






背景介绍
在企业场景中,LLM可以被应用于多个领域,例如智能问答、文本摘要、内容创作、代码生成等,为提高工作效率、优化客户体验等带来全新的可能性。越来越多的企业开始探索将LLM引入业务环境中。然而,企业在自有环境中部署和运行LLM面临诸多挑战:
- 部署复杂性:LLM模型通常规模庞大,需要大量算力资源,部署运维较为困难。
- 扩展性限制:企业难以随着业务发展灵活扩展LLM推理服务的计算资源。
- 可观测性缺失:缺乏对LLM服务的监控和运维能力,难以保证服务质量。
- 存储管理成本高:LLM模型文件往往体量庞大,分布式存储和管理成本高昂。
如何在企业自有环境中平滑部署并高效运行LLM,满足业务需求,是当前企业急需解决的问题。
总体架构
为解决企业在自有环境中部署和运行LLM面临的诸多挑战,我们提出了一种基于亚马逊云科技云原生服务的解决方案。该解决方案旨在为企业提供一个生产级别的LLM推理环境,具备良好的扩展性、可观测性以及存储管理能力。**整体架构设计遵循云原生的理念,充分利用了亚马逊云科技的各种托管服务和开源工具,构建了一个可靠、可扩展、易于管理和可观测的LLM部署运行平台。**架构图如下所示:
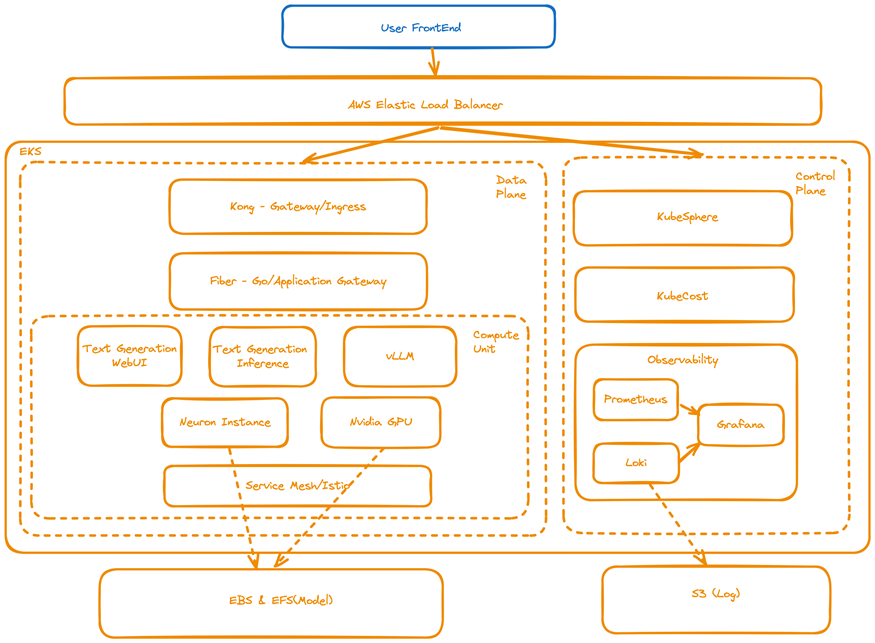
我们可以从4个层面来看这个架构设计,分别是基础设施、服务网格、应用和可观测性。基础设施层提供了云原生的资源管理能力;服务网格层负责流量管控和部署策略;应用层包含了LLM推理的核心功能;而可观测性层则确保了整个平台的可视化和可维护性。每层的具体组件和作用如下:
1
基础设施层
- Amazon EKS作为Kubernetes集群的基础承载层。
- Amazon Elastic Load Balancer提供应用层负载均衡能力。
- Amazon EFS统一管理LLM模型数据持久化存储。
- Amazon Karpenter实现计算资源的弹性伸缩。
2
服务网格层
- Kong作为API网关,实现流量控制和基本认证。
- Istio Service Mesh支持灰度和金丝雀发布等。
3
应用层
- 自研应用网关层处理请求转发及适配。
- Text Generation WebUI、vLLM和Text Generation Inference等开源方案作为LLM推理引擎(算力单元)。
4
可观测性层
- Prometheus、Grafana、Loki实现指标和日志监控。
- KubeSphere和KubeCost提供集群管理和费用管控能力。
使用该方案用户只需专注于LLM模型的选型和应用,底层的基础设施和运维管理完全由解决方案自动化处理,大幅降低了LLM服务的运维复杂度。同时该方案具备水平扩展能力,能够随时根据业务发展灵活扩缩容LLM推理资源,保证高性能和高可用,还提供可观测性能力,确保服务质量,统一的LLM模型存储也使得存储管理更加便捷高效。整体部署方案代码和配置已经发布在Github仓库,可查看下方链接。
Github仓库
https://github.com/GlockGao/llm-on-eks.git
创新点
作为大语言模型在企业级场景落地的先驱性实践,我们的解决方案在多个技术层面做出了创新,以确保LLM服务的高性能、高可靠以及良好的运维体验:
1.算力单元支持多种开源框架,包括Text Generation WebUI、vLLM和Text Generation Inference等,并且对开源LLM框架Text Generation WebUI进行改造,支持在Kubernetes环境下运行。
原生的Text Generation WebUI项目是为单机环境设计的,不支持在Kubernetes集群中部署运行。我们对其进行了深度定制化改造,使其能在Kubernetes环境下顺利部署和运行。主要的改造工作包括:
- 封装成Docker容器化应用,实现无状态部署。
- 将模型数据持久化到外部存储(Amazon EFS),解除和宿主机的耦合。
- 优化配置加载和资源请求方式,适配Kubernetes的调度机制。
- 修改日志输出,与Kubernetes日志收集组件对接。
\2. 支持利用Amazon Neuron芯片加速LLM推理。
大语言模型的计算复杂度很高,对算力需求极大。利用亚马逊云科技推出的Amazon Neuron芯片 (Amazon Inferentia和Amazon Trainium),可以大幅降低推理的延迟和成本。然而原生的Text Generation WebUI并不支持直接使用这种加速芯片。我们对其进行了以下关键改造:
- 修改模型加载模块,添加新的加载器以支持Amazon Neuron SDK。
- 重构推理逻辑,使用Amazon Neuron的Python API进行推理计算。
- 优化显存使用策略,充分发挥Amazon Neuron芯片的算力。
\3. 构建统一的LLM应用网关层。
为了实现LLM服务的高可用、可扩展,我们自研了一个应用网关层,作为与LLM推理引擎的适配层。该网关层由Golang语言编写,基于Fiber框架构建,充当反向代理,接收客户端请求并进行协议转换和负载分发。网关层的主要创新点有:
- 内置服务发现机制,自动探索可用的LLM推理实例。
- 实现请求级别的负载均衡和故障转移策略。
- 支持限流、认证等网关常见功能。
- 提供统一的指标和日志输出,与监控系统集成。
实施步骤
前提条件
1.安装kubectl。
ARCH=amd64
PLATFORM=$(uname -s)_$ARCH
