gpu: 1
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOF
创建了四个 Pod 每个 Pod 需要一个单卡 GPU 资源,观察下来已经全部都调度完毕了。
五、小结
终于回归主线了笔者是云原生方向的。本篇实验基本没难度了就,老本行了。艰难肝大模型基础架构,大体上有了一些基本的了解。后续更多的会采用云原生方式去训练,推理模型。探索更多大模型在云原生上的应用。比如: Kubeflow,MLFlow,Volcano,Rook / Ceph,argo-workflows等等吧。
参考:
Kubernetes生产级别的容器编排系统![]() https://kubernetes.io/zh-cn/https://github.com/NVIDIA/k8s-device-plugin
https://kubernetes.io/zh-cn/https://github.com/NVIDIA/k8s-device-plugin![]() https://github.com/NVIDIA/k8s-device-pluginhttps://github.com/kubernetes/kubernetes
https://github.com/NVIDIA/k8s-device-pluginhttps://github.com/kubernetes/kubernetes![]() https://github.com/kubernetes/kuberneteshttps://github.com/containerd/containerd
https://github.com/kubernetes/kuberneteshttps://github.com/containerd/containerd![]() https://github.com/containerd/containerdcontainerd – An industry-standard container runtime with an emphasis on simplicity, robustness and portabilityAn industry-standard container runtime with an emphasis on simplicity, robustness, and portability
https://github.com/containerd/containerdcontainerd – An industry-standard container runtime with an emphasis on simplicity, robustness and portabilityAn industry-standard container runtime with an emphasis on simplicity, robustness, and portability![]() https://containerd.io/https://github.com/NVIDIA/nvidia-container-toolkit
https://containerd.io/https://github.com/NVIDIA/nvidia-container-toolkit![]() https://github.com/NVIDIA/nvidia-container-toolkitInstalling the NVIDIA Container Toolkit — NVIDIA Container Toolkit
https://github.com/NVIDIA/nvidia-container-toolkitInstalling the NVIDIA Container Toolkit — NVIDIA Container Toolkit![]() https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.htmlKubeflowKubeflow makes deployment of ML Workflows on Kubernetes straightforward and automated
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.htmlKubeflowKubeflow makes deployment of ML Workflows on Kubernetes straightforward and automated![]() https://www.kubeflow.org/https://github.com/projectcalico/calico
https://www.kubeflow.org/https://github.com/projectcalico/calico![]() https://github.com/projectcalico/calicoUnified network security & observability for KubernetesA single platform for any Kubernetes distribution in the cloud or on premises. Eliminate tool sprawl, fragmented control, and multi-cluster limitations.
https://github.com/projectcalico/calicoUnified network security & observability for KubernetesA single platform for any Kubernetes distribution in the cloud or on premises. Eliminate tool sprawl, fragmented control, and multi-cluster limitations.![]() https://www.tigera.io/Cloud Native Computing FoundationCNCF is the vendor-neutral hub of cloud native computing, dedicated to making cloud native ubiquitous.
https://www.tigera.io/Cloud Native Computing FoundationCNCF is the vendor-neutral hub of cloud native computing, dedicated to making cloud native ubiquitous.![]() https://www.cncf.io/
https://www.cncf.io/


















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