curl -sLO "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_$PLATFORM.tar.gz"
curl -sL "https://github.com/eksctl-io/eksctl/releases/latest/download/eksctl_checksums.txt" | grep $PLATFORM | sha256sum --check
tar -xzf eksctl_$PLATFORM.tar.gz -C /tmp && rm eksctl_$PLATFORM.tar.gz
sudo mv /tmp/eksctl /usr/local/bin
eksctl version
左右滑动查看完整示意
2.安装eksctl。
# 下载1.28版本
curl -O https://s3.us-west-2.amazonaws.com/amazon-eks/1.28.5/2024-01-04/bin/linux/amd64/kubectl
# 下载验证文件
curl -O https://s3.us-west-2.amazonaws.com/amazon-eks/1.28.5/2024-01-04/bin/linux/amd64/kubectl.sha256
# 验证sha
256sum -c kubectl.sha256
# 更改执行
chmod +x ./kubectl
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$HOME/bin:$PATH
# 设置PATH环境变量
echo 'export PATH=$HOME/bin:$PATH' >> ~/.bashrc
# 查看版本
kubectl version --client
左右滑动查看完整示意
3.安装helm。
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
helm version
左右滑动查看完整示意
4.安装Amazon CLI、配置亚马逊云科技权限。
5.创建Amazon EKS集群。
- 集群创建配置文件eks-cluster.yaml,下述配置以us-west-2、1.28版本为例,可以根据需要自行配置。

左右滑动查看完整示意
- 创建集群命令。
eksctl create cluster -f eks-cluster.yaml
左右滑动查看完整示意
准备基础环境
安装Amazon Load Balancer Controller
1.创建OIDC Provider,需配置CLUSTER_NAME。
export cluster_name=${CLUSTER_NAME}
eksctl utils associate-iam-oidc-provider --cluster $cluster_name --approve
左右滑动查看完整示意
2.获取并创建IAM Policy。
# 获取IAM Policy
curl -o iam-policy.json https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/v2.7.0/docs/install/iam_policy.json
# 创建IAM Policy
aws iam create-policy \
--policy-name AWSLoadBalancerControllerIAMPolicy \
--policy-document file://iam-policy.json
左右滑动查看完整示意
3.创建Service Account,需配置CLUSTER_NAME、REGION和ACCOUNT_ID等信息。
export cluster_name=${CLUSTR_NAME}
export region=${REGION}
export AWS_ACCOUNT_ID=${ACCOUNT_ID}
eksctl create iamserviceaccount \
--cluster=$cluster_name \
--namespace=kube-system \
--name=aws-load-balancer-controller \
--attach-policy-arn=arn:aws:iam::$AWS_ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy \
--override-existing-serviceaccounts \
--region $region \
--approve
左右滑动查看完整示意
4.添加并helm repo。
helm repo add eks https://aws.github.io/eks-charts
helm repo update eks
左右滑动查看完整示意
5.安装Amazon Load Balancer Controller。
helm install aws-load-balancer-controller eks/aws-load-balancer-controller \
-n kube-system \
--set clusterName=$cluster_name \
--set serviceAccount.create=false \
--set serviceAccount.name=aws-load-balancer-controller
左右滑动查看完整示意
安装Amazon EFS Driver
1.下载并创建Amazon IAM Policy。
curl -O https://raw.githubusercontent.com/kubernetes-sigs/aws-efs-csi-driver/master/docs/iam-policy-example.json
aws iam create-policy \
--policy-name EKS_EFS_CSI_Driver_Policy \
--policy-document file://iam-policy-example.json
左右滑动查看完整示意
2.创建Service Account,需配置CLUSTER_NAME信息。
export cluster_name=${CLUSTER_NAME}
export role_name=AmazonEKS_EFS_CSI_DriverRole
eksctl create iamserviceaccount \
--name efs-csi-controller-sa \
--namespace kube-system \
--cluster $cluster_name \
--role-name $role_name \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEFSCSIDriverPolicy \
--approve
TRUST_POLICY=$(aws iam get-role --role-name $role_name --query 'Role.AssumeRolePolicyDocument' | \
sed -e 's/efs-csi-controller-sa/efs-csi-*/' -e 's/StringEquals/StringLike/')
aws iam update-assume-role-policy --role-name $role_name --policy-document "$TRUST_POLICY"
左右滑动查看完整示意
3.添加并更新helm repo。
# 1. 添加helm repo
helm repo add aws-efs-csi-driver https://kubernetes-sigs.github.io/aws-efs-csi-driver/
# 2. 更新helm repo
helm repo update aws-efs-csi-driver
左右滑动查看完整示意
4.安装Amazon EFS Driver。
helm upgrade --install aws-efs-csi-driver --namespace kube-system aws-efs-csi-driver/aws-efs-csi-driver \
--set controller.serviceAccount.create=false \
--set controller.serviceAccount.name=efs-csi-controller-sa
左右滑动查看完整示意
5.安装Amazon EFS Storage Class。
- 配置文件efs-sc.yaml。
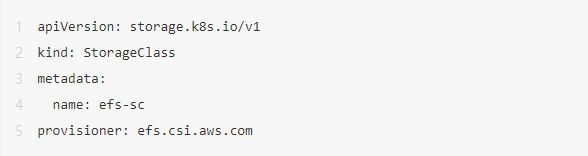
- 部署命令。
kubectl apply -f efs-sc.yaml
安装Amazon EBS Driver
1.创建Service Account,需配置CLUSTER_NAME和ACCOUNT_ID信息。
export cluster_name=${CLUSTER_NAME}
export AWS_ACCOUNT_ID=${ACCOUNT_ID}
eksctl create iamserviceaccount \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster $cluster_name \
--role-name AmazonEKS_EBS_CSI_DriverRole \
--role-only \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve
左右滑动查看完整示意
2.安装Amazon EBS Driver。
eksctl create addon --name aws-ebs-csi-driver --cluster $cluster_name --service-account-role-arn arn:aws:iam::${AWS_ACCOUNT_ID}:role/AmazonEKS_EBS_CSI_DriverRole --force
左右滑动查看完整示意
3.安装 EBS Storage Class。
- 配置文件ebs-sc.yaml。
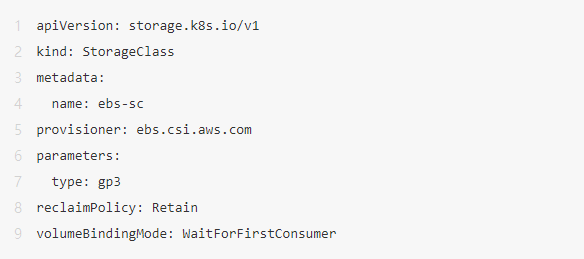
- 安装命令。
kubectl apply -f gp3-sc.yaml
安装Karpenter
- Karpenter主要用于Amazon EKS集群的CA扩展。
- Karpenter的安装主要包括两种方式:直接安装(适用于创建全新集群)和Migration(适用于集群已经存在)。
- 文章中采用第二种方式安装Karpenter,具体步骤参考下方链接。
- 集群安装完成后需创建NodePool以指导Karpenter如何扩缩集群,示例如下:
具体步骤
https://karpenter.sh/docs/getting-started/migrating-from-cas/
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["5"]
nodeClassRef:
name: default
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 720h # 30 * 24h = 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2 # Amazon Linux 2
role: "KarpenterNodeRole-eks-cluster-prod" # replace with your cluster name
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: eks-cluster-prod # replace with your cluster name securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: eks-cluster-prod # replace with your cluster name
左右滑动查看完整示意
准备控制面环境
安装KubeSphere
1.下载安装文件。
wget https://github.com/kubesphere/ks-installer/releases/download/v3.4.1/kubesphere-installer.yaml
wget https://github.com/kubesphere/ks-installer/releases/download/v3.4.1/cluster-configuration.yaml
左右滑动查看完整示意
2.安装命令。
kubectl apply -f kubesphere-installer.yaml
左右滑动查看完整示意
3.监控安装进程。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
左右滑动查看完整示意
4.查看安装结果。
kubectl get svc -n kubesphere-system
5.查看UI页面:对应ks-console服务。
安装KubeCost
1.安装命令。
helm upgrade -i kubecost oci://public.ecr.aws/kubecost/cost-analyzer --version 2.0.2 \
--namespace kubecost --create-namespace \
-f https://raw.githubusercontent.com/kubecost/cost-analyzer-helm-chart/develop/cost-analyzer/values-eks-cost-monitoring.yaml
左右滑动查看完整示意
2.查看安装结果。
kubectl get svc -n kubecost
3.查看UI页面:对应kubecost-cost-analyzer服务。
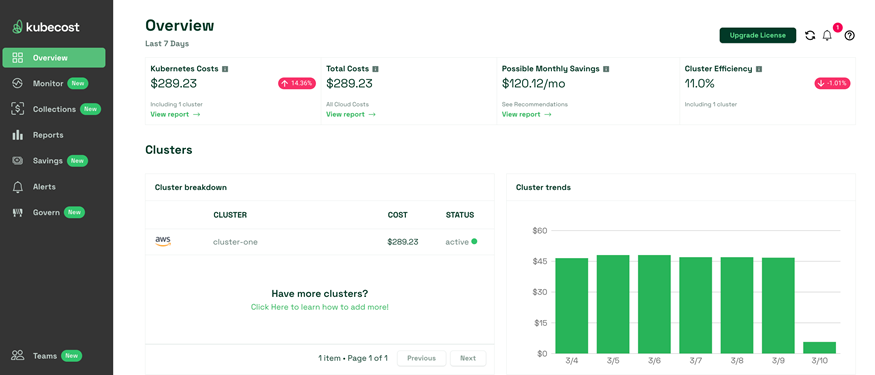
安装Prometheus和Grafana
1.添加并更新helm repo。
helm repo add prometheus-community https://prometheus-community.github.io/
helm-chartshelm repo update
左右滑动查看完整示意
2.安装Prometheus Stack。
# 1. 创建命名空间 - monitoring
kubectl create ns monitoring
# 2. 安装prometheus stack
helm install eks-kube-prometheus-stack prometheus-community/kube-prometheus-stack -n monitoring
左右滑动查看完整示意
3.查看安装情况。
kubectl get svc -n monitoring
4.查看UI页面。
- Prometheus。
- Grafana。
安装Loki
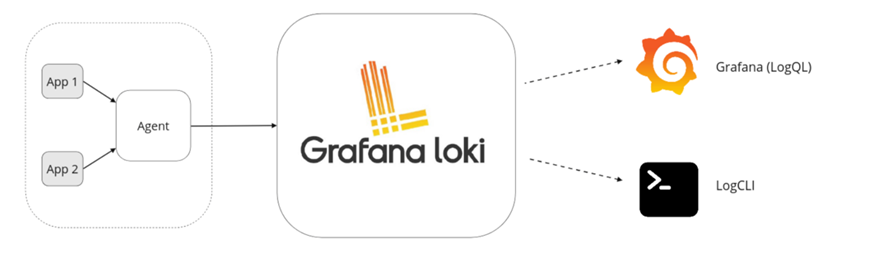
1.Loki架构如下,可以理解为类Prometheus,只不过存储的是日志而不是指标,Loki非常轻量级且适配K8s,数据可以存储到Amazon S3实现存算分离架构。
2.添加并更新helm repo。
helm repo add grafana https://grafana.github.io/
helm-chartshelm repo update
左右滑动查看完整示意
3.创建配置文件loki-custom-values.yaml,示例如下,可以根据具体情况进行配置。

左右滑动查看完整示意
4.安装Loki,此处选择安装5.42.2版本。
helm upgrade loki --values loki-custom-values.yaml --namespace loki grafana/loki --version 5.42.2
左右滑动查看完整示意
5.安装Promtail。
helm install promtail --namespace loki grafana/promtail
左右滑动查看完整示意
6.登录Grafana查看应用日志,下图是访问应用网关时打印的日志。
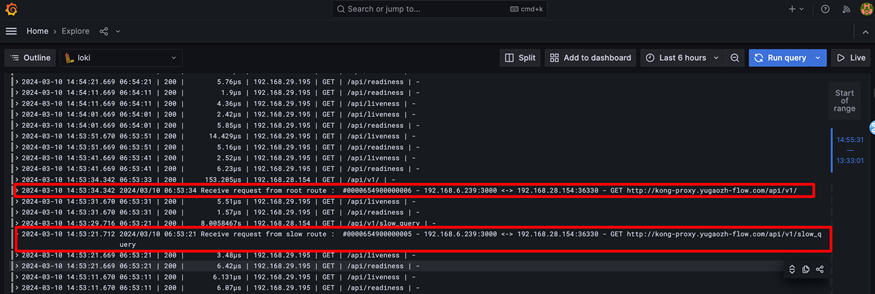
准备数据面环境
安装Kong
1.安装Gateway和GatewaClass。
- 配置文件–gateway.yaml。

左右滑动查看完整示意
- 安装命令。
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.0.0/standard-install.yaml
kubectl apply -f gateway.yaml
左右滑动查看完整示意
2.添加并更新helm repo。
helm repo add kong https://charts.konghq.com
helm repo update
左右滑动查看完整示意
3.安装Kong。
helm install kong kong/ingress. -n kong --create-namespace
左右滑动查看完整示意
部署服务网格
1.添加helm repo并更新。
helm repo add istio https://istio-release.storage.googleapis.com/charts
helm repo update
左右滑动查看完整示意
kubectl create namespace istio-system
左右滑动查看完整示意
3.安装istio-base。
helm install istio-base istio/base -n istio-system --set defaultRevision=default
左右滑动查看完整示意
4.安装istio discovery。
helm install istiod istio/istiod -n istio-system --wait
左右滑动查看完整示意
5.安装ingress gateway。
- 配置文件ingressgateway.yaml。
service:
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "ip"
service.beta.kubernetes.io/aws-load-balancer-scheme: "internet-facing"
service.beta.kubernetes.io/aws-load-balancer-attributes: "load_balancing.cross_zone.enabled=true"
左右滑动查看完整示意
- 安装命令。
helm install istio-ingressgateway istio/gateway -n istio-system -f ingressgateway.yaml
左右滑动查看完整示意
6.安装istio对应的add-on。
for ADDON in kiali jaeger prometheus grafana
do
ADDON_URL="https://raw.githubusercontent.com/istio/istio/release-1.20/samples/addons/$ADDON.yaml"
kubectl apply -f $ADDON_URL
done
左右滑动查看完整示意
7.使用Kiali查看部署的应用:此处部署的Service仅作演示目的。
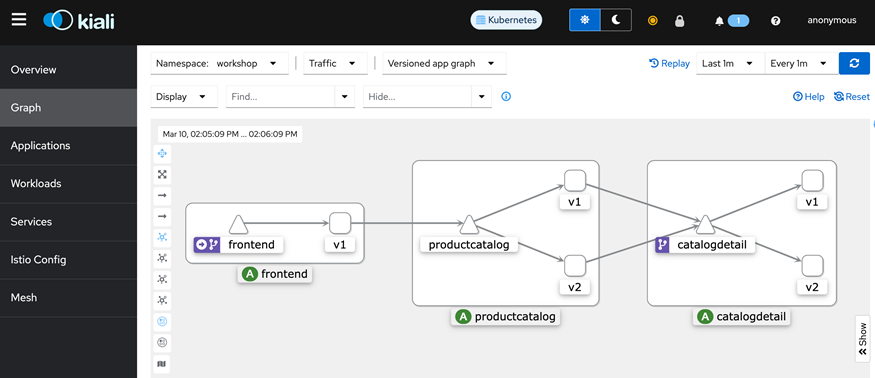
部署应用网关
1.应用官方是使用Fiber框架、Go语言开发的应用网关,项目github(后续集成到Amazon-examples中并开源)。
2.应用网关可以响应客户端请求、适配后端算力单元(例如Text Generation WebUI+Nvidia GPU)组成的大语言模型推理框架、记录API调用日志和指标并以此实现算力单元的自动扩缩。
3.下载代码后编译镜像。
./scripts/build_and_push.sh
4.部署Service,需要根据情况更改Image。
- 配置文件service-text-generation-webui-proxy.yaml。


左右滑动查看完整示意
- 部署命令。
kubectl apply -f service-text-generation-webui-proxy.yaml
左右滑动查看完整示意
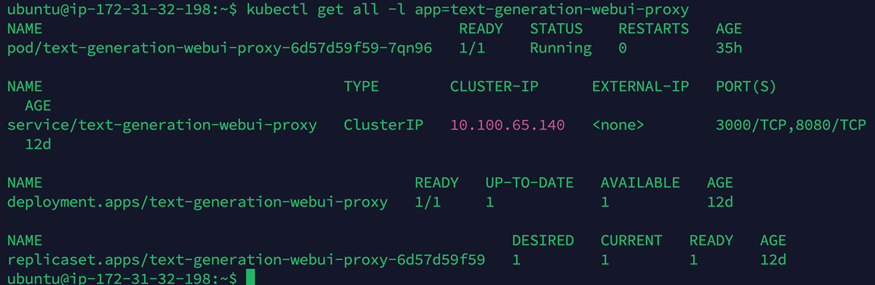
5.查看部署的Service。
kubectl get all -l app=text-generation-webui-proxy
左右滑动查看完整示意
6.配置Kong Route,使得Kong接收到的请求转发给该应用网关达到暴露服务的目的。
- 配置文件kong-route-ingress.yaml。

左右滑动查看完整示意
- 命令。
kubectl apply -f kong-route-ingress.yaml
部署Text Generation WebUI
1.Text Generation WebUI是最近比较热门的开源项目,目标是LLM界的SD-WebUI ,目前部分客户已经使用其作为LLM的推理框架。
2.原生Text Generation WebUI不支持K8s和Amazon Neuron芯片进行部署。因此该方案针对上述两个方面进行了优化,使得Text Generation WebUI可以部署于K8s且对部分支持的模型可以使用Amazon Neuron芯片作为推理引擎。
3.Amazon Neuron芯片支持,核心修改如下:
- modules和models.py加入neuron_loader()以支持使用Amazon Neuron芯片加载模型。
def neuron_loader(model_name):
from transformers_neuronx.llama.model import LlamaForSampling
path_to_model = Path(f'{shared.args.model_dir}/{model_name}/model')
path_to_neuron = Path(f'{shared.args.model_dir}/{model_name}/neuron_artifacts')
path_to_tokenizer = Path(f'{shared.args.model_dir}/{model_name}/tokenizer')
model = LlamaForSampling.from_pretrained(path_to_model, batch_size=1, tp_degree=12, amp='f16')
model.load(path_to_neuron) # Load the compiled Neuron artifacts
model.to_neuron() # will skip compile
tokenizer = AutoTokenizer.from_pretrained(path_to_tokenizer)
return model, tokenizer
def load_model(model_name, loader=None):
logger.info(f"Loading {model_name}")
t0 = time.time()
shared.is_seq2seq = False
shared.model_name = model_name
load_func_map = {
'Transformers': huggingface_loader,
'AutoGPTQ': AutoGPTQ_loader,
'GPTQ-for-LLaMa': GPTQ_loader,
'llama.cpp': llamacpp_loader,
'llamacpp_HF': llamacpp_HF_loader,
'RWKV': RWKV_loader,
'ExLlama': ExLlama_loader,
'ExLlama_HF': ExLlama_HF_loader,
'ExLlamav2': ExLlamav2_loader,
'ExLlamav2_HF': ExLlamav2_HF_loader,
'ctransformers': ctransformers_loader,
'AutoAWQ': AutoAWQ_loader,
'QuIP#': QuipSharp_loader,
'HQQ': HQQ_loader,
'Neuron': neuron_loader
}
左右滑动查看完整示意
- modules和models_setting.py,修改模型设置以支持采用neuron_loader进行模型加载。
def infer_loader(model_name, model_settings):
path_to_model = Path(f'{shared.args.model_dir}/{model_name}')
if not path_to_model.exists():
loader = None
elif (path_to_model / 'quantize_config.json').exists() or ('wbits' in model_settings and type(model_settings['wbits']) is int and model_settings['wbits'] > 0):
loader = 'ExLlama_HF'
elif (path_to_model / 'quant_config.json').exists() or re.match(r'.*-awq', model_name.lower()):
loader = 'AutoAWQ'
elif len(list(path_to_model.glob('*.gguf'))) > 0:
loader = 'llama.cpp'
elif re.match(r'.*\.gguf', model_name.lower()):
loader = 'llama.cpp'
elif re.match(r'.*rwkv.*\.pth', model_name.lower()):
loader = 'RWKV'
elif re.match(r'.*exl2', model_name.lower()):
loader = 'ExLlamav2_HF'
elif re.match(r'.*-hqq', model_name.lower()):
return 'HQQ'
elif re.match(r'.*-neuron', model_name.lower()):
return 'Neuron'
else:
loader = 'Transformers'
return loader
左右滑动查看完整示意
- modules和text_generation.py,修改encode()函数,不使用CUDA device加载。
def encode(prompt, add_special_tokens=True, add_bos_token=True, truncation_length=None):
...
return input_ids
左右滑动查看完整示意
- modules和text_generation.py,修改generate_reply_HF()函数,使用Amazon Neuron SDK进行模型推理。
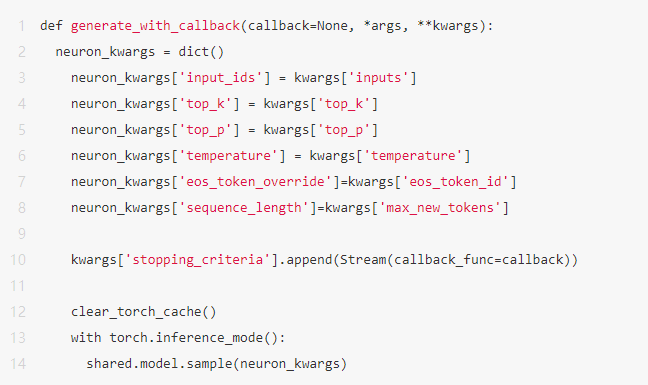
左右滑动查看完整示意
4.K8s支持。
- 生成.dockerfile文件。
# BUILDERFROM
nvidia/cuda:12.1.1-devel-ubuntu22.04 as builder
WORKDIR /builder
ARG TORCH_CUDA_ARCH_LIST="${TORCH_CUDA_ARCH_LIST:-3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX}"
ARG BUILD_EXTENSIONS="${BUILD_EXTENSIONS:-}"
ARG APP_UID="${APP_UID:-6972}"
ARG APP_GID="${APP_GID:-6972}"
RUN apt update && \
apt install --no-install-recommends -y git vim build-essential python3-dev pip bash curl net-tools && \
rm -rf /var/lib/apt/lists/*
WORKDIR /home/app/
# RUN git clone https://github.com/oobabooga/text-generation-webui.git
COPY . /home/app/text-generation-webui
WORKDIR /home/app/text-generation-webui
RUN GPU_CHOICE=A USE_CUDA118=FALSE LAUNCH_AFTER_INSTALL=FALSE INSTALL_EXTENSIONS=TRUE ./start_linux.sh --verbose
# COPY CMD_FLAGS.txt /home/app/text-generation-webui/
EXPOSE ${CONTAINER_PORT:-7860} ${CONTAINER_API_PORT:-5000} ${CONTAINER_API_STREAM_PORT:-5005}
WORKDIR /home/app/text-generation-webui
# set umask to ensure group read / write at runtime
CMD umask 0002 && export HOME=/home/app/text-generation-webui && ./start_linux.sh
左右滑动查看完整示意
- 生成镜像并上传–bash脚本。
#!/usr/bin/env bash
aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 763104351884.dkr.ecr.us-west-2.amazonaws.com
# This script shows how to build the Docker image and push it to ECR to be ready for use
# by SageMaker.
# The argument to this script is the image name. This will be used as the image on the local
# machine and combined with the account and region to form the repository name for ECR.
# The name of our algorithmalgorithm_name=text-generation-webui
account=$(aws sts get-caller-identity --query Account --output text)
# Get the region defined in the current configuration (default to us-west-2 if none defined)
region=$(aws configure get region)
region=${region:-us-west-2}
fullname="${account}.dkr.ecr.${region}.amazonaws.com/${algorithm_name}:latest"
# If the repository doesn't exist in ECR, create it.
aws ecr describe-repositories --repository-names "${algorithm_name}" > /dev/null 2>&1
if [ $? -ne 0 ]
then
aws ecr create-repository --repository-name "${algorithm_name}" > /dev/null
fi
# Get the login command from ECR and execute it directly
aws ecr get-login-password --region ${region}|docker login --username AWS --password-stdin ${fullname}
# Build the docker image locally with the image name and then push it to ECR
# with the full name.
docker build -t ${algorithm_name} .
docker tag ${algorithm_name} ${fullname}
docker push ${fullname}
左右滑动查看完整示意
5.部署服务。
-
配置文件(service-text-generation-webui.yaml):根据具体情况修改Image和Amazon EFS Claim。



-
将模型文件下载并拷贝到Amazon EFS对应路径,例如截图中是“TheBloke_Llama-2-7B-Chat-AWQ”模型。
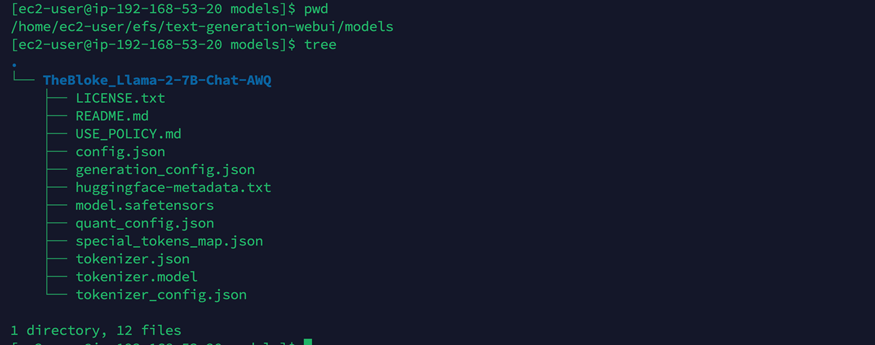
- 部署命令。
kubectl apply -f service-text-generation-webui.yaml
左右滑动查看完整示意
集群自动扩缩
1.大语言模型推理的自动扩缩是一个比较复杂的问题,需要考虑方方面面的因素,包括但不限于底层的算力机类型、模型的大小、模型是否量化、输入和输出Token数量、推理的参数设定以及特定框架的参数等,因此设计一个适配各种场景的完美方案非常困难。比较合理的扩缩指标信息包括“单位时间请求数”、“请求响应时长”等。
2.本方案中采用“单位时间请求数”作为Kubernetes deployment扩缩的依据,下面以Text Generation Inference为例讲解,配置文件如下。由于只是作为展示,因此设置的扩展指标非常敏感–每2秒有一个请求就会扩展。生产中应根据实际情况配置。
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2
metadata:
name: llama2-13b-chat-awq
namespace: tgi
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tgi-engine-llama2-13b-chat-awq
minReplicas: 1
maxReplicas: 3
metrics:
# use a "Pods" metric, which takes the average of the
# given metric across all pods controlled by the autoscaling target
- type: Pods
pods:
metric:
name: tgi_request_per_second
# target 500 milli-requests per second,
# which is 1 request every two seconds
target:
type: Value
averageValue: 500m
behavior: # 这里是重点
scaleDown:
stabilizationWindowSeconds: 300 # 需要缩容时,先观察5分钟,如果一直持续需要缩容才执行缩容
policies:
- type: Percent
value: 100 # 允许全部缩掉
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0 # 需要扩容时,立即扩容
policies:
- type: Percent
value: 100
periodSeconds: 15 # 每15s最大允许扩容当前1倍数量的Pod
- type: Pods
value: 4
periodSeconds: 15 # 每15s最大允许扩容 4 个 Pod
selectPolicy: Max # 使用以上两种扩容策略中算出来扩容Pod数量最大的
左右滑动查看完整示意
3.查看相关Deployment初始配置–此时没有任何请求,初始值为0。

4.当压力增加,自动扩展deploy的pod数量,同时通过Karpenter出发点集群节点的扩展。
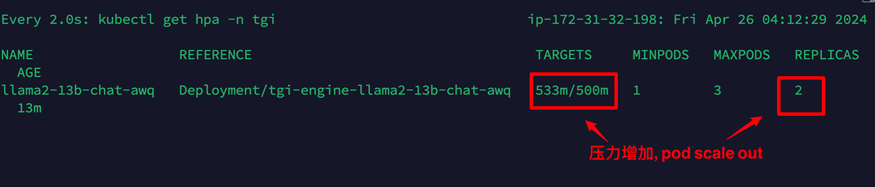
5.当压力下降持续5分钟后,pod自动进行收缩,同时通过Karpenter触发集群节点的收缩。

方案验证
1.目前方案提供了HTTP接口( OpenAI-Compatible )以便于调用LLM推理能力。
2.调用命令v1/completions/接口。
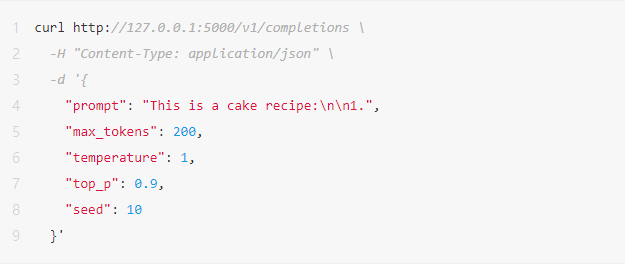
左右滑动查看完整示意
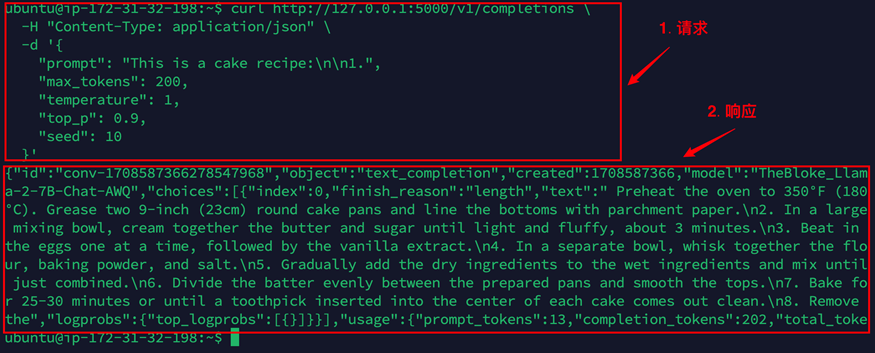
3.调用截图。
总结
通过这个基于亚马逊云科技云原生服务的解决方案,我们为企业在自有环境中平滑部署和高效运行大型语言模型提供了一种创新的实践方式。该解决方案遵循云原生理念,融合了多种亚马逊云科技基础服务和开源工具,构建了一个功能完备、灵活可扩展、易于运维的LLM部署运行平台。
在技术层面,我们将开源LLM框架Text Generation WebUI、vLLM和Text Generation Inference部署于Amazon EKS集群实现LLM的推理,同时对开源LLM框架Text Generation WebUI进行了多方位的创新改造,使其能够在Amazon EKS集群中稳定运行,同时充分利用Amazon Neuron加速芯片的算力,极大提升了推理性能。另外,我们自研的统一LLM应用网关层为服务注入了高可用、负载均衡等生产级能力,形成了一个端到端的LLM部署和运维体系,显著降低了企业应用LLM能力的复杂度和总体拥有成本。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









